 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Existence and Behaviour of Secondary Attention Sinks
Dec 22, 2025Attention sinks are tokens, often the beginning-of-sequence (BOS) token, that receive disproportionately high attention despite limited semantic relevance. In this work, we identify a class of attention sinks, which we term secondary sinks, that differ fundamentally from the sinks studied in prior works, which we term primary sinks. While prior works have identified that tokens other than BOS can sometimes become sinks, they were found to exhibit properties analogous to the BOS token. Specifically, they emerge at the same layer, persist throughout the network and draw a large amount of attention mass. Whereas, we find the existence of secondary sinks that arise primarily in middle layers and can persist for a variable number of layers, and draw a smaller, but still significant, amount of attention mass. Through extensive experiments across 11 model families, we analyze where these secondary sinks appear, their properties, how they are formed, and their impact on the attention mechanism. Specifically, we show that: (1) these sinks are formed by specific middle-layer MLP modules; these MLPs map token representations to vectors that align with the direction of the primary sink of that layer. (2) The $\ell_2$-norm of these vectors determines the sink score of the secondary sink, and also the number of layers it lasts for, thereby leading to different impacts on the attention mechanisms accordingly. (3) The primary sink weakens in middle layers, coinciding with the emergence of secondary sinks. We observe that in larger-scale models, the location and lifetime of the sinks, together referred to as sink levels, appear in a more deterministic and frequent manner. Specifically, we identify three sink levels in QwQ-32B and six levels in Qwen3-14B.
A3 : an Analytical Low-Rank Approximation Framework for Attention
May 19, 2025Large language models have demonstrated remarkable performance; however, their massive parameter counts make deployment highly expensive. Low-rank approximation offers a promising compression solution, yet existing approaches have two main limitations: (1) They focus on minimizing the output error of individual linear layers, without considering the architectural characteristics of Transformers, and (2) they decompose a large weight matrix into two small low-rank matrices. Consequently, these methods often fall short compared to other compression techniques like pruning and quantization, and introduce runtime overhead such as the extra GEMM kernel launches for decomposed small matrices. To address these limitations, we propose $\tt A^\tt 3$, a post-training low-rank approximation framework. $\tt A^\tt 3$ splits a Transformer layer into three functional components, namely $\tt QK$, $\tt OV$, and $\tt MLP$. For each component, $\tt A^\tt 3$ provides an analytical solution that reduces the hidden dimension size inside each component while minimizing the component's functional loss ($\it i.e.$, error in attention scores, attention outputs, and MLP outputs). This approach directly reduces model sizes, KV cache sizes, and FLOPs without introducing any runtime overheads. In addition, it provides a new narrative in advancing the optimization problem from singular linear layer loss optimization toward improved end-to-end performance. Through extensive experiments, we show that $\tt A^\tt 3$ maintains superior performance compared to SoTAs. For example, under the same reduction budget in computation and memory, our low-rank approximated LLaMA 3.1-70B achieves a perplexity of 4.69 on WikiText-2, outperforming the previous SoTA's 7.87 by 3.18. We also demonstrate the versatility of $\tt A^\tt 3$, including KV cache compression, quantization, and mixed-rank assignments for enhanced performance.
QERA: an Analytical Framework for Quantization Error Reconstruction
Oct 08, 2024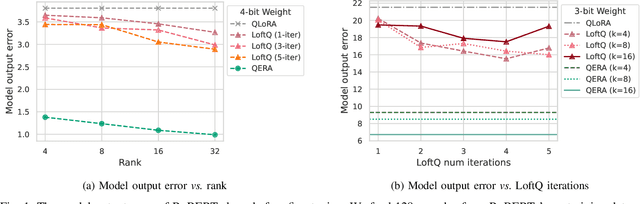


he growing number of parameters and computational demands of large language models (LLMs) present significant challenges for their efficient deployment. Recently, there is an increasing interest in quantizing weights to extremely low precision while offsetting the resulting error with low-rank, high-precision error reconstruction terms. The combination of quantization and low-rank approximation is now popular in both adapter-based, parameter-efficient fine-tuning methods such as LoftQ and low-precision inference techniques including ZeroQuant-V2. Usually, the low-rank terms are calculated via the singular value decomposition (SVD) of the weight quantization error, minimizing the Frobenius and spectral norms of the weight approximation error. Recent methods like LQ-LoRA and LQER introduced hand-crafted heuristics to minimize errors in layer outputs (activations) rather than weights, resulting improved quantization results. However, these heuristic methods lack an analytical solution to guide the design of quantization error reconstruction terms. In this paper, we revisit this problem and formulate an analytical framework, named Quantization Error Reconstruction Analysis (QERA), and offer a closed-form solution to the problem. We show QERA benefits both existing low-precision fine-tuning and inference methods -- QERA achieves a fine-tuned accuracy gain of $\Delta_{\text{acc}}$ = 6.05% of 2-bit RoBERTa-base on GLUE compared to LoftQ; and obtains $\Delta_{\text{acc}}$ = 2.97% higher post-training quantization accuracy of 4-bit Llama-3.1-70B on average than ZeroQuant-V2 and $\Delta_{\text{ppl}}$ = - 0.28 lower perplexity on WikiText2 than LQER.