 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMURAL: An Unsupervised Random Forest-Based Embedding for Electronic Health Record Data
Nov 19, 2021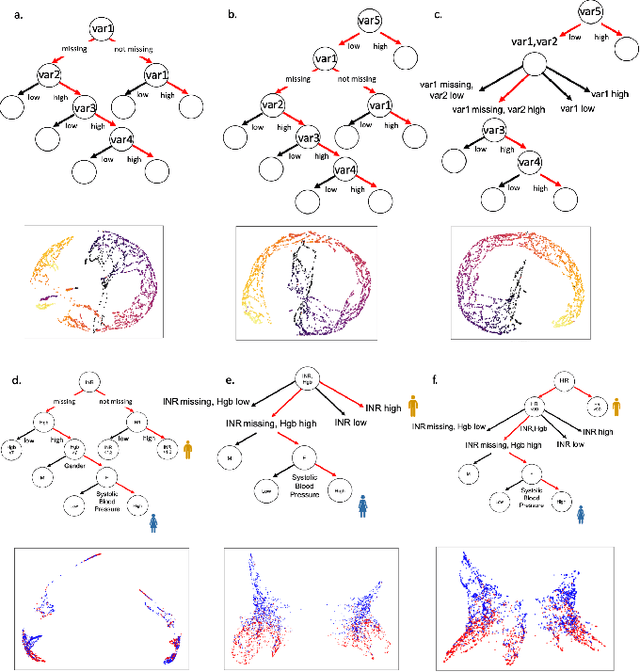
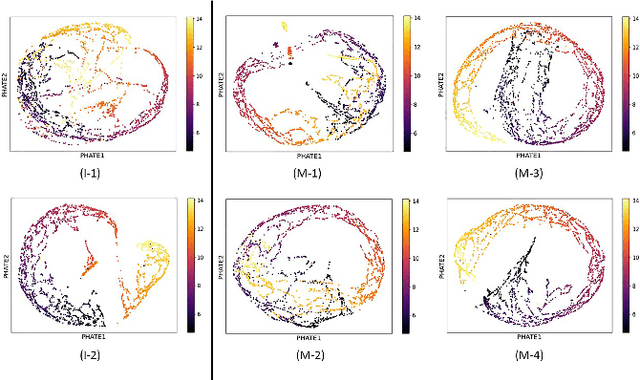
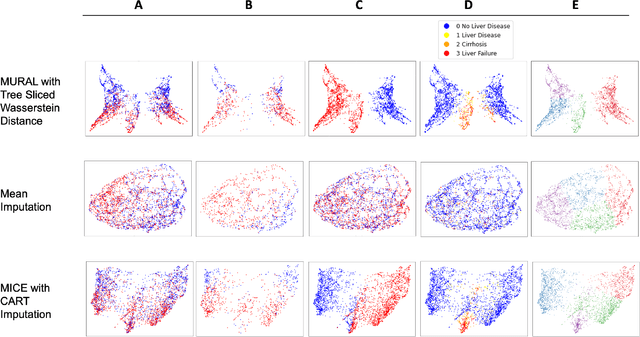

A major challenge in embedding or visualizing clinical patient data is the heterogeneity of variable types including continuous lab values, categorical diagnostic codes, as well as missing or incomplete data. In particular, in EHR data, some variables are {\em missing not at random (MNAR)} but deliberately not collected and thus are a source of information. For example, lab tests may be deemed necessary for some patients on the basis of suspected diagnosis, but not for others. Here we present the MURAL forest -- an unsupervised random forest for representing data with disparate variable types (e.g., categorical, continuous, MNAR). MURAL forests consist of a set of decision trees where node-splitting variables are chosen at random, such that the marginal entropy of all other variables is minimized by the split. This allows us to also split on MNAR variables and discrete variables in a way that is consistent with the continuous variables. The end goal is to learn the MURAL embedding of patients using average tree distances between those patients. These distances can be fed to nonlinear dimensionality reduction method like PHATE to derive visualizable embeddings. While such methods are ubiquitous in continuous-valued datasets (like single cell RNA-sequencing) they have not been used extensively in mixed variable data. We showcase the use of our method on one artificial and two clinical datasets. We show that using our approach, we can visualize and classify data more accurately than competing approaches. Finally, we show that MURAL can also be used to compare cohorts of patients via the recently proposed tree-sliced Wasserstein distances.
Making Logic Learnable With Neural Networks
Feb 18, 2020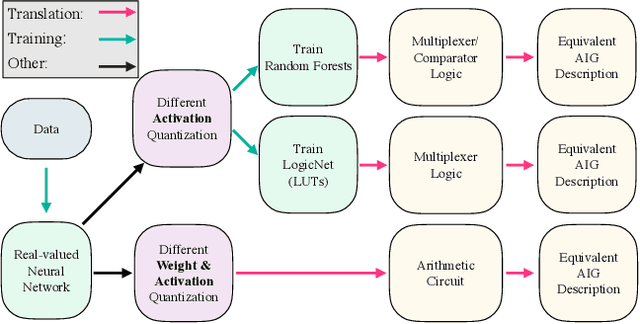
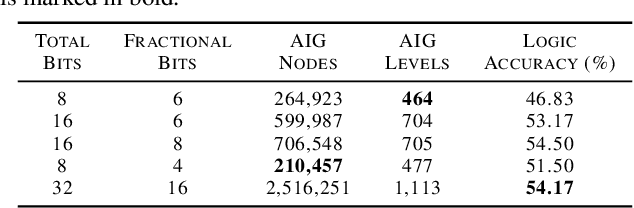

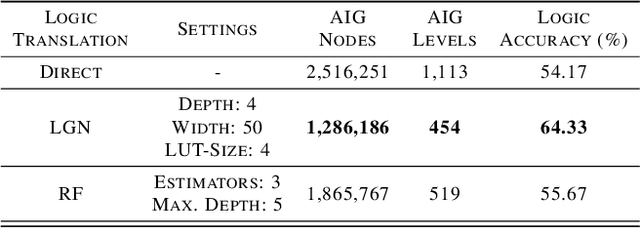
While neural networks are good at learning unspecified functions from training samples, they cannot be directly implemented in hardware and are often not interpretable or formally verifiable. On the other hand, logic circuits are implementable, verifiable, and interpretable but are not able to learn from training data in a generalizable way. We propose a novel logic learning pipeline that combines the advantages of neural networks and logic circuits. Our pipeline first trains a neural network on a classification task, and then translates this, first to random forests or look-up tables, and then to AND-Inverter logic. We show that our pipeline maintains greater accuracy than naive translations to logic, and minimizes the logic such that it is more interpretable and has decreased hardware cost. We show the utility of our pipeline on a network that is trained on biomedical data from patients presenting with gastrointestinal bleeding with the prediction task of determining if patients need immediate hospital-based intervention. This approach could be applied to patient care to provide risk stratification and guide clinical decision-making.