 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Training of Liquid State Machines
Feb 06, 2023



Spiking Neural Networks (SNNs) emerged as a promising solution in the field of Artificial Neural Networks (ANNs), attracting the attention of researchers due to their ability to mimic the human brain and process complex information with remarkable speed and accuracy. This research aimed to optimise the training process of Liquid State Machines (LSMs), a recurrent architecture of SNNs, by identifying the most effective weight range to be assigned in SNN to achieve the least difference between desired and actual output. The experimental results showed that by using spike metrics and a range of weights, the desired output and the actual output of spiking neurons could be effectively optimised, leading to improved performance of SNNs. The results were tested and confirmed using three different weight initialisation approaches, with the best results obtained using the Barabasi-Albert random graph method.
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016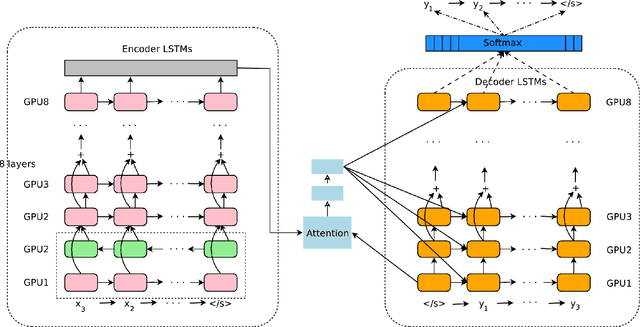

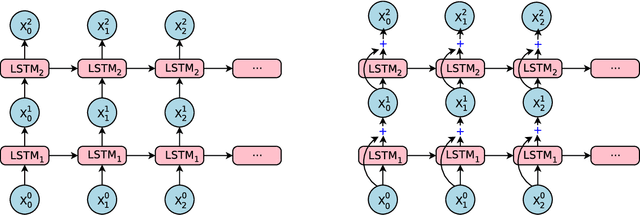
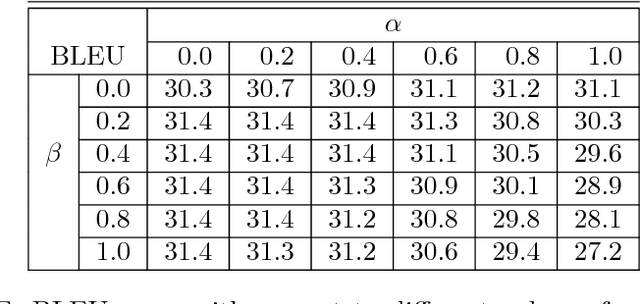
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.