 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterizing Branch-and-Bound Search Trees to Learn Branching Policies
Feb 12, 2020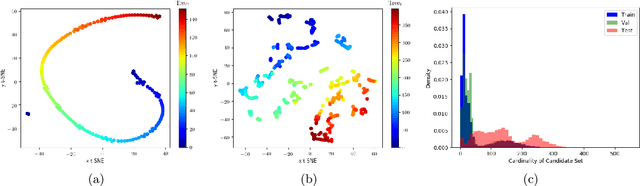



Branch and Bound (B&B) is the exact tree search method typically used to solve Mixed-Integer Linear Programming problems (MILPs). Learning branching policies for MILP has become an active research area, with most works proposing to imitate the strong branching rule and specialize it to distinct classes of problems. We aim instead at learning a policy that generalizes across heterogeneous MILPs: our main hypothesis is that parameterizing the state of the B&B search tree can significantly aid this type of generalization. We propose a novel imitation learning framework, and introduce new input features and architectures to represent branching. Experiments on MILP benchmark instances clearly show the advantages of incorporating to a baseline model an explicit parameterization of the state of the search tree to modulate the branching decisions. The resulting policy reaches higher accuracy than the baseline, and on average explores smaller B&B trees, while effectively allowing generalization to generic unseen instances.
Compositional generalization in a deep seq2seq model by separating syntax and semantics
May 23, 2019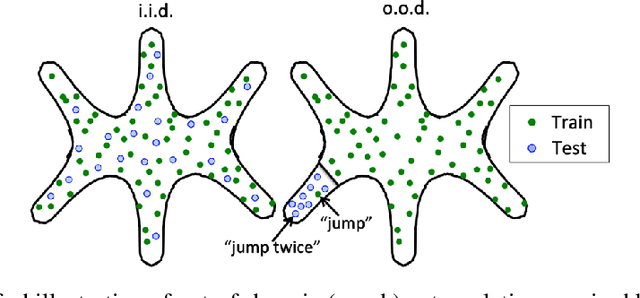
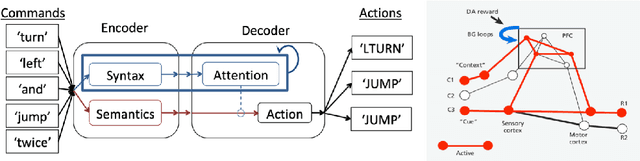


Standard methods in deep learning for natural language processing fail to capture the compositional structure of human language that allows for systematic generalization outside of the training distribution. However, human learners readily generalize in this way, e.g. by applying known grammatical rules to novel words. Inspired by work in neuroscience suggesting separate brain systems for syntactic and semantic processing, we implement a modification to standard approaches in neural machine translation, imposing an analogous separation. The novel model, which we call Syntactic Attention, substantially outperforms standard methods in deep learning on the SCAN dataset, a compositional generalization task, without any hand-engineered features or additional supervision. Our work suggests that separating syntactic from semantic learning may be a useful heuristic for capturing compositional structure.
Modularity Matters: Learning Invariant Relational Reasoning Tasks
Jun 18, 2018


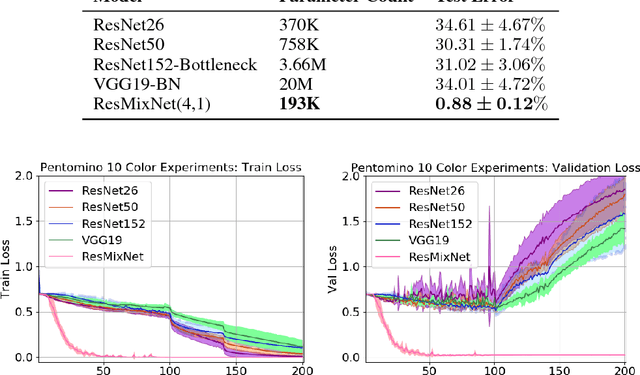
We focus on two supervised visual reasoning tasks whose labels encode a semantic relational rule between two or more objects in an image: the MNIST Parity task and the colorized Pentomino task. The objects in the images undergo random translation, scaling, rotation and coloring transformations. Thus these tasks involve invariant relational reasoning. We report uneven performance of various deep CNN models on these two tasks. For the MNIST Parity task, we report that the VGG19 model soundly outperforms a family of ResNet models. Moreover, the family of ResNet models exhibits a general sensitivity to random initialization for the MNIST Parity task. For the colorized Pentomino task, now both the VGG19 and ResNet models exhibit sluggish optimization and very poor test generalization, hovering around 30% test error. The CNN we tested all learn hierarchies of fully distributed features and thus encode the distributed representation prior. We are motivated by a hypothesis from cognitive neuroscience which posits that the human visual cortex is modularized, and this allows the visual cortex to learn higher order invariances. To this end, we consider a modularized variant of the ResNet model, referred to as a Residual Mixture Network (ResMixNet) which employs a mixture-of-experts architecture to interleave distributed representations with more specialized, modular representations. We show that very shallow ResMixNets are capable of learning each of the two tasks well, attaining less than 2% and 1% test error on the MNIST Parity and the colorized Pentomino tasks respectively. Most importantly, the ResMixNet models are extremely parameter efficient: generalizing better than various non-modular CNNs that have over 10x the number of parameters. These experimental results support the hypothesis that modularity is a robust prior for learning invariant relational reasoning.
Deep Neural Networks as 0-1 Mixed Integer Linear Programs: A Feasibility Study
Dec 17, 2017



Deep Neural Networks (DNNs) are very popular these days, and are the subject of a very intense investigation. A DNN is made by layers of internal units (or neurons), each of which computes an affine combination of the output of the units in the previous layer, applies a nonlinear operator, and outputs the corresponding value (also known as activation). A commonly-used nonlinear operator is the so-called rectified linear unit (ReLU), whose output is just the maximum between its input value and zero. In this (and other similar cases like max pooling, where the max operation involves more than one input value), one can model the DNN as a 0-1 Mixed Integer Linear Program (0-1 MILP) where the continuous variables correspond to the output values of each unit, and a binary variable is associated with each ReLU to model its yes/no nature. In this paper we discuss the peculiarity of this kind of 0-1 MILP models, and describe an effective bound-tightening technique intended to ease its solution. We also present possible applications of the 0-1 MILP model arising in feature visualization and in the construction of adversarial examples. Preliminary computational results are reported, aimed at investigating (on small DNNs) the computational performance of a state-of-the-art MILP solver when applied to a known test case, namely, hand-written digit recognition.
Measuring the tendency of CNNs to Learn Surface Statistical Regularities
Nov 30, 2017



Deep CNNs are known to exhibit the following peculiarity: on the one hand they generalize extremely well to a test set, while on the other hand they are extremely sensitive to so-called adversarial perturbations. The extreme sensitivity of high performance CNNs to adversarial examples casts serious doubt that these networks are learning high level abstractions in the dataset. We are concerned with the following question: How can a deep CNN that does not learn any high level semantics of the dataset manage to generalize so well? The goal of this article is to measure the tendency of CNNs to learn surface statistical regularities of the dataset. To this end, we use Fourier filtering to construct datasets which share the exact same high level abstractions but exhibit qualitatively different surface statistical regularities. For the SVHN and CIFAR-10 datasets, we present two Fourier filtered variants: a low frequency variant and a randomly filtered variant. Each of the Fourier filtering schemes is tuned to preserve the recognizability of the objects. Our main finding is that CNNs exhibit a tendency to latch onto the Fourier image statistics of the training dataset, sometimes exhibiting up to a 28% generalization gap across the various test sets. Moreover, we observe that significantly increasing the depth of a network has a very marginal impact on closing the aforementioned generalization gap. Thus we provide quantitative evidence supporting the hypothesis that deep CNNs tend to learn surface statistical regularities in the dataset rather than higher-level abstract concepts.
Learning Parameters for Weighted Matrix Completion via Empirical Estimation
Apr 02, 2015



Recently theoretical guarantees have been obtained for matrix completion in the non-uniform sampling regime. In particular, if the sampling distribution aligns with the underlying matrix's leverage scores, then with high probability nuclear norm minimization will exactly recover the low rank matrix. In this article, we analyze the scenario in which the non-uniform sampling distribution may or may not not align with the underlying matrix's leverage scores. Here we explore learning the parameters for weighted nuclear norm minimization in terms of the empirical sampling distribution. We provide a sufficiency condition for these learned weights which provide an exact recovery guarantee for weighted nuclear norm minimization. It has been established that a specific choice of weights in terms of the true sampling distribution not only allows for weighted nuclear norm minimization to exactly recover the low rank matrix, but also allows for a quantifiable relaxation in the exact recovery conditions. In this article we extend this quantifiable relaxation in exact recovery conditions for a specific choice of weights defined analogously in terms of the empirical distribution as opposed to the true sampling distribution. To accomplish this we employ a concentration of measure bound and a large deviation bound. We also present numerical evidence for the healthy robustness of the weighted nuclear norm minimization algorithm to the choice of empirically learned weights. These numerical experiments show that for a variety of easily computable empirical weights, weighted nuclear norm minimization outperforms unweighted nuclear norm minimization in the non-uniform sampling regime.