 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional generalization in a deep seq2seq model by separating syntax and semantics
Paper and Code
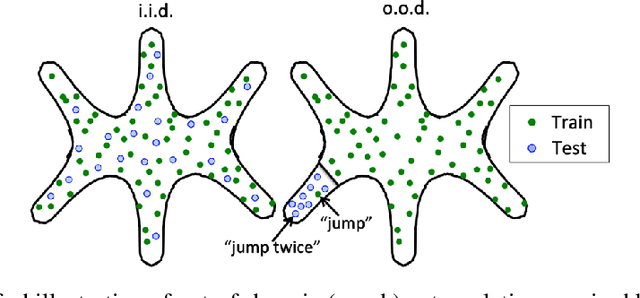
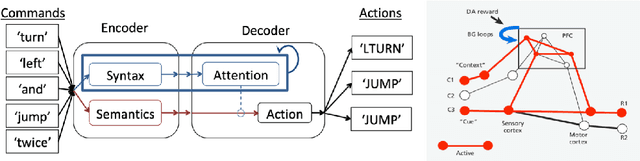


Standard methods in deep learning for natural language processing fail to capture the compositional structure of human language that allows for systematic generalization outside of the training distribution. However, human learners readily generalize in this way, e.g. by applying known grammatical rules to novel words. Inspired by work in neuroscience suggesting separate brain systems for syntactic and semantic processing, we implement a modification to standard approaches in neural machine translation, imposing an analogous separation. The novel model, which we call Syntactic Attention, substantially outperforms standard methods in deep learning on the SCAN dataset, a compositional generalization task, without any hand-engineered features or additional supervision. Our work suggests that separating syntactic from semantic learning may be a useful heuristic for capturing compositional structure.