 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularity Matters: Learning Invariant Relational Reasoning Tasks
Paper and Code
Jun 18, 2018


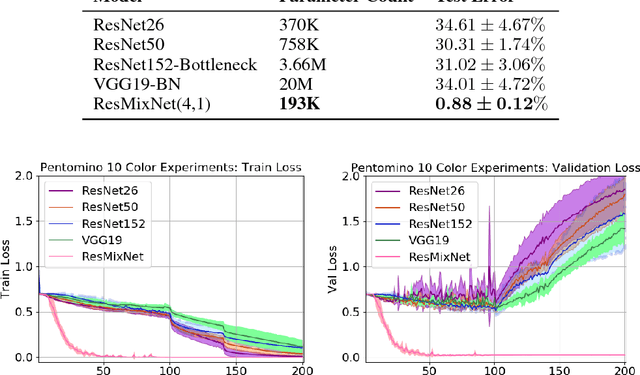
We focus on two supervised visual reasoning tasks whose labels encode a semantic relational rule between two or more objects in an image: the MNIST Parity task and the colorized Pentomino task. The objects in the images undergo random translation, scaling, rotation and coloring transformations. Thus these tasks involve invariant relational reasoning. We report uneven performance of various deep CNN models on these two tasks. For the MNIST Parity task, we report that the VGG19 model soundly outperforms a family of ResNet models. Moreover, the family of ResNet models exhibits a general sensitivity to random initialization for the MNIST Parity task. For the colorized Pentomino task, now both the VGG19 and ResNet models exhibit sluggish optimization and very poor test generalization, hovering around 30% test error. The CNN we tested all learn hierarchies of fully distributed features and thus encode the distributed representation prior. We are motivated by a hypothesis from cognitive neuroscience which posits that the human visual cortex is modularized, and this allows the visual cortex to learn higher order invariances. To this end, we consider a modularized variant of the ResNet model, referred to as a Residual Mixture Network (ResMixNet) which employs a mixture-of-experts architecture to interleave distributed representations with more specialized, modular representations. We show that very shallow ResMixNets are capable of learning each of the two tasks well, attaining less than 2% and 1% test error on the MNIST Parity and the colorized Pentomino tasks respectively. Most importantly, the ResMixNet models are extremely parameter efficient: generalizing better than various non-modular CNNs that have over 10x the number of parameters. These experimental results support the hypothesis that modularity is a robust prior for learning invariant relational reasoning.