 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Evaluation of Quantum Kernel Methods for Radar Micro-Doppler Classification on Noisy Intermediate-Scale Quantum (NISQ) Hardware
Jan 29, 2026This paper examines the application of a Quantum Support Vector Machine (QSVM) for radarbased aerial target classification using micro-Doppler signatures. Classical features are extracted and reduced via Principal Component Analysis (PCA) to enable efficient quantum encoding. The reduced feature vectors are embedded into a quantum kernel-induced feature space using a fully entangled ZZFeatureMap and classified using a kernel based QSVM. Performance is first evaluated on a quantum simulator and subsequently validated on NISQ-era superconducting quantum hardware, specifically the IBM Torino (133-qubit) and IBM Fez (156-qubit) processors. Experimental results demonstrate that the QSVM achieves competitive classification performance relative to classical SVM baselines while operating on substantially reduced feature dimensionality. Hardware experiments reveal the impact of noise and decoherence and measurement shot count on quantum kernel estimation, and further show improved stability and fidelity on newer Heron r2 architecture. This study provides a systematic comparison between simulator-based and hardware-based QSVM implementations and highlights both the feasibility and current limitations of deploying quantum kernel methods for practical radar signal classification tasks.
Fingerprinting Search Keywords over HTTPS at Scale
Aug 18, 2020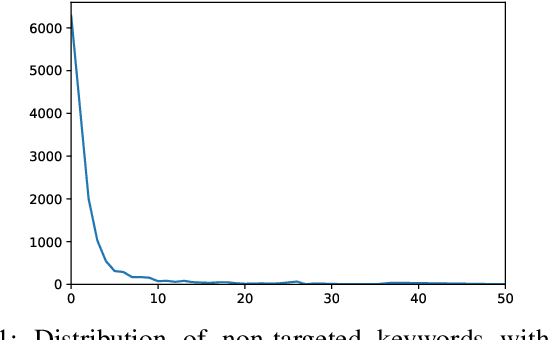
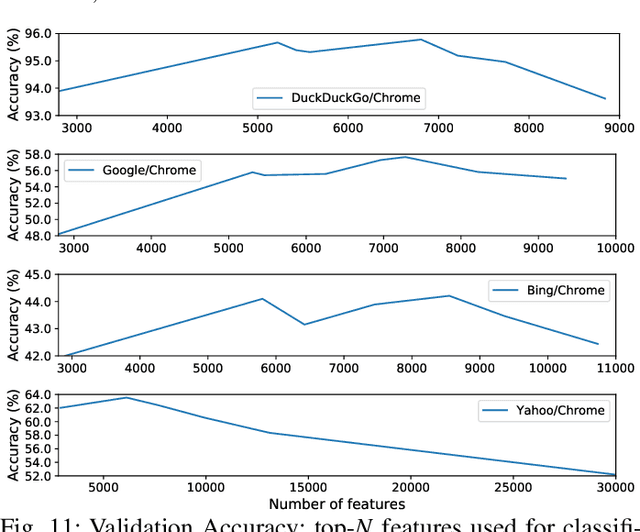
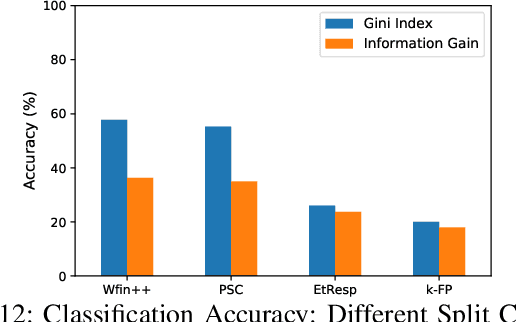
The possibility of fingerprinting the search keywords issued by a user on popular web search engines is a significant threat to user privacy. This threat has received surprisingly little attention in the network traffic analysis literature. In this work, we consider the problem of keyword fingerprinting of HTTPS traffic -- we study the impact of several factors, including client platform diversity, choice of search engine, feature sets as well as classification frameworks. We conduct both closed-world and open-world evaluations using nearly 4 million search queries collected over a period of three months. Our analysis reveals several insights into the threat of keyword fingerprinting in modern HTTPS traffic.
Spatial sensitivity analysis for urban land use prediction with physics-constrained conditional generative adversarial networks
Jul 22, 2019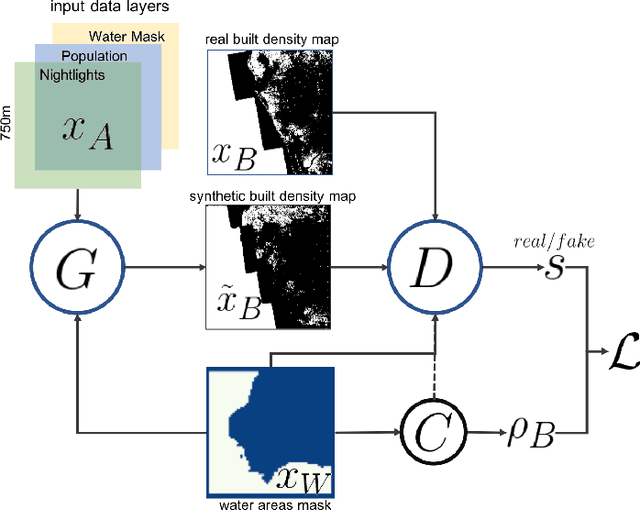
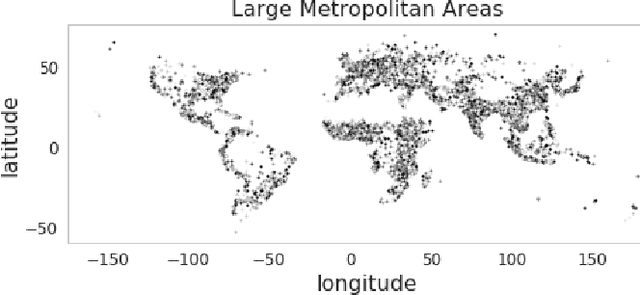
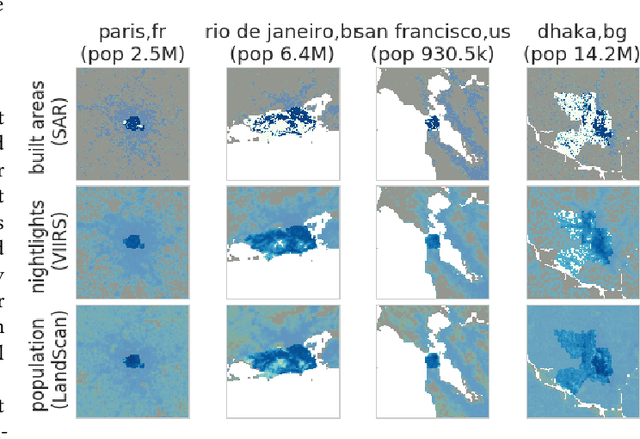
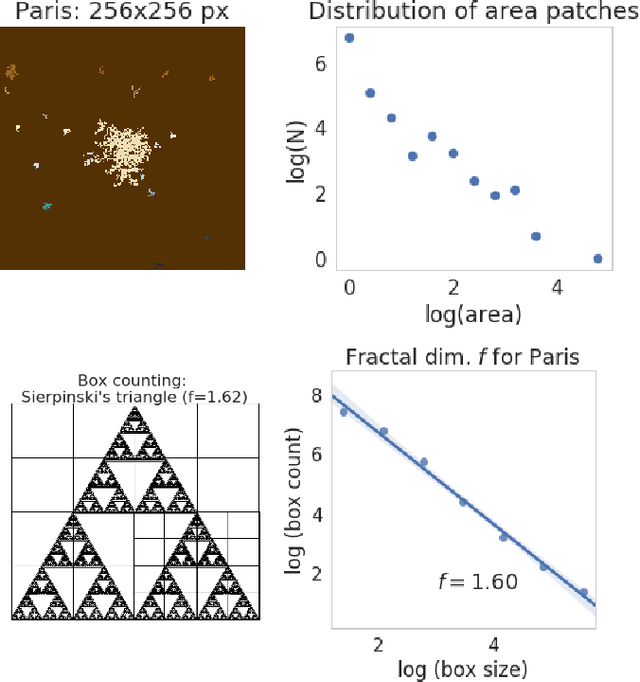
Accurately forecasting urban development and its environmental and climate impacts critically depends on realistic models of the spatial structure of the built environment, and of its dependence on key factors such as population and economic development. Scenario simulation and sensitivity analysis, i.e., predicting how changes in underlying factors at a given location affect urbanization outcomes at other locations, is currently not achievable at a large scale with traditional urban growth models, which are either too simplistic, or depend on detailed locally-collected socioeconomic data that is not available in most places. Here we develop a framework to estimate, purely from globally-available remote-sensing data and without parametric assumptions, the spatial sensitivity of the (\textit{static}) rate of change of urban sprawl to key macroeconomic development indicators. We formulate this spatial regression problem as an image-to-image translation task using conditional generative adversarial networks (GANs), where the gradients necessary for comparative static analysis are provided by the backpropagation algorithm used to train the model. This framework allows to naturally incorporate physical constraints, e.g., the inability to build over water bodies. To validate the spatial structure of model-generated built environment distributions, we use spatial statistics commonly used in urban form analysis. We apply our method to a novel dataset comprising of layers on the built environment, nightlighs measurements (a proxy for economic development and energy use), and population density for the world's most populous 15,000 cities.
Modeling urbanization patterns with generative adversarial networks
Jan 08, 2018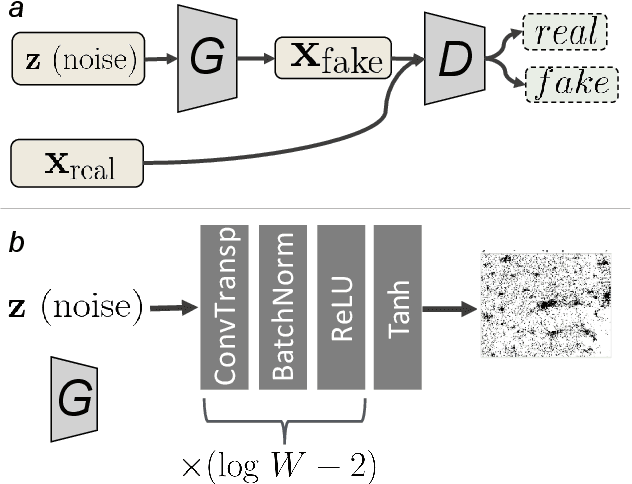
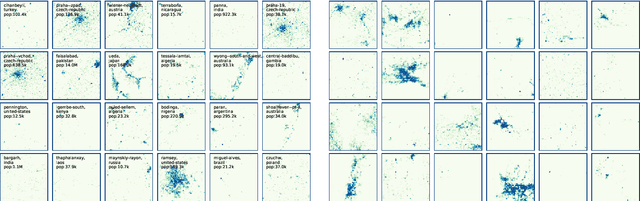
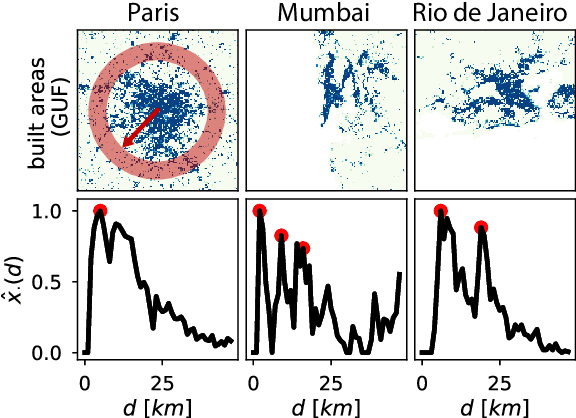

In this study we propose a new method to simulate hyper-realistic urban patterns using Generative Adversarial Networks trained with a global urban land-use inventory. We generated a synthetic urban "universe" that qualitatively reproduces the complex spatial organization observed in global urban patterns, while being able to quantitatively recover certain key high-level urban spatial metrics.
Using convolutional networks and satellite imagery to identify patterns in urban environments at a large scale
Sep 13, 2017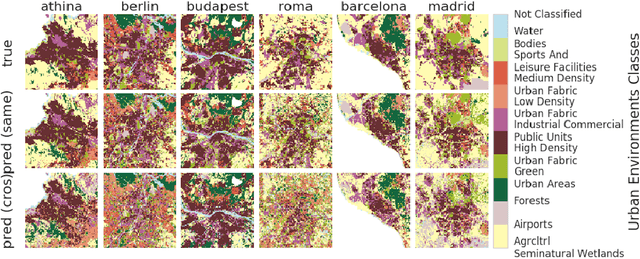
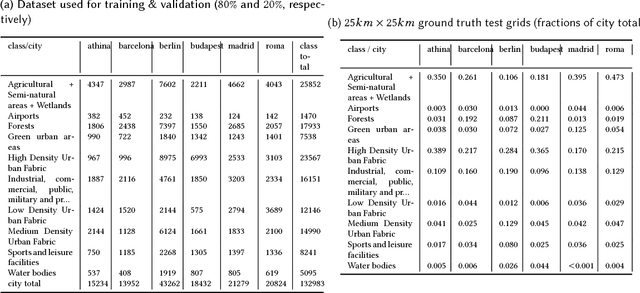
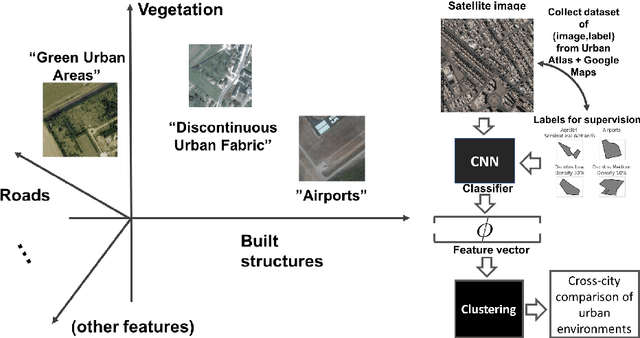

Urban planning applications (energy audits, investment, etc.) require an understanding of built infrastructure and its environment, i.e., both low-level, physical features (amount of vegetation, building area and geometry etc.), as well as higher-level concepts such as land use classes (which encode expert understanding of socio-economic end uses). This kind of data is expensive and labor-intensive to obtain, which limits its availability (particularly in developing countries). We analyze patterns in land use in urban neighborhoods using large-scale satellite imagery data (which is available worldwide from third-party providers) and state-of-the-art computer vision techniques based on deep convolutional neural networks. For supervision, given the limited availability of standard benchmarks for remote-sensing data, we obtain ground truth land use class labels carefully sampled from open-source surveys, in particular the Urban Atlas land classification dataset of $20$ land use classes across $~300$ European cities. We use this data to train and compare deep architectures which have recently shown good performance on standard computer vision tasks (image classification and segmentation), including on geospatial data. Furthermore, we show that the deep representations extracted from satellite imagery of urban environments can be used to compare neighborhoods across several cities. We make our dataset available for other machine learning researchers to use for remote-sensing applications.
Uncovering protein interaction in abstracts and text using a novel linear model and word proximity networks
Dec 04, 2008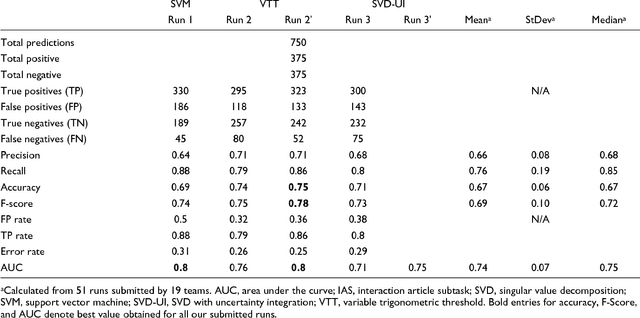
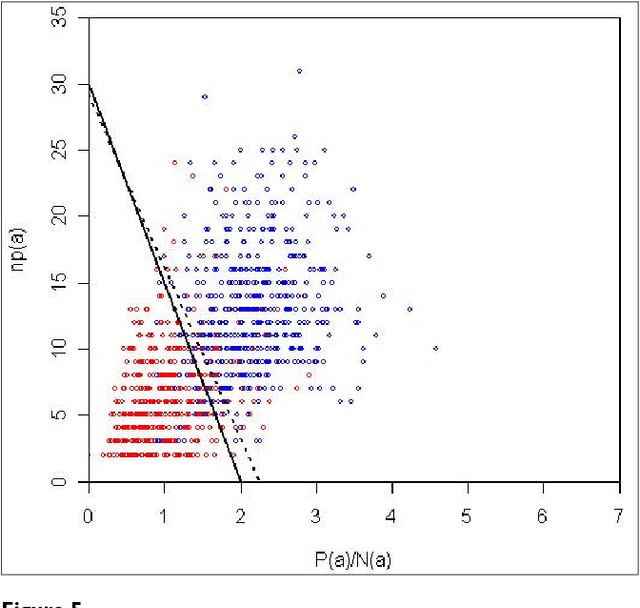
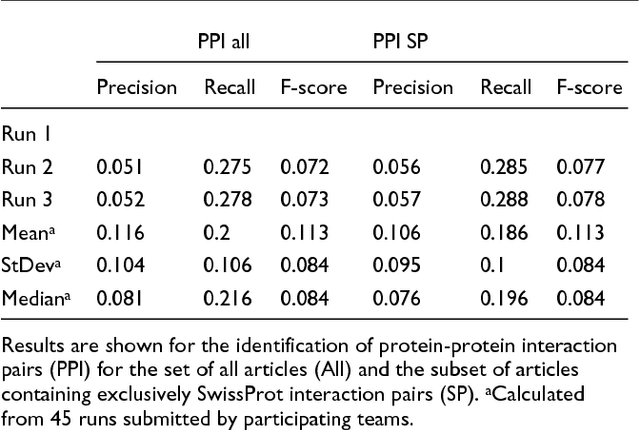
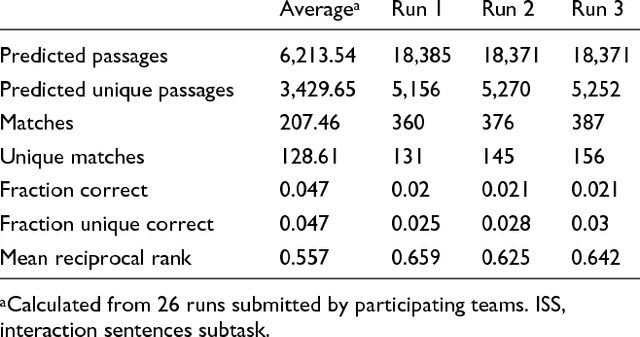
We participated in three of the protein-protein interaction subtasks of the Second BioCreative Challenge: classification of abstracts relevant for protein-protein interaction (IAS), discovery of protein pairs (IPS) and text passages characterizing protein interaction (ISS) in full text documents. We approached the abstract classification task with a novel, lightweight linear model inspired by spam-detection techniques, as well as an uncertainty-based integration scheme. We also used a Support Vector Machine and the Singular Value Decomposition on the same features for comparison purposes. Our approach to the full text subtasks (protein pair and passage identification) includes a feature expansion method based on word-proximity networks. Our approach to the abstract classification task (IAS) was among the top submissions for this task in terms of the measures of performance used in the challenge evaluation (accuracy, F-score and AUC). We also report on a web-tool we produced using our approach: the Protein Interaction Abstract Relevance Evaluator (PIARE). Our approach to the full text tasks resulted in one of the highest recall rates as well as mean reciprocal rank of correct passages. Our approach to abstract classification shows that a simple linear model, using relatively few features, is capable of generalizing and uncovering the conceptual nature of protein-protein interaction from the bibliome. Since the novel approach is based on a very lightweight linear model, it can be easily ported and applied to similar problems. In full text problems, the expansion of word features with word-proximity networks is shown to be useful, though the need for some improvements is discussed.