 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC*: A Coverage Path Planning Algorithm for Unknown Environments using Rapidly Covering Graphs
May 20, 2025


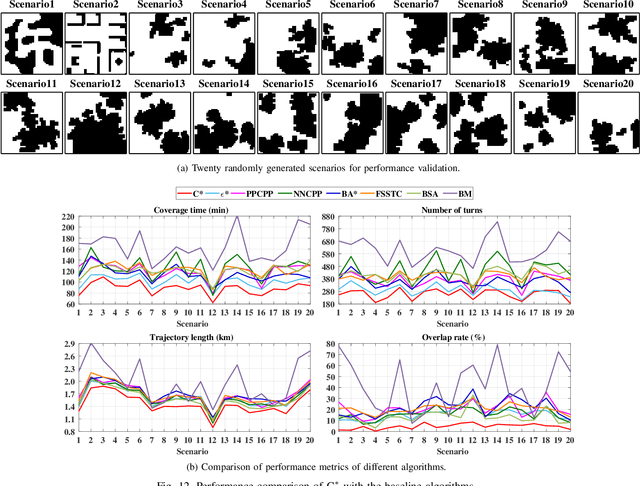
The paper presents a novel sample-based algorithm, called C*, for real-time coverage path planning (CPP) of unknown environments. The C* algorithm is built upon the concept of Rapidly Covering Graph (RCGs). The RCG is constructed incrementally via progressive sampling during robot navigation, which eliminates the need for cellular decomposition of the search space. The RCG has a sparse-graph structure formed by efficient sampling and pruning techniques, which produces non-myopic waypoints of the coverage trajectory. While C* produces the desired back and forth coverage pattern, it adapts to the TSP-based locally optimal coverage of small uncovered regions, called coverage holes, that are surrounded by obstacles and covered regions. Thus, C* proactively detects and covers the coverage holes in situ, which reduces the coverage time by preventing the longer return trajectories from distant regions to cover such holes later. The algorithmic simplicity and low computational complexity of C* makes it easy to implement and suitable for real-time onboard applications. It is analytically proven that C* provides complete coverage of unknown environments. The performance of C* is validated by 1) extensive high-fidelity simulations and 2) real laboratory experiments using autonomous robots. A comparative evaluation with seven existing CPP methods demonstrate that C* yields significant performance improvements in terms of coverage time, number of turns, trajectory length and overlap ratio, while preventing the formation of coverage holes. Finally, C* is evaluated on two different applications of CPP using 1) energy-constrained robots and 2) multi-robot teams.
Generalized Multi-Speed Dubins Motion Model
Feb 02, 2024The paper develops a novel motion model, called Generalized Multi-Speed Dubins Motion Model (GMDM), which extends the Dubins model by considering multiple speeds. While the Dubins model produces time-optimal paths under a constant-speed constraint, these paths could be suboptimal if this constraint is relaxed to include multiple speeds. This is because a constant speed results in a large minimum turning radius, thus producing paths with longer maneuvers and larger travel times. In contrast, multi-speed relaxation allows for slower speed sharp turns, thus producing more direct paths with shorter maneuvers and smaller travel times. Furthermore, the inability of the Dubins model to reduce speed could result in fast maneuvers near obstacles, thus producing paths with high collision risks. In this regard, GMDM provides the motion planners the ability to jointly optimize time and risk by allowing the change of speed along the path. GMDM is built upon the six Dubins path types considering the change of speed on path segments. It is theoretically established that GMDM provides full reachability of the configuration space for any speed selections. Furthermore, it is shown that the Dubins model is a specific case of GMDM for constant speeds. The solutions of GMDM are analytical and suitable for real-time applications. The performance of GMDM in terms of solution quality (i.e., time/time-risk cost) and computation time is comparatively evaluated against the existing motion models in obstacle-free as well as obstacle-rich environments via extensive Monte Carlo simulations. The results show that in obstacle-free environments, GMDM produces near time-optimal paths with significantly lower travel times than the Dubins model while having similar computation times. In obstacle-rich environments, GMDM produces time-risk optimized paths with substantially lower collision risks.
SMART: Self-Morphing Anytime Replanning Tree
May 10, 2023The paper presents an algorithm, called Self- Morphing Anytime Replanning Tree (SMART), that facilitates anytime replanning in dynamic environments. SMART performs risk-based tree-pruning if its current path is obstructed by nearby moving obstacle(s), resulting in multiple disjoint subtrees. Then, for speedy recovery, it exploits these subtrees and performs informed tree-repair at hot-spots that lie at the intersection of subtrees to find a new path. The performance of SMART is comparatively evaluated with seven existing algorithms through extensive simulations. Two scenarios are considered with: 1) dynamic obstacles and 2) both static and dynamic obstacles. The results show that SMART yields significant improvements in replanning time, success rate and travel time. Finally, the performance of SMART is validated by a real laboratory experiment.
CPPNet: A Coverage Path Planning Network
Aug 03, 2021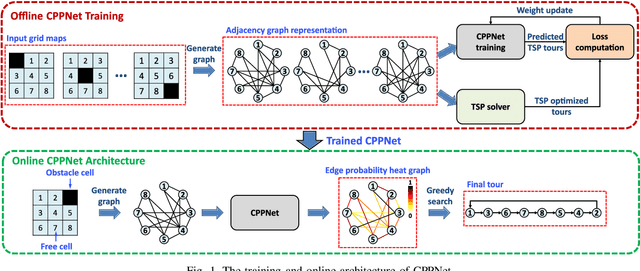
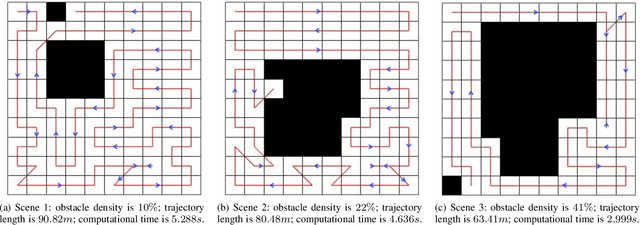
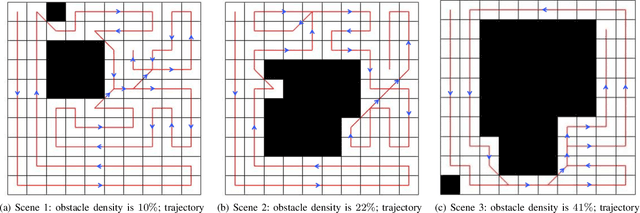
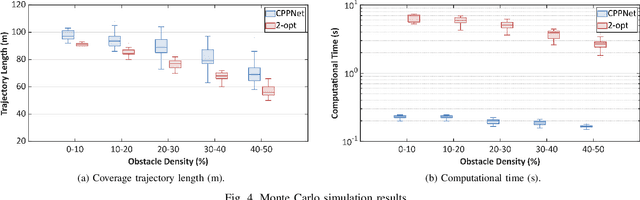
This paper presents a deep-learning based CPP algorithm, called Coverage Path Planning Network (CPPNet). CPPNet is built using a convolutional neural network (CNN) whose input is a graph-based representation of the occupancy grid map while its output is an edge probability heat graph, where the value of each edge is the probability of belonging to the optimal TSP tour. Finally, a greedy search is used to select the final optimized tour. CPPNet is trained and comparatively evaluated against the TSP tour. It is shown that CPPNet provides near-optimal solutions while requiring significantly less computational time, thus enabling real-time coverage path planning in partially unknown and dynamic environments.
A Non-uniform Sampling Approach for Fast and Efficient Path Planning
Aug 03, 2021

In this paper, we develop a non-uniform sampling approach for fast and efficient path planning of autonomous vehicles. The approach uses a novel non-uniform partitioning scheme that divides the area into obstacle-free convex cells. The partitioning results in large cells in obstacle-free areas and small cells in obstacle-dense areas. Subsequently, the boundaries of these cells are used for sampling; thus significantly reducing the burden of uniform sampling. When compared with a standard uniform sampler, this smart sampler significantly 1) reduces the size of the sampling space while providing completeness and optimality guarantee, 2) provides sparse sampling in obstacle-free regions and dense sampling in obstacle-rich regions to facilitate faster exploration, and 3) eliminates the need for expensive collision-checking with obstacles due to the convexity of the cells. This sampling framework is incorporated into the RRT* path planner. The results show that RRT* with the non-uniform sampler gives a significantly better convergence rate and smaller memory footprint as compared to RRT* with a uniform sampler.
MRRT: Multiple Rapidly-Exploring Random Trees for Fast Online Replanning in Dynamic Environments
Apr 22, 2021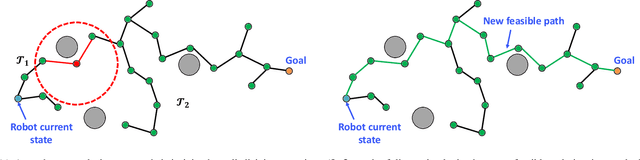
This paper presents a novel algorithm, called MRRT, which uses multiple rapidly-exploring random trees for fast online replanning of autonomous vehicles in dynamic environments with moving obstacles. The proposed algorithm is built upon the RRT algorithm with a multi-tree structure. At the beginning, the RRT algorithm is applied to find the initial solution based on partial knowledge of the environment. Then, the robot starts to execute this path. At each iteration, the new obstacle configurations are collected by the robot's sensor and used to replan the path. This new information can come from unknown static obstacles (e.g., seafloor layout) as well as moving obstacles. Then, to accommodate the environmental changes, two procedures are adopted: 1) edge pruning, and 2) tree regrowing. Specifically, the edge pruning procedure checks the collision status through the tree and only removes the invalid edges while maintaining the tree structure of already-explored regions. Due to removal of invalid edges, the tree could be broken into multiple disjoint trees. As such, the RRT algorithm is applied to regrow the trees. Specifically, a sample is created randomly and joined to all the disjoint trees in its local neighborhood by connecting to the nearest nodes. Finally, a new solution is found for the robot. The advantages of the proposed MRRT algorithm are as follows: i) retains the maximal tree structure by only pruning the edges which collide with the obstacles, ii) guarantees probabilistic completeness, and iii) is computational efficient for fast replanning since all disjoint trees are maintained for future connections and expanded simultaneously.
DARE: AI-based Diver Action Recognition System using Multi-Channel CNNs for AUV Supervision
Nov 16, 2020
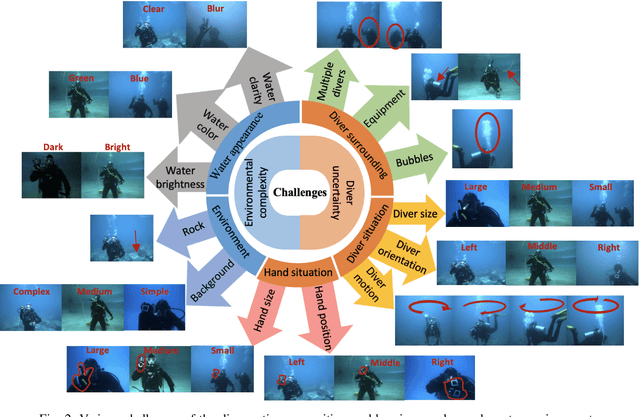
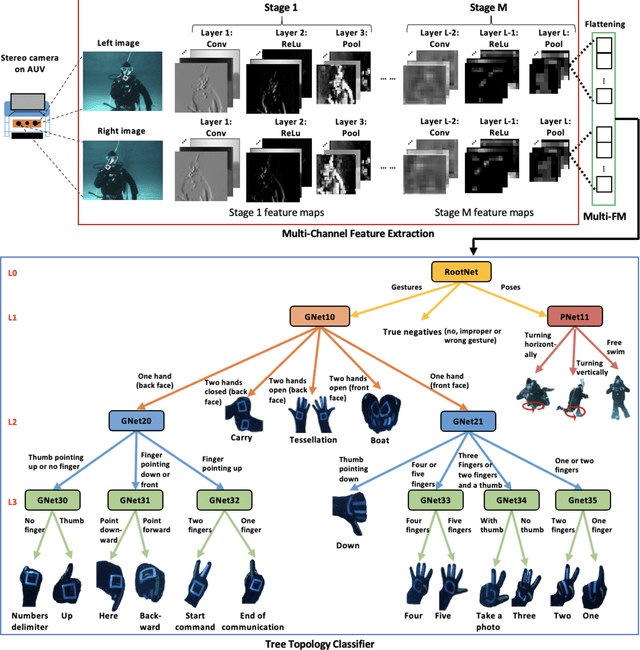

With the growth of sensing, control and robotic technologies, autonomous underwater vehicles (AUVs) have become useful assistants to human divers for performing various underwater operations. In the current practice, the divers are required to carry expensive, bulky, and waterproof keyboards or joystick-based controllers for supervision and control of AUVs. Therefore, diver action-based supervision is becoming increasingly popular because it is convenient, easier to use, faster, and cost effective. However, the various environmental, diver and sensing uncertainties present underwater makes it challenging to train a robust and reliable diver action recognition system. In this regard, this paper presents DARE, a diver action recognition system, that is trained based on Cognitive Autonomous Driving Buddy (CADDY) dataset, which is a rich set of data containing images of different diver gestures and poses in several different and realistic underwater environments. DARE is based on fusion of stereo-pairs of camera images using a multi-channel convolutional neural network supported with a systematically trained tree-topological deep neural network classifier to enhance the classification performance. DARE is fast and requires only a few milliseconds to classify one stereo-pair, thus making it suitable for real-time underwater implementation. DARE is comparatively evaluated against several existing classifier architectures and the results show that DARE supersedes the performance of all classifiers for diver action recognition in terms of overall as well as individual class accuracies and F1-scores.
T$^{\star}$-Lite: A Fast Time-Risk Optimal Motion Planning Algorithm for Multi-Speed Autonomous Vehicles
Aug 29, 2020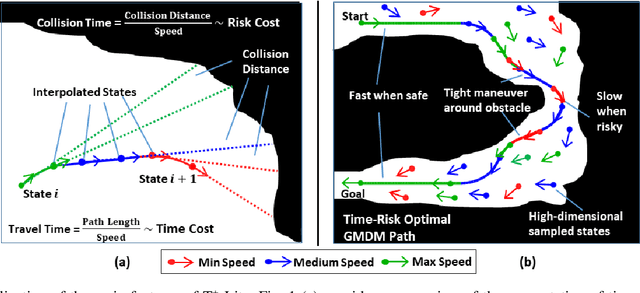

In this paper, we develop a new algorithm, called T$^{\star}$-Lite, that enables fast time-risk optimal motion planning for variable-speed autonomous vehicles. The T$^{\star}$-Lite algorithm is a significantly faster version of the previously developed T$^{\star}$ algorithm. T$^{\star}$-Lite uses the novel time-risk cost function of T$^{\star}$; however, instead of a grid-based approach, it uses an asymptotically optimal sampling-based motion planner. Furthermore, it utilizes the recently developed Generalized Multi-speed Dubins Motion-model (GMDM) for sample-to-sample kinodynamic motion planning. The sample-based approach and GMDM significantly reduce the computational burden of T$^{\star}$ while providing reasonable solution quality. The sample points are drawn from a four-dimensional configuration space consisting of two position coordinates plus vehicle heading and speed. Specifically, T$^{\star}$-Lite enables the motion planner to select the vehicle speed and direction based on its proximity to the obstacle to generate faster and safer paths. In this paper, T$^{\star}$-Lite is developed using the RRT$^{\star}$ motion planner, but adaptation to other motion planners is straightforward and depends on the needs of the planner
$ε^*$+: An Online Coverage Path Planning Algorithm for Energy-constrained Autonomous Vehicles
Aug 29, 2020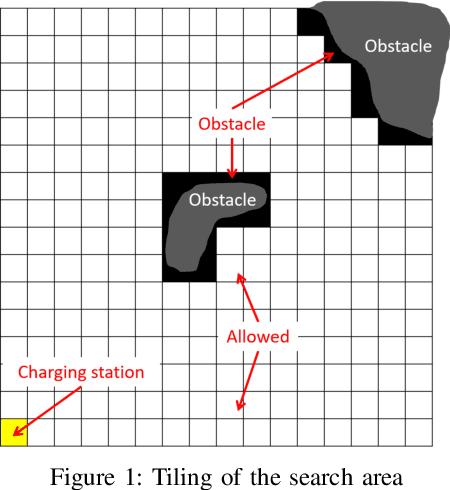
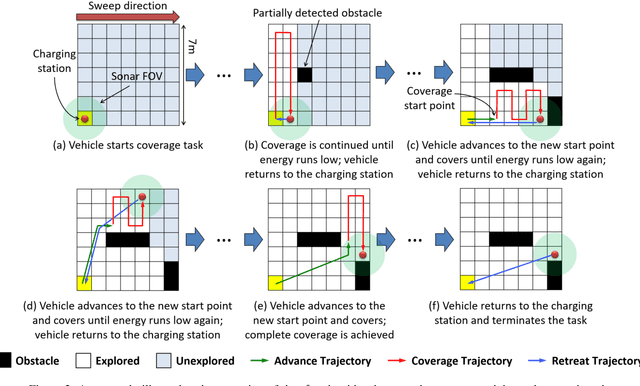
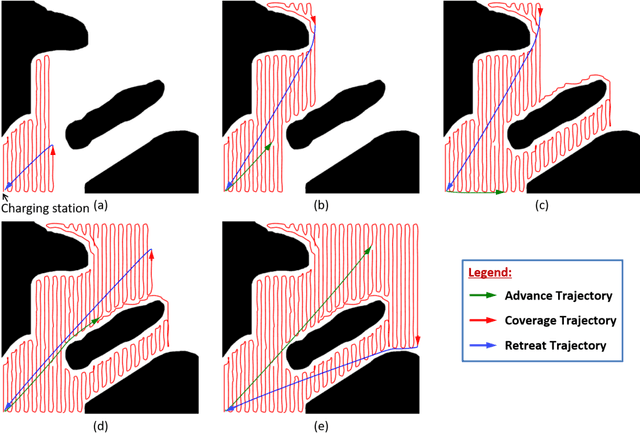
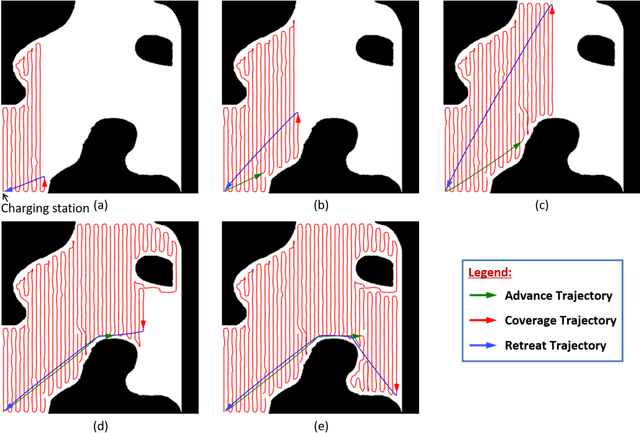
This paper presents a novel algorithm, called $\epsilon^*$+, for online coverage path planning of unknown environments using energy-constrained autonomous vehicles. Due to limited battery size, the energy-constrained vehicles have limited duration of operation time. Therefore, while executing a coverage trajectory, the vehicle has to return to the charging station for a recharge before the battery runs out. In this regard, the $\epsilon^*$+ algorithm enables the vehicle to retreat back to the charging station based on the remaining energy which is monitored throughout the coverage process. This is followed by an advance trajectory that takes the vehicle to a near by unexplored waypoint to restart the coverage process, instead of taking it back to the previous left over point of the retreat trajectory; thus reducing the overall coverage time. The proposed $\epsilon^*$+ algorithm is an extension of the $\epsilon^*$ algorithm, which utilizes an Exploratory Turing Machine (ETM) as a supervisor to navigate the vehicle with back and forth trajectory for complete coverage. The performance of the $\epsilon^*$+ algorithm is validated on complex scenarios using Player/Stage which is a high-fidelity robotic simulator.