 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multi-Task Learning & Model Fusion for Efficient Language Model Guardrailing
Apr 29, 2025



The trend towards large language models (LLMs) for guardrailing against undesired behaviors is increasing and has shown promise for censoring user inputs. However, increased latency, memory consumption, hosting expenses and non-structured outputs can make their use prohibitive. In this work, we show that task-specific data generation can lead to fine-tuned classifiers that significantly outperform current state of the art (SoTA) while being orders of magnitude smaller. Secondly, we show that using a single model, \texttt{MultiTaskGuard}, that is pretrained on a large synthetically generated dataset with unique task instructions further improves generalization. Thirdly, our most performant models, \texttt{UniGuard}, are found using our proposed search-based model merging approach that finds an optimal set of parameters to combine single-policy models and multi-policy guardrail models. % On 7 public datasets and 4 guardrail benchmarks we created, our efficient guardrail classifiers improve over the best performing SoTA publicly available LLMs and 3$^{\text{rd}}$ party guardrail APIs in detecting unsafe and safe behaviors by an average F1 score improvement of \textbf{29.92} points over Aegis-LlamaGuard and \textbf{21.62} over \texttt{gpt-4o}, respectively. Lastly, our guardrail synthetic data generation process that uses custom task-specific guardrail poli
Gradient Sparsification For Masked Fine-Tuning of Transformers
Jul 19, 2023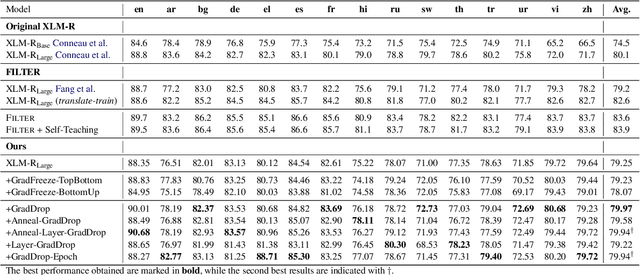
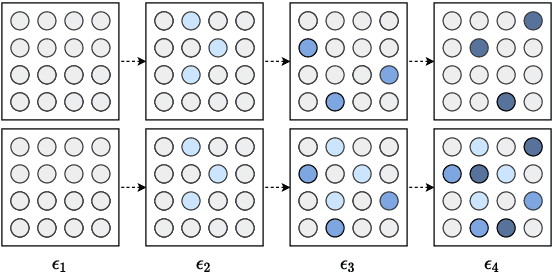
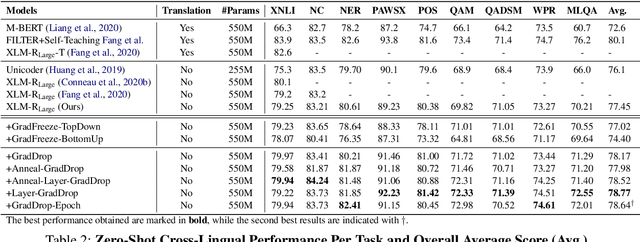
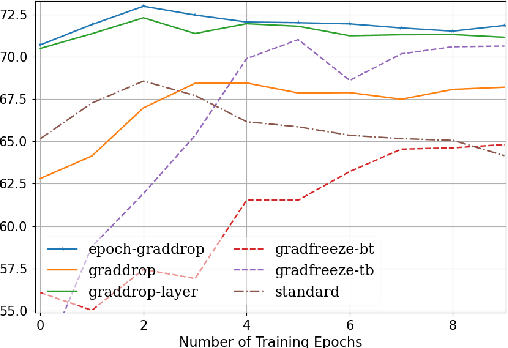
Fine-tuning pretrained self-supervised language models is widely adopted for transfer learning to downstream tasks. Fine-tuning can be achieved by freezing gradients of the pretrained network and only updating gradients of a newly added classification layer, or by performing gradient updates on all parameters. Gradual unfreezing makes a trade-off between the two by gradually unfreezing gradients of whole layers during training. This has been an effective strategy to trade-off between storage and training speed with generalization performance. However, it is not clear whether gradually unfreezing layers throughout training is optimal, compared to sparse variants of gradual unfreezing which may improve fine-tuning performance. In this paper, we propose to stochastically mask gradients to regularize pretrained language models for improving overall fine-tuned performance. We introduce GradDrop and variants thereof, a class of gradient sparsification methods that mask gradients during the backward pass, acting as gradient noise. GradDrop is sparse and stochastic unlike gradual freezing. Extensive experiments on the multilingual XGLUE benchmark with XLMR-Large show that GradDrop is competitive against methods that use additional translated data for intermediate pretraining and outperforms standard fine-tuning and gradual unfreezing. A post-analysis shows how GradDrop improves performance with languages it was not trained on, such as under-resourced languages.
Self-Distilled Quantization: Achieving High Compression Rates in Transformer-Based Language Models
Jul 12, 2023We investigate the effects of post-training quantization and quantization-aware training on the generalization of Transformer language models. We present a new method called self-distilled quantization (SDQ) that minimizes accumulative quantization errors and outperforms baselines. We apply SDQ to multilingual models XLM-R-Base and InfoXLM-Base and demonstrate that both models can be reduced from 32-bit floating point weights to 8-bit integer weights while maintaining a high level of performance on the XGLUE benchmark. Our results also highlight the challenges of quantizing multilingual models, which must generalize to languages they were not fine-tuned on.
Aligned Weight Regularizers for Pruning Pretrained Neural Networks
Apr 05, 2022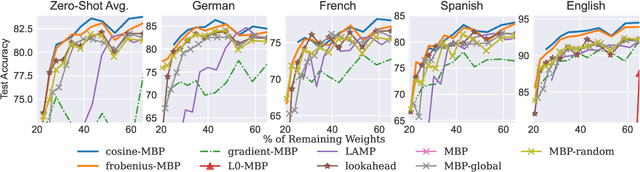

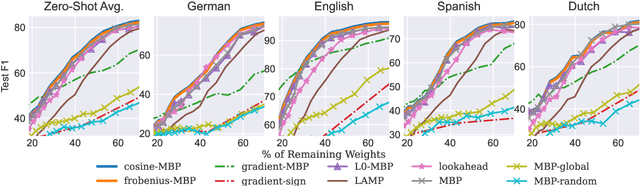

While various avenues of research have been explored for iterative pruning, little is known what effect pruning has on zero-shot test performance and its potential implications on the choice of pruning criteria. This pruning setup is particularly important for cross-lingual models that implicitly learn alignment between language representations during pretraining, which if distorted via pruning, not only leads to poorer performance on language data used for retraining but also on zero-shot languages that are evaluated. In this work, we show that there is a clear performance discrepancy in magnitude-based pruning when comparing standard supervised learning to the zero-shot setting. From this finding, we propose two weight regularizers that aim to maximize the alignment between units of pruned and unpruned networks to mitigate alignment distortion in pruned cross-lingual models and perform well for both non zero-shot and zero-shot settings. We provide experimental results on cross-lingual tasks for the zero-shot setting using XLM-RoBERTa$_{\mathrm{Base}}$, where we also find that pruning has varying degrees of representational degradation depending on the language corresponding to the zero-shot test set. This is also the first study that focuses on cross-lingual language model compression.
Deep Neural Compression Via Concurrent Pruning and Self-Distillation
Sep 30, 2021


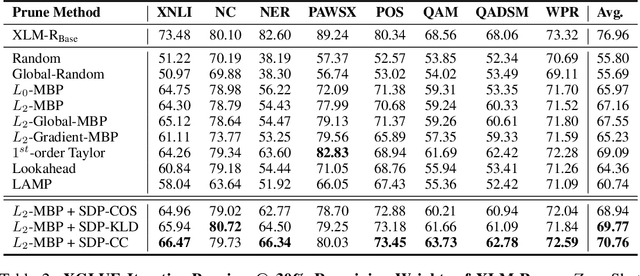
Pruning aims to reduce the number of parameters while maintaining performance close to the original network. This work proposes a novel \emph{self-distillation} based pruning strategy, whereby the representational similarity between the pruned and unpruned versions of the same network is maximized. Unlike previous approaches that treat distillation and pruning separately, we use distillation to inform the pruning criteria, without requiring a separate student network as in knowledge distillation. We show that the proposed {\em cross-correlation objective for self-distilled pruning} implicitly encourages sparse solutions, naturally complementing magnitude-based pruning criteria. Experiments on the GLUE and XGLUE benchmarks show that self-distilled pruning increases mono- and cross-lingual language model performance. Self-distilled pruned models also outperform smaller Transformers with an equal number of parameters and are competitive against (6 times) larger distilled networks. We also observe that self-distillation (1) maximizes class separability, (2) increases the signal-to-noise ratio, and (3) converges faster after pruning steps, providing further insights into why self-distilled pruning improves generalization.
Semantically-Conditioned Negative Samples for Efficient Contrastive Learning
Feb 12, 2021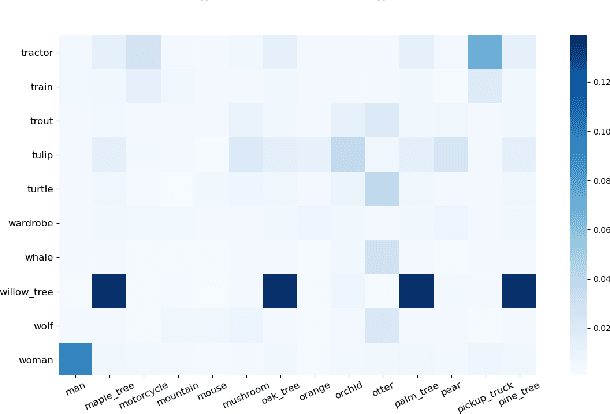



Negative sampling is a limiting factor w.r.t. the generalization of metric-learned neural networks. We show that uniform negative sampling provides little information about the class boundaries and thus propose three novel techniques for efficient negative sampling: drawing negative samples from (1) the top-$k$ most semantically similar classes, (2) the top-$k$ most semantically similar samples and (3) interpolating between contrastive latent representations to create pseudo negatives. Our experiments on CIFAR-10, CIFAR-100 and Tiny-ImageNet-200 show that our proposed \textit{Semantically Conditioned Negative Sampling} and Latent Mixup lead to consistent performance improvements. In the standard supervised learning setting, on average we increase test accuracy by 1.52\% percentage points on CIFAR-10 across various network architectures. In the knowledge distillation setting, (1) the performance of student networks increase by 4.56\% percentage points on Tiny-ImageNet-200 and 3.29\% on CIFAR-100 over student networks trained with no teacher and (2) 1.23\% and 1.72\% respectively over a \textit{hard-to-beat} baseline (Hinton et al., 2015).
$k$-Neighbor Based Curriculum Sampling for Sequence Prediction
Jan 22, 2021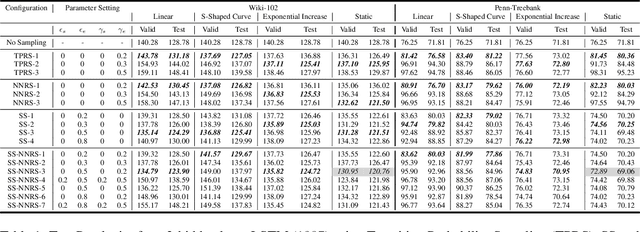
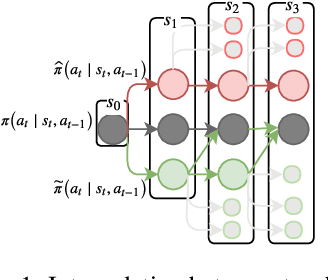

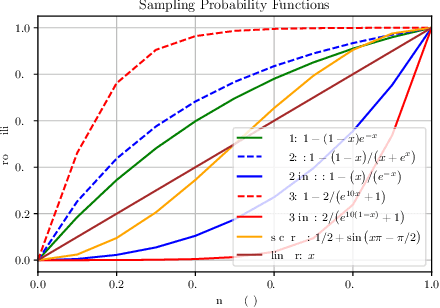
Multi-step ahead prediction in language models is challenging due to the discrepancy between training and test time processes. At test time, a sequence predictor is required to make predictions given past predictions as the input, instead of the past targets that are provided during training. This difference, known as exposure bias, can lead to the compounding of errors along a generated sequence at test time. To improve generalization in neural language models and address compounding errors, we propose \textit{Nearest-Neighbor Replacement Sampling} -- a curriculum learning-based method that gradually changes an initially deterministic teacher policy to a stochastic policy. A token at a given time-step is replaced with a sampled nearest neighbor of the past target with a truncated probability proportional to the cosine similarity between the original word and its top $k$ most similar words. This allows the learner to explore alternatives when the current policy provided by the teacher is sub-optimal or difficult to learn from. The proposed method is straightforward, online and requires little additional memory requirements. We report our findings on two language modelling benchmarks and find that the proposed method further improves performance when used in conjunction with scheduled sampling.
Compressing Deep Neural Networks via Layer Fusion
Jul 29, 2020



This paper proposes \textit{layer fusion} - a model compression technique that discovers which weights to combine and then fuses weights of similar fully-connected, convolutional and attention layers. Layer fusion can significantly reduce the number of layers of the original network with little additional computation overhead, while maintaining competitive performance. From experiments on CIFAR-10, we find that various deep convolution neural networks can remain within 2\% accuracy points of the original networks up to a compression ratio of 3.33 when iteratively retrained with layer fusion. For experiments on the WikiText-2 language modelling dataset where pretrained transformer models are used, we achieve compression that leads to a network that is 20\% of its original size while being within 5 perplexity points of the original network. We also find that other well-established compression techniques can achieve competitive performance when compared to their original networks given a sufficient number of retraining steps. Generally, we observe a clear inflection point in performance as the amount of compression increases, suggesting a bound on the amount of compression that can be achieved before an exponential degradation in performance.
An Overview of Neural Network Compression
Jun 05, 2020

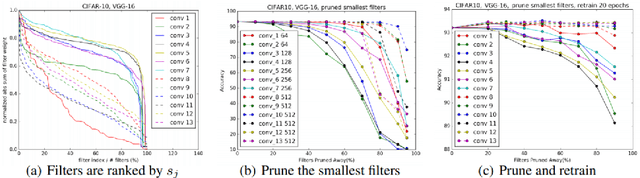

Overparameterized networks trained to convergence have shown impressive performance in domains such as computer vision and natural language processing. Pushing state of the art on salient tasks within these domains corresponds to these models becoming larger and more difficult for machine learning practitioners to use given the increasing memory and storage requirements, not to mention the larger carbon footprint. Thus, in recent years there has been a resurgence in model compression techniques, particularly for deep convolutional neural networks and self-attention based networks such as the Transformer. Hence, this paper provides a timely overview of both old and current compression techniques for deep neural networks, including pruning, quantization, tensor decomposition, knowledge distillation and combinations thereof. We assume a basic familiarity with deep learning architectures\footnote{For an introduction to deep learning, see ~\citet{goodfellow2016deep}}, namely, Recurrent Neural Networks~\citep[(RNNs)][]{rumelhart1985learning,hochreiter1997long}, Convolutional Neural Networks~\citep{fukushima1980neocognitron}~\footnote{For an up to date overview see~\citet{khan2019survey}} and Self-Attention based networks~\citep{vaswani2017attention}\footnote{For a general overview of self-attention networks, see ~\citet{chaudhari2019attentive}.},\footnote{For more detail and their use in natural language processing, see~\citet{hu2019introductory}}. Most of the papers discussed are proposed in the context of at least one of these DNN architectures.
Transfer Reward Learning for Policy Gradient-Based Text Generation
Sep 09, 2019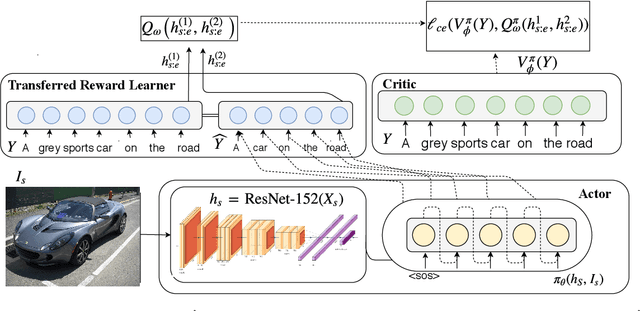



Task-specific scores are often used to optimize for and evaluate the performance of conditional text generation systems. However, such scores are non-differentiable and cannot be used in the standard supervised learning paradigm. Hence, policy gradient methods are used since the gradient can be computed without requiring a differentiable objective. However, we argue that current n-gram overlap based measures that are used as rewards can be improved by using model-based rewards transferred from tasks that directly compare the similarity of sentence pairs. These reward models either output a score of sentence-level syntactic and semantic similarity between entire predicted and target sentences as the expected return, or for intermediate phrases as segmented accumulative rewards. We demonstrate that using a \textit{Transferable Reward Learner} leads to improved results on semantical evaluation measures in policy-gradient models for image captioning tasks. Our InferSent actor-critic model improves over a BLEU trained actor-critic model on MSCOCO when evaluated on a Word Mover's Distance similarity measure by 6.97 points, also improving on a Sliding Window Cosine Similarity measure by 10.48 points. Similar performance improvements are also obtained on the smaller Flickr-30k dataset, demonstrating the general applicability of the proposed transfer learning method.