 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$k$-Neighbor Based Curriculum Sampling for Sequence Prediction
Paper and Code
Jan 22, 2021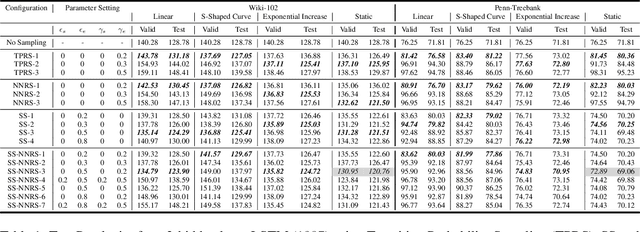
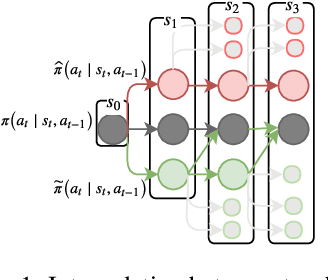

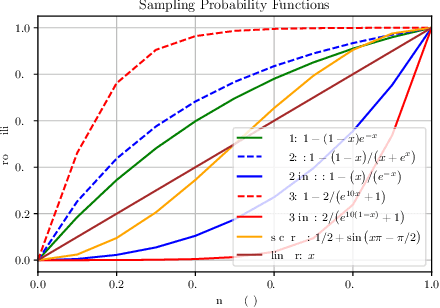
Multi-step ahead prediction in language models is challenging due to the discrepancy between training and test time processes. At test time, a sequence predictor is required to make predictions given past predictions as the input, instead of the past targets that are provided during training. This difference, known as exposure bias, can lead to the compounding of errors along a generated sequence at test time. To improve generalization in neural language models and address compounding errors, we propose \textit{Nearest-Neighbor Replacement Sampling} -- a curriculum learning-based method that gradually changes an initially deterministic teacher policy to a stochastic policy. A token at a given time-step is replaced with a sampled nearest neighbor of the past target with a truncated probability proportional to the cosine similarity between the original word and its top $k$ most similar words. This allows the learner to explore alternatives when the current policy provided by the teacher is sub-optimal or difficult to learn from. The proposed method is straightforward, online and requires little additional memory requirements. We report our findings on two language modelling benchmarks and find that the proposed method further improves performance when used in conjunction with scheduled sampling.