 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotalSegmentator MRI: Sequence-Independent Segmentation of 59 Anatomical Structures in MR images
May 29, 2024



Purpose: To develop an open-source and easy-to-use segmentation model that can automatically and robustly segment most major anatomical structures in MR images independently of the MR sequence. Materials and Methods: In this study we extended the capabilities of TotalSegmentator to MR images. 298 MR scans and 227 CT scans were used to segment 59 anatomical structures (20 organs, 18 bones, 11 muscles, 7 vessels, 3 tissue types) relevant for use cases such as organ volumetry, disease characterization, and surgical planning. The MR and CT images were randomly sampled from routine clinical studies and thus represent a real-world dataset (different ages, pathologies, scanners, body parts, sequences, contrasts, echo times, repetition times, field strengths, slice thicknesses and sites). We trained an nnU-Net segmentation algorithm on this dataset and calculated Dice similarity coefficients (Dice) to evaluate the model's performance. Results: The model showed a Dice score of 0.824 (CI: 0.801, 0.842) on the test set, which included a wide range of clinical data with major pathologies. The model significantly outperformed two other publicly available segmentation models (Dice score, 0.824 versus 0.762; p<0.001 and 0.762 versus 0.542; p<0.001). On the CT image test set of the original TotalSegmentator paper it almost matches the performance of the original TotalSegmentator (Dice score, 0.960 versus 0.970; p<0.001). Conclusion: Our proposed model extends the capabilities of TotalSegmentator to MR images. The annotated dataset (https://zenodo.org/doi/10.5281/zenodo.11367004) and open-source toolkit (https://www.github.com/wasserth/TotalSegmentator) are publicly available.
FedNorm: Modality-Based Normalization in Federated Learning for Multi-Modal Liver Segmentation
May 23, 2022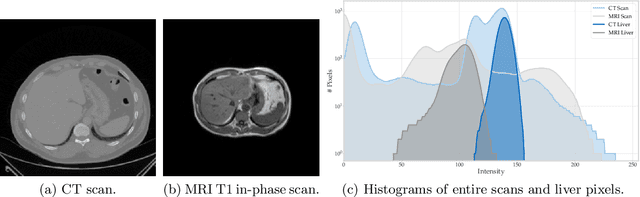


Given the high incidence and effective treatment options for liver diseases, they are of great socioeconomic importance. One of the most common methods for analyzing CT and MRI images for diagnosis and follow-up treatment is liver segmentation. Recent advances in deep learning have demonstrated encouraging results for automatic liver segmentation. Despite this, their success depends primarily on the availability of an annotated database, which is often not available because of privacy concerns. Federated Learning has been recently proposed as a solution to alleviate these challenges by training a shared global model on distributed clients without access to their local databases. Nevertheless, Federated Learning does not perform well when it is trained on a high degree of heterogeneity of image data due to multi-modal imaging, such as CT and MRI, and multiple scanner types. To this end, we propose Fednorm and its extension \fednormp, two Federated Learning algorithms that use a modality-based normalization technique. Specifically, Fednorm normalizes the features on a client-level, while Fednorm+ employs the modality information of single slices in the feature normalization. Our methods were validated using 428 patients from six publicly available databases and compared to state-of-the-art Federated Learning algorithms and baseline models in heterogeneous settings (multi-institutional, multi-modal data). The experimental results demonstrate that our methods show an overall acceptable performance, achieve Dice per patient scores up to 0.961, consistently outperform locally trained models, and are on par or slightly better than centralized models.