 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Solving Simultaneous-Move Dec-POMDPs: The Sequential Central Planning Approach
Aug 23, 2024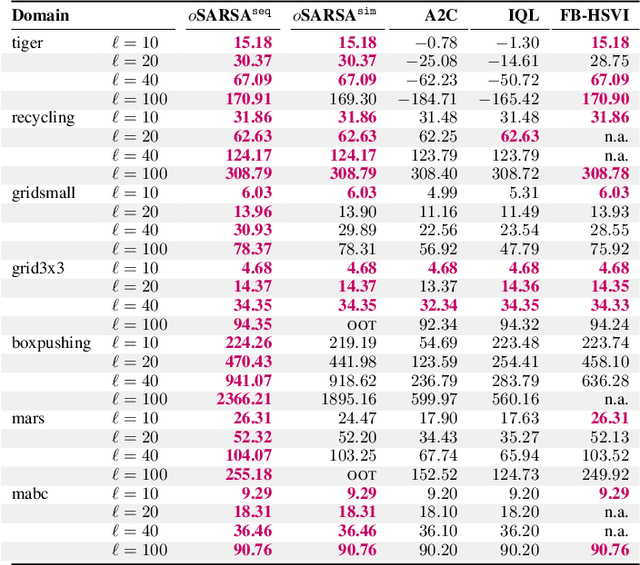
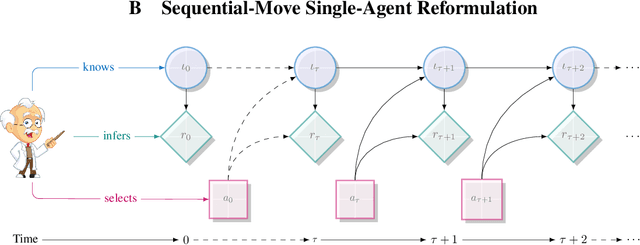
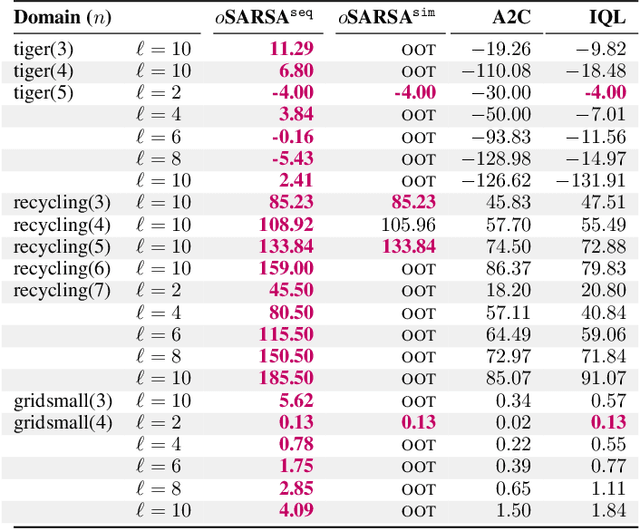
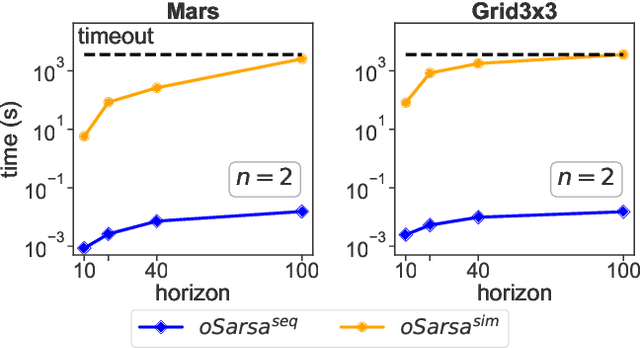
Centralized training for decentralized execution paradigm emerged as the state-of-the-art approach to epsilon-optimally solving decentralized partially observable Markov decision processes. However, scalability remains a significant issue. This paper presents a novel and more scalable alternative, namely sequential-move centralized training for decentralized execution. This paradigm further pushes the applicability of Bellman's principle of optimality, raising three new properties. First, it allows a central planner to reason upon sufficient sequential-move statistics instead of prior simultaneous-move ones. Next, it proves that epsilon-optimal value functions are piecewise linear and convex in sufficient sequential-move statistics. Finally, it drops the complexity of the backup operators from double exponential to polynomial at the expense of longer planning horizons. Besides, it makes it easy to use single-agent methods, e.g., SARSA algorithm enhanced with these findings applies while still preserving convergence guarantees. Experiments on two- as well as many-agent domains from the literature against epsilon-optimal simultaneous-move solvers confirm the superiority of the novel approach. This paradigm opens the door for efficient planning and reinforcement learning methods for multi-agent systems.
Difference Rewards Policy Gradients
Dec 21, 2020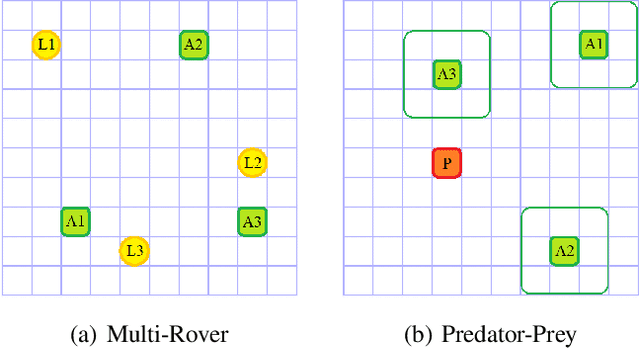

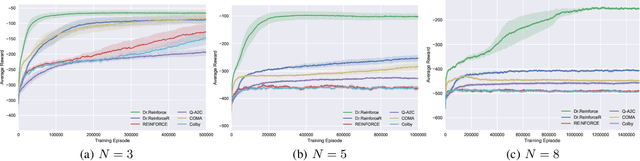
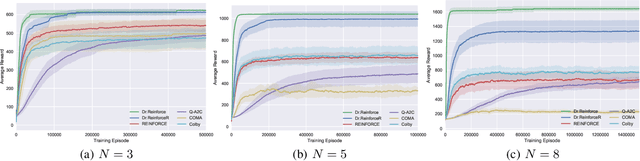
Policy gradient methods have become one of the most popular classes of algorithms for multi-agent reinforcement learning. A key challenge, however, that is not addressed by many of these methods is multi-agent credit assignment: assessing an agent's contribution to the overall performance, which is crucial for learning good policies. We propose a novel algorithm called Dr.Reinforce that explicitly tackles this by combining difference rewards with policy gradients to allow for learning decentralized policies when the reward function is known. By differencing the reward function directly, Dr.Reinforce avoids difficulties associated with learning the Q-function as done by Counterfactual Multiagent Policy Gradients (COMA), a state-of-the-art difference rewards method. For applications where the reward function is unknown, we show the effectiveness of a version of Dr.Reinforce that learns an additional reward network that is used to estimate the difference rewards.
Learning Numeracy: Binary Arithmetic with Neural Turing Machines
Apr 04, 2019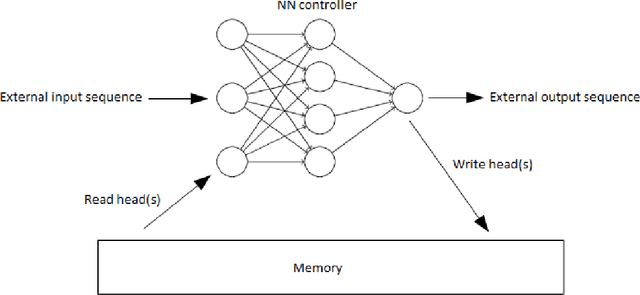

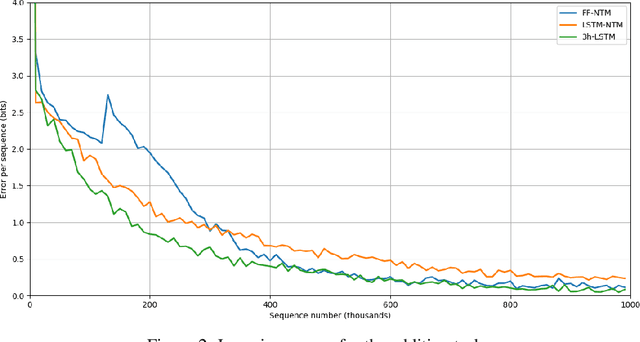
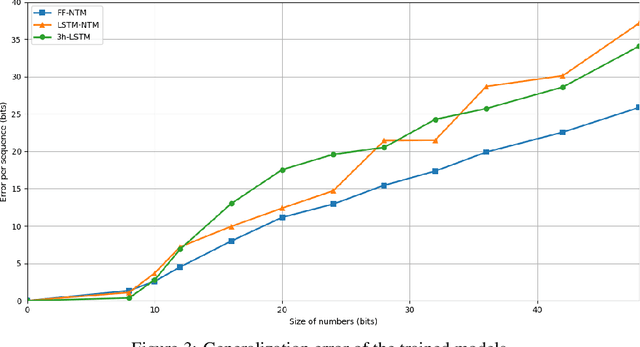
One of the main problems encountered so far with recurrent neural networks is that they struggle to retain long-time information dependencies in their recurrent connections. Neural Turing Machines (NTMs) attempt to mitigate this issue by providing the neural network with an external portion of memory, in which information can be stored and manipulated later on. The whole mechanism is differentiable end-to-end, allowing the network to learn how to utilise this long-term memory via SGD. This allows NTMs to infer simple algorithms directly from data sequences. Nonetheless, the model can be hard to train due to a large number of parameters and interacting components and little related work is present. In this work we use a NTM to learn and generalise two arithmetical tasks: binary addition and multiplication. These tasks are two fundamental algorithmic examples in computer science, and are a lot more challenging than the previously explored ones, with which we aim to shed some light on the capabilities on this neural model.