 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Solving Simultaneous-Move Dec-POMDPs: The Sequential Central Planning Approach
Paper and Code
Aug 23, 2024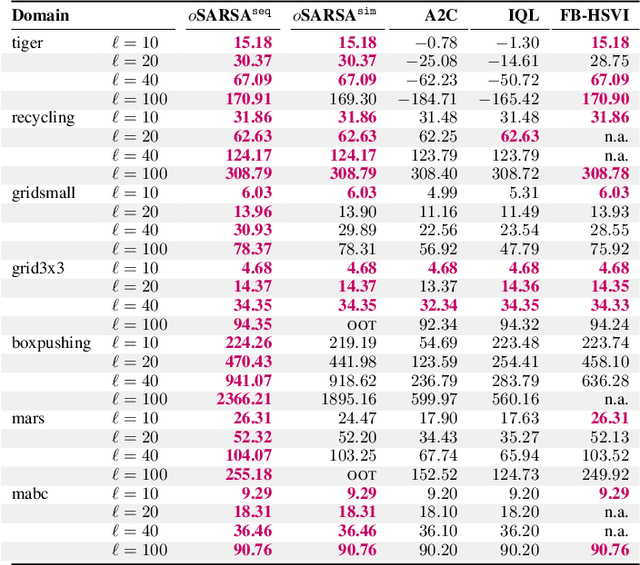
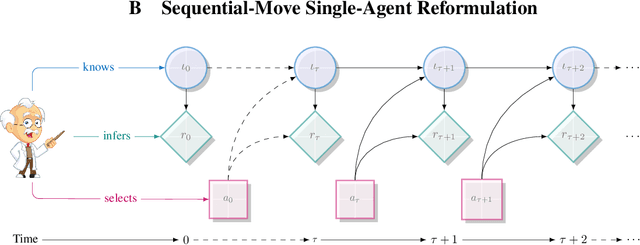
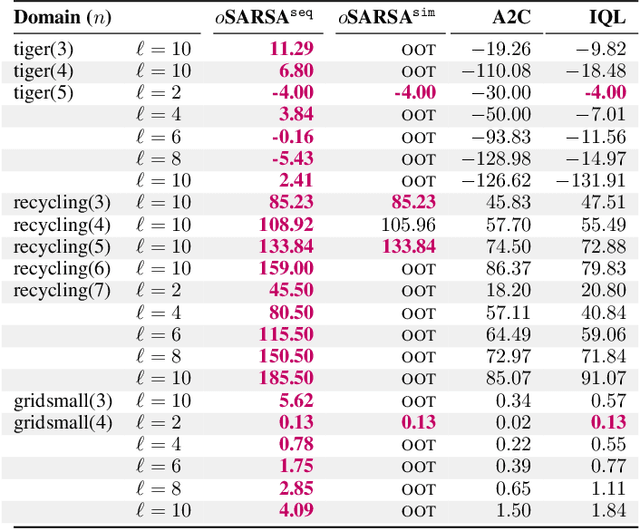
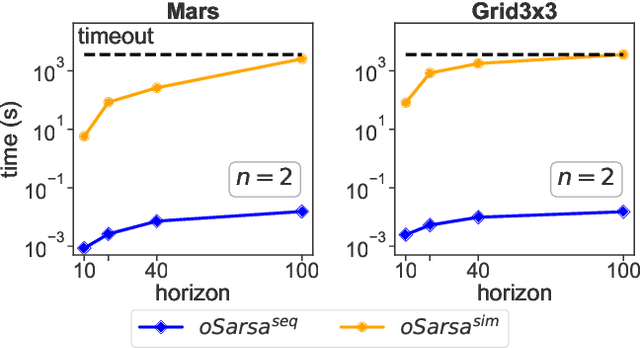
Centralized training for decentralized execution paradigm emerged as the state-of-the-art approach to epsilon-optimally solving decentralized partially observable Markov decision processes. However, scalability remains a significant issue. This paper presents a novel and more scalable alternative, namely sequential-move centralized training for decentralized execution. This paradigm further pushes the applicability of Bellman's principle of optimality, raising three new properties. First, it allows a central planner to reason upon sufficient sequential-move statistics instead of prior simultaneous-move ones. Next, it proves that epsilon-optimal value functions are piecewise linear and convex in sufficient sequential-move statistics. Finally, it drops the complexity of the backup operators from double exponential to polynomial at the expense of longer planning horizons. Besides, it makes it easy to use single-agent methods, e.g., SARSA algorithm enhanced with these findings applies while still preserving convergence guarantees. Experiments on two- as well as many-agent domains from the literature against epsilon-optimal simultaneous-move solvers confirm the superiority of the novel approach. This paradigm opens the door for efficient planning and reinforcement learning methods for multi-agent systems.