 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyJuice Makes It Real: Black-Box, Universal Red Teaming for Synthetic Image Detectors
Sep 19, 2025Synthetic image detectors (SIDs) are a key defense against the risks posed by the growing realism of images from text-to-image (T2I) models. Red teaming improves SID's effectiveness by identifying and exploiting their failure modes via misclassified synthetic images. However, existing red-teaming solutions (i) require white-box access to SIDs, which is infeasible for proprietary state-of-the-art detectors, and (ii) generate image-specific attacks through expensive online optimization. To address these limitations, we propose PolyJuice, the first black-box, image-agnostic red-teaming method for SIDs, based on an observed distribution shift in the T2I latent space between samples correctly and incorrectly classified by the SID. PolyJuice generates attacks by (i) identifying the direction of this shift through a lightweight offline process that only requires black-box access to the SID, and (ii) exploiting this direction by universally steering all generated images towards the SID's failure modes. PolyJuice-steered T2I models are significantly more effective at deceiving SIDs (up to 84%) compared to their unsteered counterparts. We also show that the steering directions can be estimated efficiently at lower resolutions and transferred to higher resolutions using simple interpolation, reducing computational overhead. Finally, tuning SID models on PolyJuice-augmented datasets notably enhances the performance of the detectors (up to 30%).
Variational Autoencoding Neural Operators
Feb 20, 2023



Unsupervised learning with functional data is an emerging paradigm of machine learning research with applications to computer vision, climate modeling and physical systems. A natural way of modeling functional data is by learning operators between infinite dimensional spaces, leading to discretization invariant representations that scale independently of the sample grid resolution. Here we present Variational Autoencoding Neural Operators (VANO), a general strategy for making a large class of operator learning architectures act as variational autoencoders. For this purpose, we provide a novel rigorous mathematical formulation of the variational objective in function spaces for training. VANO first maps an input function to a distribution over a latent space using a parametric encoder and then decodes a sample from the latent distribution to reconstruct the input, as in classic variational autoencoders. We test VANO with different model set-ups and architecture choices for a variety of benchmarks. We start from a simple Gaussian random field where we can analytically track what the model learns and progressively transition to more challenging benchmarks including modeling phase separation in Cahn-Hilliard systems and real world satellite data for measuring Earth surface deformation.
Random Weight Factorization Improves the Training of Continuous Neural Representations
Oct 05, 2022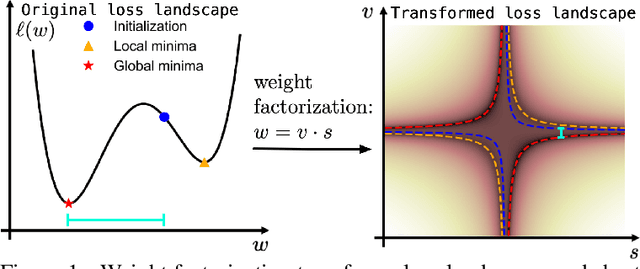
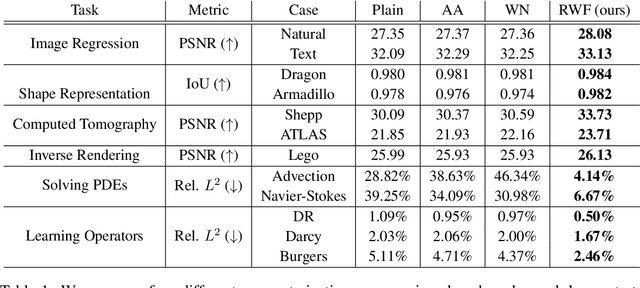
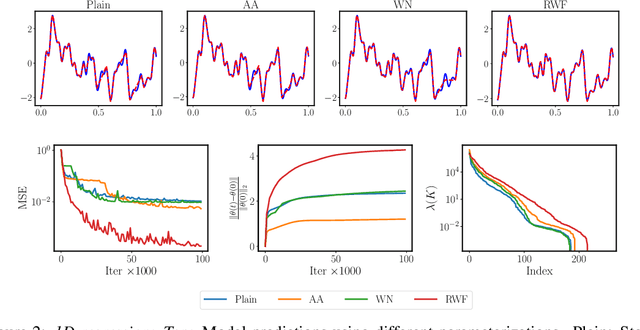
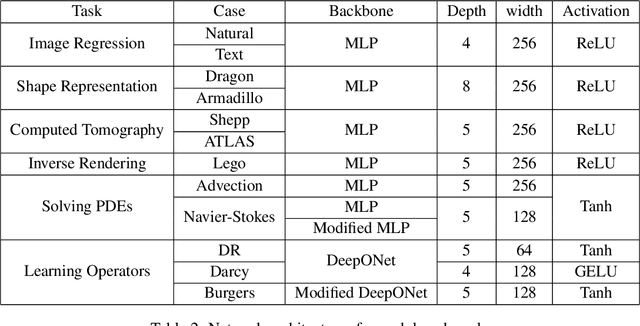
Continuous neural representations have recently emerged as a powerful and flexible alternative to classical discretized representations of signals. However, training them to capture fine details in multi-scale signals is difficult and computationally expensive. Here we propose random weight factorization as a simple drop-in replacement for parameterizing and initializing conventional linear layers in coordinate-based multi-layer perceptrons (MLPs) that significantly accelerates and improves their training. We show how this factorization alters the underlying loss landscape and effectively enables each neuron in the network to learn using its own self-adaptive learning rate. This not only helps with mitigating spectral bias, but also allows networks to quickly recover from poor initializations and reach better local minima. We demonstrate how random weight factorization can be leveraged to improve the training of neural representations on a variety of tasks, including image regression, shape representation, computed tomography, inverse rendering, solving partial differential equations, and learning operators between function spaces.
NOMAD: Nonlinear Manifold Decoders for Operator Learning
Jun 07, 2022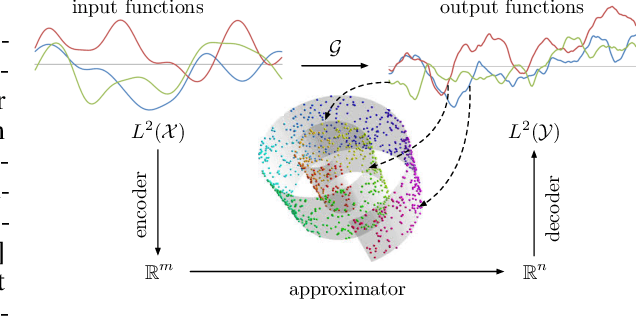

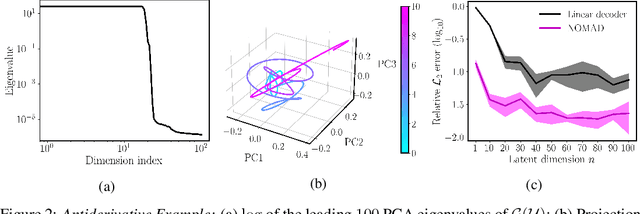

Supervised learning in function spaces is an emerging area of machine learning research with applications to the prediction of complex physical systems such as fluid flows, solid mechanics, and climate modeling. By directly learning maps (operators) between infinite dimensional function spaces, these models are able to learn discretization invariant representations of target functions. A common approach is to represent such target functions as linear combinations of basis elements learned from data. However, there are simple scenarios where, even though the target functions form a low dimensional submanifold, a very large number of basis elements is needed for an accurate linear representation. Here we present NOMAD, a novel operator learning framework with a nonlinear decoder map capable of learning finite dimensional representations of nonlinear submanifolds in function spaces. We show this method is able to accurately learn low dimensional representations of solution manifolds to partial differential equations while outperforming linear models of larger size. Additionally, we compare to state-of-the-art operator learning methods on a complex fluid dynamics benchmark and achieve competitive performance with a significantly smaller model size and training cost.
Robust Deep Learning as Optimal Control: Insights and Convergence Guarantees
May 01, 2020
The fragility of deep neural networks to adversarially-chosen inputs has motivated the need to revisit deep learning algorithms. Including adversarial examples during training is a popular defense mechanism against adversarial attacks. This mechanism can be formulated as a min-max optimization problem, where the adversary seeks to maximize the loss function using an iterative first-order algorithm while the learner attempts to minimize it. However, finding adversarial examples in this way causes excessive computational overhead during training. By interpreting the min-max problem as an optimal control problem, it has recently been shown that one can exploit the compositional structure of neural networks in the optimization problem to improve the training time significantly. In this paper, we provide the first convergence analysis of this adversarial training algorithm by combining techniques from robust optimal control and inexact oracle methods in optimization. Our analysis sheds light on how the hyperparameters of the algorithm affect the its stability and convergence. We support our insights with experiments on a robust classification problem.