 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanana: Compute-efficient Bilingual Language Models
Feb 26, 2025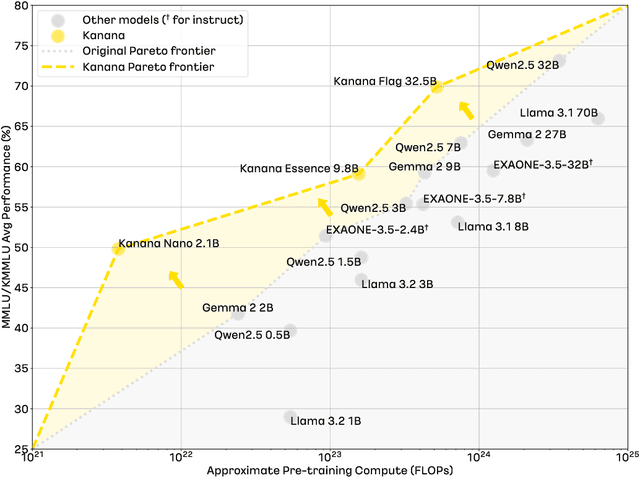



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
Class Granularity: How richly does your knowledge graph represent the real world?
Nov 10, 2024



To effectively manage and utilize knowledge graphs, it is crucial to have metrics that can assess the quality of knowledge graphs from various perspectives. While there have been studies on knowledge graph quality metrics, there has been a lack of research on metrics that measure how richly ontologies, which form the backbone of knowledge graphs, are defined or the impact of richly defined ontologies. In this study, we propose a new metric called Class Granularity, which measures how well a knowledge graph is structured in terms of how finely classes with unique characteristics are defined. Furthermore, this research presents potential impact of Class Granularity in knowledge graph's on downstream tasks. In particular, we explore its influence on graph embedding and provide experimental results. Additionally, this research goes beyond traditional Linked Open Data comparison studies, which mainly focus on factors like scale and class distribution, by using Class Granularity to compare four different LOD sources.
Structural Quality Metrics to Evaluate Knowledge Graphs
Dec 09, 2022This work presents six structural quality metrics that can measure the quality of knowledge graphs and analyzes five cross-domain knowledge graphs on the web (Wikidata, DBpedia, YAGO, Google Knowledge Graph, Freebase) as well as 'Raftel', Naver's integrated knowledge graph. The 'Good Knowledge Graph' should define detailed classes and properties in its ontology so that knowledge in the real world can be expressed abundantly. Also, instances and RDF triples should use the classes and properties actively. Therefore, we tried to examine the internal quality of knowledge graphs numerically by focusing on the structure of the ontology, which is the schema of knowledge graphs, and the degree of use thereof. As a result of the analysis, it was possible to find the characteristics of a knowledge graph that could not be known only by scale-related indicators such as the number of classes and properties.