 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodic Clustering for Phoneme-level Prosody Control in End-to-End Speech Synthesis
Nov 19, 2021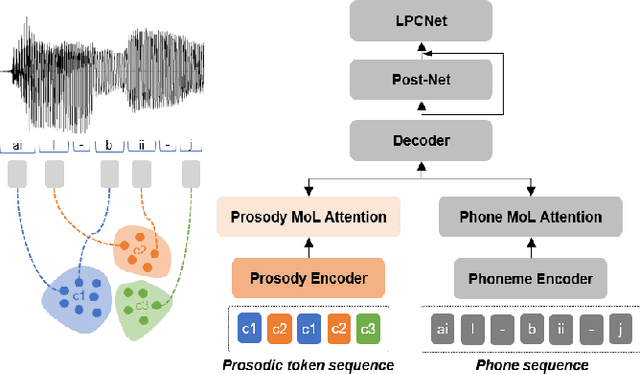
This paper presents a method for controlling the prosody at the phoneme level in an autoregressive attention-based text-to-speech system. Instead of learning latent prosodic features with a variational framework as is commonly done, we directly extract phoneme-level F0 and duration features from the speech data in the training set. Each prosodic feature is discretized using unsupervised clustering in order to produce a sequence of prosodic labels for each utterance. This sequence is used in parallel to the phoneme sequence in order to condition the decoder with the utilization of a prosodic encoder and a corresponding attention module. Experimental results show that the proposed method retains the high quality of generated speech, while allowing phoneme-level control of F0 and duration. By replacing the F0 cluster centroids with musical notes, the model can also provide control over the note and octave within the range of the speaker.
Word-Level Style Control for Expressive, Non-attentive Speech Synthesis
Nov 19, 2021

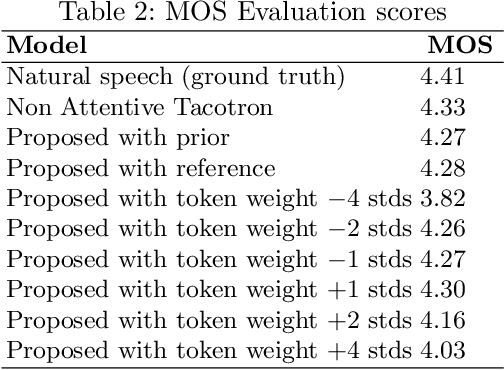
This paper presents an expressive speech synthesis architecture for modeling and controlling the speaking style at a word level. It attempts to learn word-level stylistic and prosodic representations of the speech data, with the aid of two encoders. The first one models style by finding a combination of style tokens for each word given the acoustic features, and the second outputs a word-level sequence conditioned only on the phonetic information in order to disentangle it from the style information. The two encoder outputs are aligned and concatenated with the phoneme encoder outputs and then decoded with a Non-Attentive Tacotron model. An extra prior encoder is used to predict the style tokens autoregressively, in order for the model to be able to run without a reference utterance. We find that the resulting model gives both word-level and global control over the style, as well as prosody transfer capabilities.
Improved Prosodic Clustering for Multispeaker and Speaker-independent Phoneme-level Prosody Control
Nov 19, 2021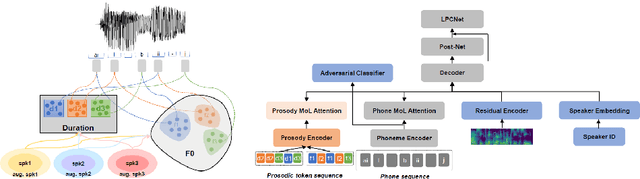
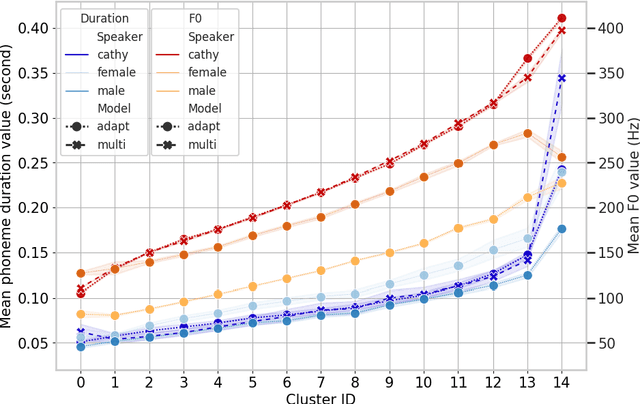
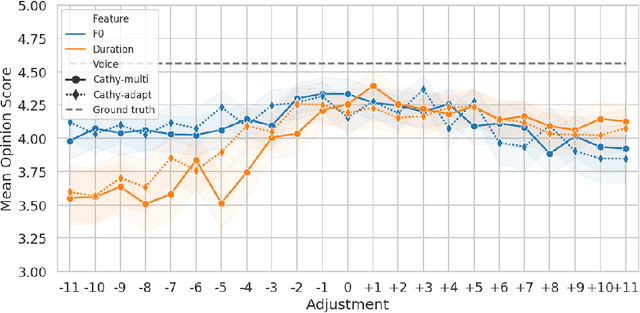
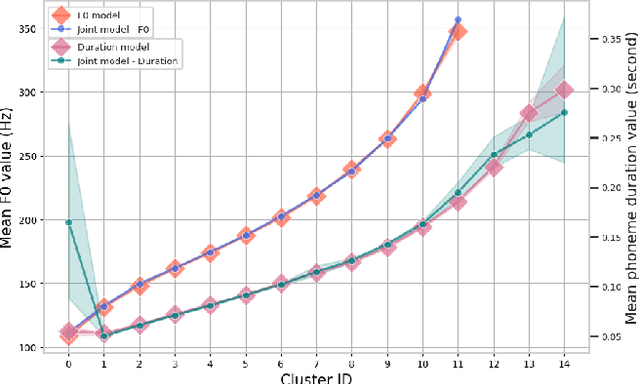
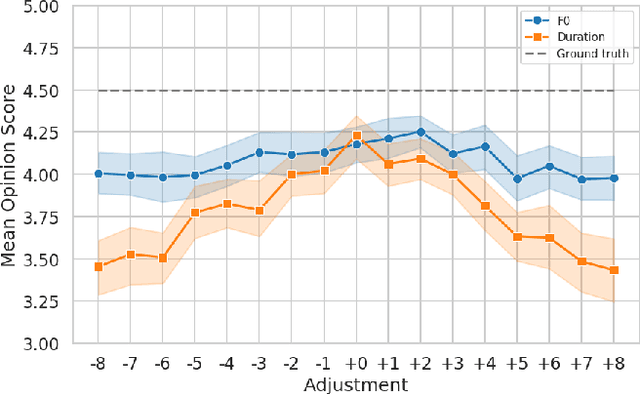
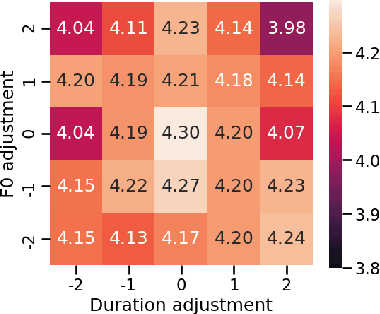
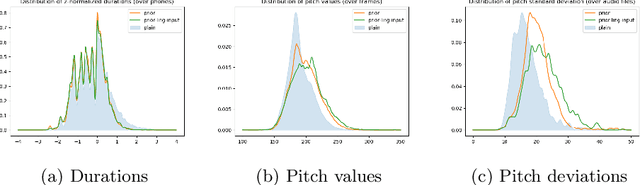
This paper presents a method for phoneme-level prosody control of F0 and duration on a multispeaker text-to-speech setup, which is based on prosodic clustering. An autoregressive attention-based model is used, incorporating multispeaker architecture modules in parallel to a prosody encoder. Several improvements over the basic single-speaker method are proposed that increase the prosodic control range and coverage. More specifically we employ data augmentation, F0 normalization, balanced clustering for duration, and speaker-independent prosodic clustering. These modifications enable fine-grained phoneme-level prosody control for all speakers contained in the training set, while maintaining the speaker identity. The model is also fine-tuned to unseen speakers with limited amounts of data and it is shown to maintain its prosody control capabilities, verifying that the speaker-independent prosodic clustering is effective. Experimental results verify that the model maintains high output speech quality and that the proposed method allows efficient prosody control within each speaker's range despite the variability that a multispeaker setting introduces.
Rapping-Singing Voice Synthesis based on Phoneme-level Prosody Control
Nov 17, 2021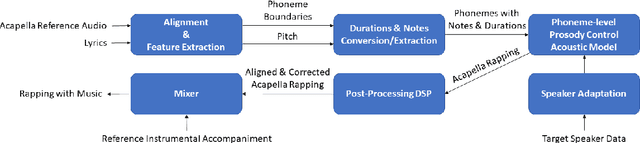
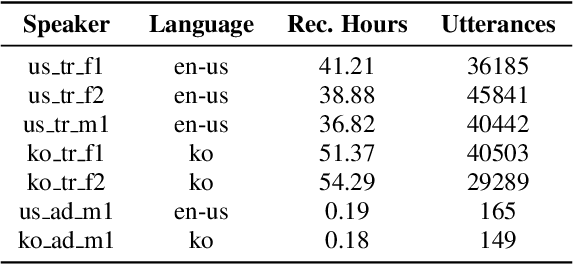
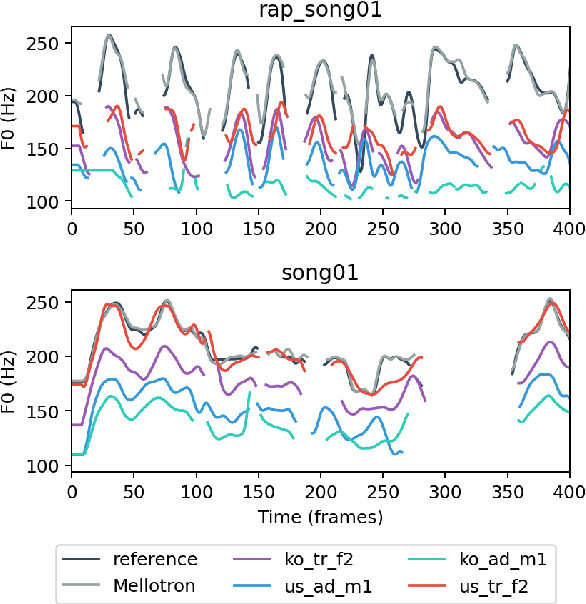
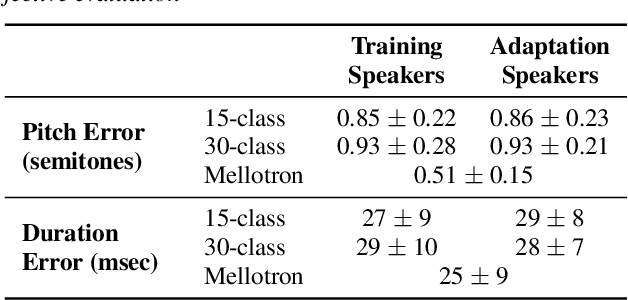
In this paper, a text-to-rapping/singing system is introduced, which can be adapted to any speaker's voice. It utilizes a Tacotron-based multispeaker acoustic model trained on read-only speech data and which provides prosody control at the phoneme level. Dataset augmentation and additional prosody manipulation based on traditional DSP algorithms are also investigated. The neural TTS model is fine-tuned to an unseen speaker's limited recordings, allowing rapping/singing synthesis with the target's speaker voice. The detailed pipeline of the system is described, which includes the extraction of the target pitch and duration values from an a capella song and their conversion into target speaker's valid range of notes before synthesis. An additional stage of prosodic manipulation of the output via WSOLA is also investigated for better matching the target duration values. The synthesized utterances can be mixed with an instrumental accompaniment track to produce a complete song. The proposed system is evaluated via subjective listening tests as well as in comparison to an available alternate system which also aims to produce synthetic singing voice from read-only training data. Results show that the proposed approach can produce high quality rapping/singing voice with increased naturalness.
Cross-lingual Low Resource Speaker Adaptation Using Phonological Features
Nov 17, 2021

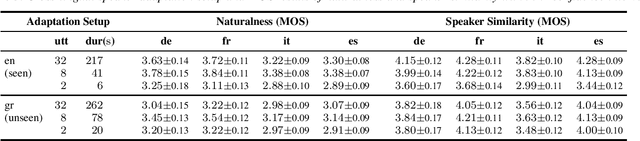
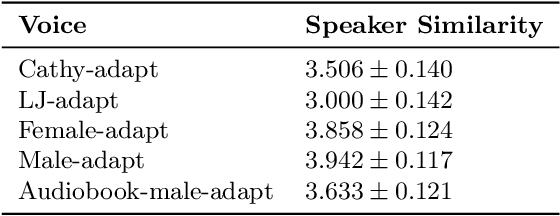
The idea of using phonological features instead of phonemes as input to sequence-to-sequence TTS has been recently proposed for zero-shot multilingual speech synthesis. This approach is useful for code-switching, as it facilitates the seamless uttering of foreign text embedded in a stream of native text. In our work, we train a language-agnostic multispeaker model conditioned on a set of phonologically derived features common across different languages, with the goal of achieving cross-lingual speaker adaptation. We first experiment with the effect of language phonological similarity on cross-lingual TTS of several source-target language combinations. Subsequently, we fine-tune the model with very limited data of a new speaker's voice in either a seen or an unseen language, and achieve synthetic speech of equal quality, while preserving the target speaker's identity. With as few as 32 and 8 utterances of target speaker data, we obtain high speaker similarity scores and naturalness comparable to the corresponding literature. In the extreme case of only 2 available adaptation utterances, we find that our model behaves as a few-shot learner, as the performance is similar in both the seen and unseen adaptation language scenarios.
High Quality Streaming Speech Synthesis with Low, Sentence-Length-Independent Latency
Nov 17, 2021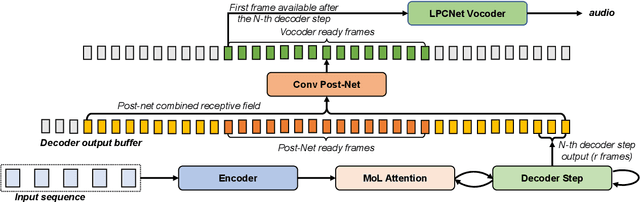
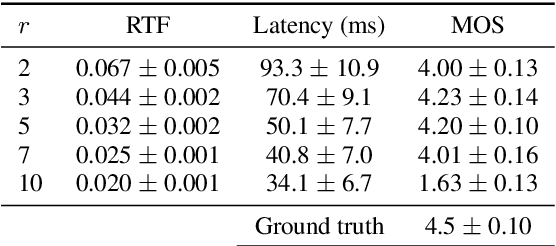
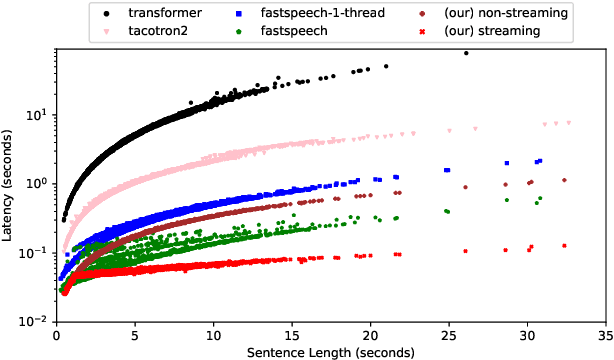
This paper presents an end-to-end text-to-speech system with low latency on a CPU, suitable for real-time applications. The system is composed of an autoregressive attention-based sequence-to-sequence acoustic model and the LPCNet vocoder for waveform generation. An acoustic model architecture that adopts modules from both the Tacotron 1 and 2 models is proposed, while stability is ensured by using a recently proposed purely location-based attention mechanism, suitable for arbitrary sentence length generation. During inference, the decoder is unrolled and acoustic feature generation is performed in a streaming manner, allowing for a nearly constant latency which is independent from the sentence length. Experimental results show that the acoustic model can produce feature sequences with minimal latency about 31 times faster than real-time on a computer CPU and 6.5 times on a mobile CPU, enabling it to meet the conditions required for real-time applications on both devices. The full end-to-end system can generate almost natural quality speech, which is verified by listening tests.