 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Low Resource Speaker Adaptation Using Phonological Features
Paper and Code


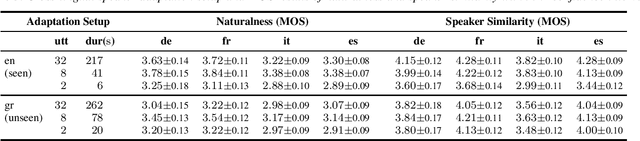
The idea of using phonological features instead of phonemes as input to sequence-to-sequence TTS has been recently proposed for zero-shot multilingual speech synthesis. This approach is useful for code-switching, as it facilitates the seamless uttering of foreign text embedded in a stream of native text. In our work, we train a language-agnostic multispeaker model conditioned on a set of phonologically derived features common across different languages, with the goal of achieving cross-lingual speaker adaptation. We first experiment with the effect of language phonological similarity on cross-lingual TTS of several source-target language combinations. Subsequently, we fine-tune the model with very limited data of a new speaker's voice in either a seen or an unseen language, and achieve synthetic speech of equal quality, while preserving the target speaker's identity. With as few as 32 and 8 utterances of target speaker data, we obtain high speaker similarity scores and naturalness comparable to the corresponding literature. In the extreme case of only 2 available adaptation utterances, we find that our model behaves as a few-shot learner, as the performance is similar in both the seen and unseen adaptation language scenarios.