 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Prosodic Clustering for Multispeaker and Speaker-independent Phoneme-level Prosody Control
Paper and Code
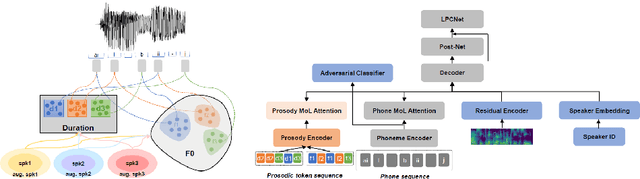
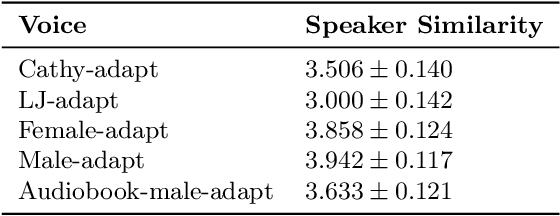
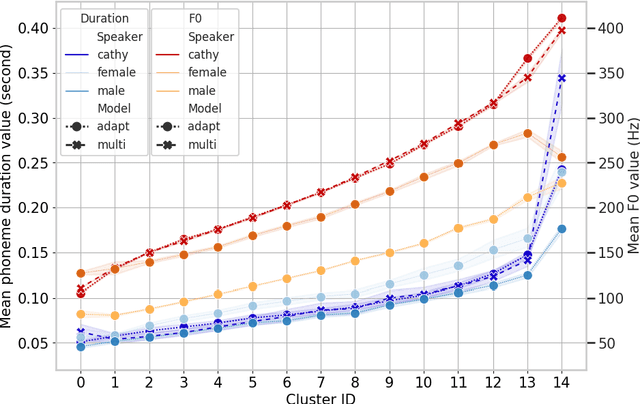
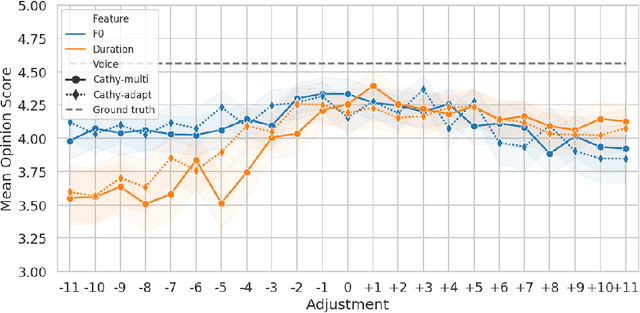
This paper presents a method for phoneme-level prosody control of F0 and duration on a multispeaker text-to-speech setup, which is based on prosodic clustering. An autoregressive attention-based model is used, incorporating multispeaker architecture modules in parallel to a prosody encoder. Several improvements over the basic single-speaker method are proposed that increase the prosodic control range and coverage. More specifically we employ data augmentation, F0 normalization, balanced clustering for duration, and speaker-independent prosodic clustering. These modifications enable fine-grained phoneme-level prosody control for all speakers contained in the training set, while maintaining the speaker identity. The model is also fine-tuned to unseen speakers with limited amounts of data and it is shown to maintain its prosody control capabilities, verifying that the speaker-independent prosodic clustering is effective. Experimental results verify that the model maintains high output speech quality and that the proposed method allows efficient prosody control within each speaker's range despite the variability that a multispeaker setting introduces.