 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-Level Style Control for Expressive, Non-attentive Speech Synthesis
Paper and Code


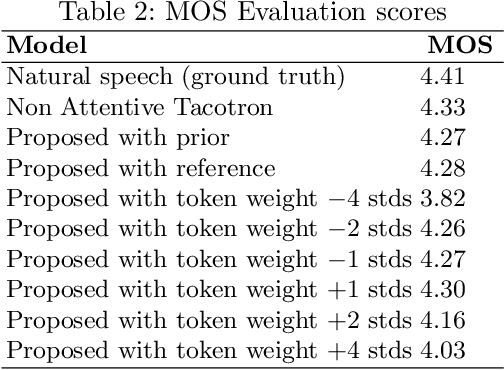
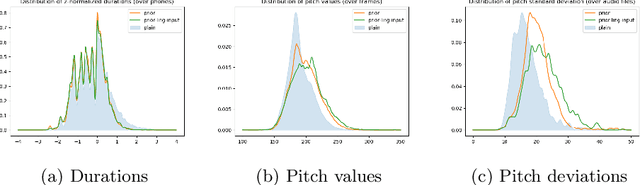
This paper presents an expressive speech synthesis architecture for modeling and controlling the speaking style at a word level. It attempts to learn word-level stylistic and prosodic representations of the speech data, with the aid of two encoders. The first one models style by finding a combination of style tokens for each word given the acoustic features, and the second outputs a word-level sequence conditioned only on the phonetic information in order to disentangle it from the style information. The two encoder outputs are aligned and concatenated with the phoneme encoder outputs and then decoded with a Non-Attentive Tacotron model. An extra prior encoder is used to predict the style tokens autoregressively, in order for the model to be able to run without a reference utterance. We find that the resulting model gives both word-level and global control over the style, as well as prosody transfer capabilities.