 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptRad: Knowledge-Enhanced Multi-Label Prompt-Tuning for Low-Resource Radiology Report Labeling
May 20, 2026Automatic report labeling facilitates the identification of clinical findings from unstructured text and enables large-scale annotation for medical imaging research. Existing rule-based labelers struggle with the diverse descriptions in clinical reports, while fine-tuning pre-trained language models (PLMs) requires large amounts of labeled data that are often unavailable in clinical settings. In this paper, we propose PromptRad, a knowledge-enhanced multi-label \textbf{prompt}-tuning approach for \textbf{rad}iology report labeling under low-resource settings. PromptRad reformulates multi-label classification as masked language modeling and incorporates synonyms from the UMLS Metathesaurus into a multi-word verbalizer to enrich category representations. By fine-tuning the PLM without additional classification layers, PromptRad requires substantially less labeled data than conventional fine-tuning. Experiments on liver CT (computed tomography) reports show that PromptRad outperforms dictionary-based and fine-tuning baselines with only 32 labeled training examples, and achieves competitive performance with GPT-4 despite using a much smaller model. Further analysis demonstrates that PromptRad captures complex negation patterns more effectively than existing methods, making it a promising solution for report labeling in data-scarce clinical scenarios. Our code is available at https://github.com/ila-lab/PromptRad.
SCURank: Ranking Multiple Candidate Summaries with Summary Content Units for Enhanced Summarization
Apr 21, 2026Small language models (SLMs), such as BART, can achieve summarization performance comparable to large language models (LLMs) via distillation. However, existing LLM-based ranking strategies for summary candidates suffer from instability, while classical metrics (e.g., ROUGE) are insufficient to rank high-quality summaries. To address these issues, we introduce \textbf{SCURank}, a framework that enhances summarization by leveraging \textbf{Summary Content Units (SCUs)}. Instead of relying on unstable comparisons or surface-level overlap, SCURank evaluates summaries based on the richness and semantic importance of information content. We investigate the effectiveness of SCURank in distilling summaries from multiple diverse LLMs. Experimental results demonstrate that SCURank outperforms traditional metrics and LLM-based ranking methods across evaluation measures and datasets. Furthermore, our findings show that incorporating diverse LLM summaries enhances model abstractiveness and overall distilled model performance, validating the benefits of information-centric ranking in multi-LLM distillation. The code for SCURank is available at https://github.com/IKMLab/SCURank.
From Persona to Person: Enhancing the Naturalness with Multiple Discourse Relations Graph Learning in Personalized Dialogue Generation
Jun 13, 2025In dialogue generation, the naturalness of responses is crucial for effective human-machine interaction. Personalized response generation poses even greater challenges, as the responses must remain coherent and consistent with the user's personal traits or persona descriptions. We propose MUDI ($\textbf{Mu}$ltiple $\textbf{Di}$scourse Relations Graph Learning) for personalized dialogue generation. We utilize a Large Language Model to assist in annotating discourse relations and to transform dialogue data into structured dialogue graphs. Our graph encoder, the proposed DialogueGAT model, then captures implicit discourse relations within this structure, along with persona descriptions. During the personalized response generation phase, novel coherence-aware attention strategies are implemented to enhance the decoder's consideration of discourse relations. Our experiments demonstrate significant improvements in the quality of personalized responses, thus resembling human-like dialogue exchanges.
MAPLE: Enhancing Review Generation with Multi-Aspect Prompt LEarning in Explainable Recommendation
Aug 19, 2024



Explainable Recommendation task is designed to receive a pair of user and item and output explanations to justify why an item is recommended to a user. Many models treat review-generation as a proxy of explainable recommendation. Although they are able to generate fluent and grammatical sentences, they suffer from generality and hallucination issues. We propose a personalized, aspect-controlled model called Multi-Aspect Prompt LEarner (MAPLE), in which it integrates aspect category as another input dimension to facilitate the memorization of fine-grained aspect terms. Experiments on two real-world review datasets in restaurant domain show that MAPLE outperforms the baseline review-generation models in terms of text and feature diversity while maintaining excellent coherence and factual relevance. We further treat MAPLE as a retriever component in the retriever-reader framework and employ a Large-Language Model (LLM) as the reader, showing that MAPLE's explanation along with the LLM's comprehension ability leads to enriched and personalized explanation as a result. We will release the code and data in this http upon acceptance.
CFEVER: A Chinese Fact Extraction and VERification Dataset
Feb 20, 2024We present CFEVER, a Chinese dataset designed for Fact Extraction and VERification. CFEVER comprises 30,012 manually created claims based on content in Chinese Wikipedia. Each claim in CFEVER is labeled as "Supports", "Refutes", or "Not Enough Info" to depict its degree of factualness. Similar to the FEVER dataset, claims in the "Supports" and "Refutes" categories are also annotated with corresponding evidence sentences sourced from single or multiple pages in Chinese Wikipedia. Our labeled dataset holds a Fleiss' kappa value of 0.7934 for five-way inter-annotator agreement. In addition, through the experiments with the state-of-the-art approaches developed on the FEVER dataset and a simple baseline for CFEVER, we demonstrate that our dataset is a new rigorous benchmark for factual extraction and verification, which can be further used for developing automated systems to alleviate human fact-checking efforts. CFEVER is available at https://ikmlab.github.io/CFEVER.
ELECTRA is a Zero-Shot Learner, Too
Jul 20, 2022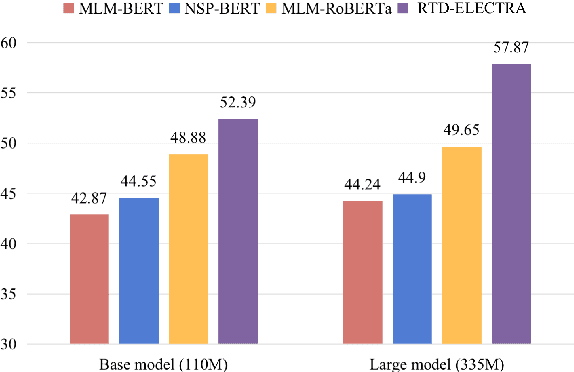

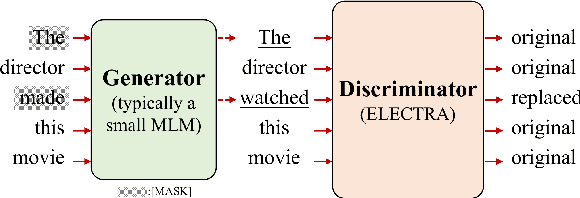
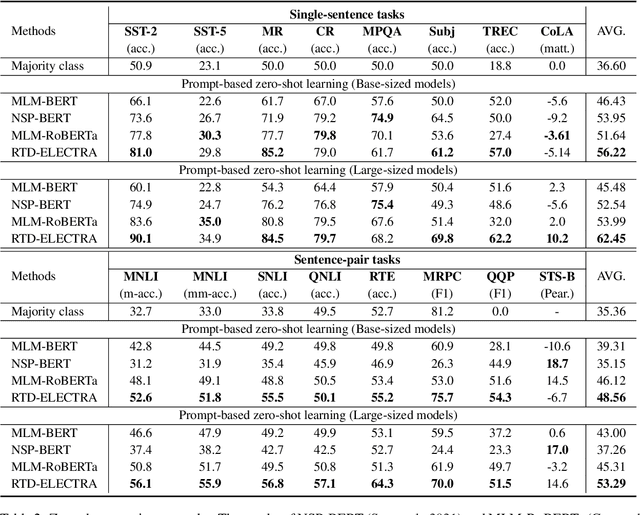
Recently, for few-shot or even zero-shot learning, the new paradigm "pre-train, prompt, and predict" has achieved remarkable achievements compared with the "pre-train, fine-tune" paradigm. After the success of prompt-based GPT-3, a series of masked language model (MLM)-based (e.g., BERT, RoBERTa) prompt learning methods became popular and widely used. However, another efficient pre-trained discriminative model, ELECTRA, has probably been neglected. In this paper, we attempt to accomplish several NLP tasks in the zero-shot scenario using a novel our proposed replaced token detection (RTD)-based prompt learning method. Experimental results show that ELECTRA model based on RTD-prompt learning achieves surprisingly state-of-the-art zero-shot performance. Numerically, compared to MLM-RoBERTa-large and MLM-BERT-large, our RTD-ELECTRA-large has an average of about 8.4% and 13.7% improvement on all 15 tasks. Especially on the SST-2 task, our RTD-ELECTRA-large achieves an astonishing 90.1% accuracy without any training data. Overall, compared to the pre-trained masked language models, the pre-trained replaced token detection model performs better in zero-shot learning. The source code is available at: https://github.com/nishiwen1214/RTD-ELECTRA.
True or False: Does the Deep Learning Model Learn to Detect Rumors?
Dec 01, 2021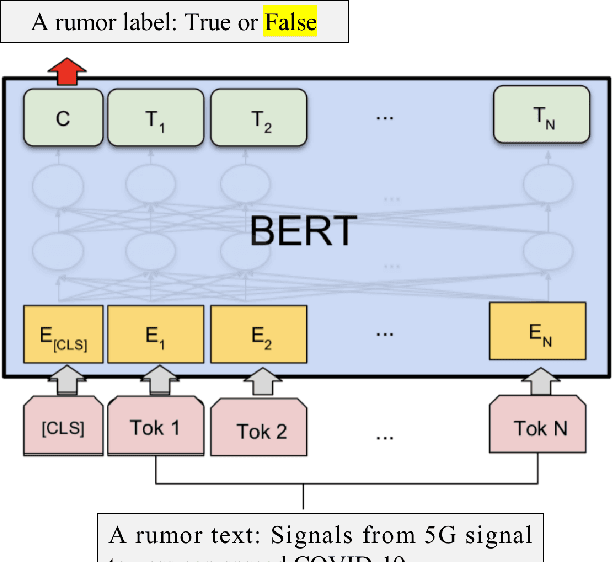
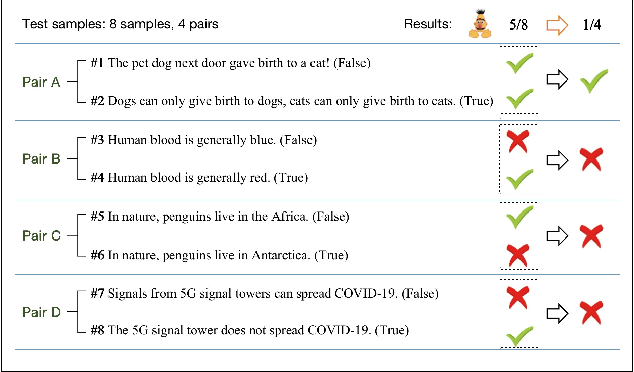

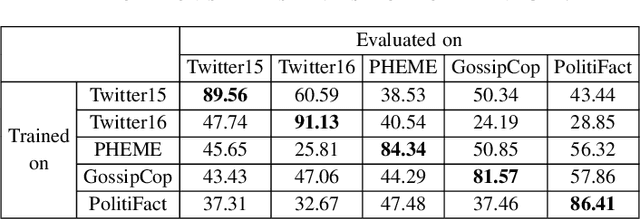
It is difficult for humans to distinguish the true and false of rumors, but current deep learning models can surpass humans and achieve excellent accuracy on many rumor datasets. In this paper, we investigate whether deep learning models that seem to perform well actually learn to detect rumors. We evaluate models on their generalization ability to out-of-domain examples by fine-tuning BERT-based models on five real-world datasets and evaluating against all test sets. The experimental results indicate that the generalization ability of the models on other unseen datasets are unsatisfactory, even common-sense rumors cannot be detected. Moreover, we found through experiments that models take shortcuts and learn absurd knowledge when the rumor datasets have serious data pitfalls. This means that simple modifications to the rumor text based on specific rules will lead to inconsistent model predictions. To more realistically evaluate rumor detection models, we proposed a new evaluation method called paired test (PairT), which requires models to correctly predict a pair of test samples at the same time. Furthermore, we make recommendations on how to better create rumor dataset and evaluate rumor detection model at the end of this paper.
DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks
Aug 29, 2021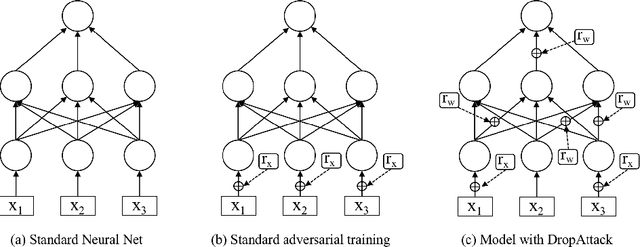
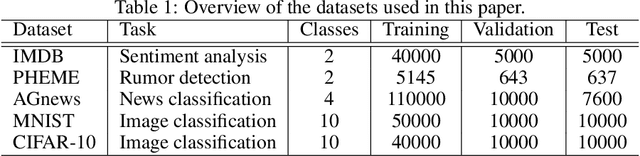
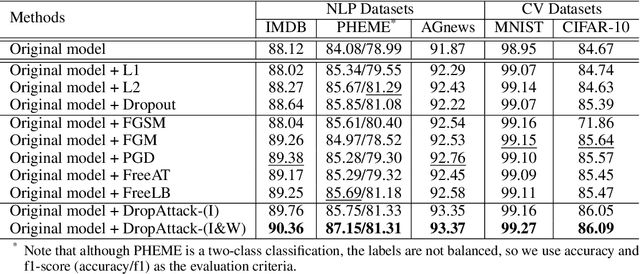
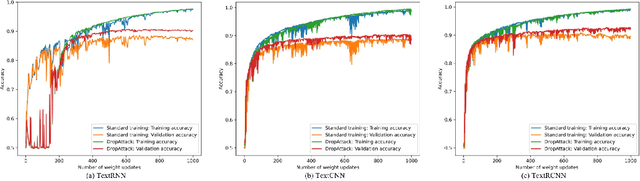
Adversarial training has been proven to be a powerful regularization method to improve the generalization of models. However, current adversarial training methods only attack the original input sample or the embedding vectors, and their attacks lack coverage and diversity. To further enhance the breadth and depth of attack, we propose a novel masked weight adversarial training method called DropAttack, which enhances generalization of model by adding intentionally worst-case adversarial perturbations to both the input and hidden layers in different dimensions and minimize the adversarial risks generated by each layer. DropAttack is a general technique and can be adopt to a wide variety of neural networks with different architectures. To validate the effectiveness of the proposed method, we used five public datasets in the fields of natural language processing (NLP) and computer vision (CV) for experimental evaluating. We compare the proposed method with other adversarial training methods and regularization methods, and our method achieves state-of-the-art on all datasets. In addition, Dropattack can achieve the same performance when it use only a half training data compared to other standard training method. Theoretical analysis reveals that DropAttack can perform gradient regularization at random on some of the input and wight parameters of the model. Further visualization experiments show that DropAttack can push the minimum risk of the model to a lower and flatter loss landscapes. Our source code is publicly available on https://github.com/nishiwen1214/DropAttack.
Rumor Detection on Twitter Using Multiloss Hierarchical BiLSTM with an Attenuation Factor
Oct 31, 2020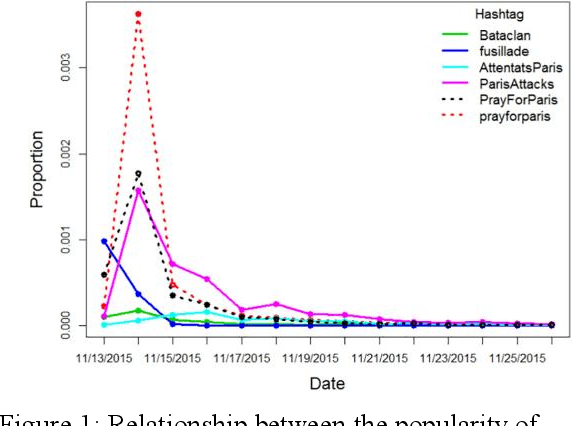
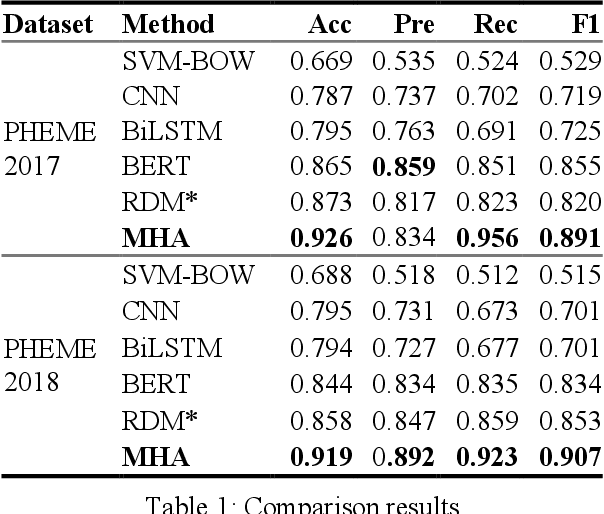
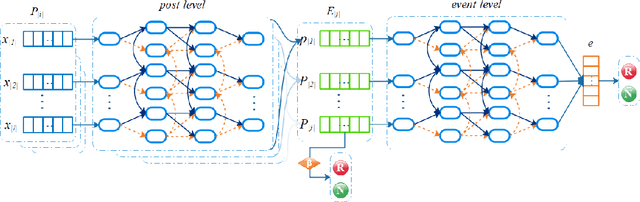

Social media platforms such as Twitter have become a breeding ground for unverified information or rumors. These rumors can threaten people's health, endanger the economy, and affect the stability of a country. Many researchers have developed models to classify rumors using traditional machine learning or vanilla deep learning models. However, previous studies on rumor detection have achieved low precision and are time consuming. Inspired by the hierarchical model and multitask learning, a multiloss hierarchical BiLSTM model with an attenuation factor is proposed in this paper. The model is divided into two BiLSTM modules: post level and event level. By means of this hierarchical structure, the model can extract deep in-formation from limited quantities of text. Each module has a loss function that helps to learn bilateral features and reduce the training time. An attenuation fac-tor is added at the post level to increase the accuracy. The results on two rumor datasets demonstrate that our model achieves better performance than that of state-of-the-art machine learning and vanilla deep learning models.
Probing Neural Network Comprehension of Natural Language Arguments
Jul 17, 2019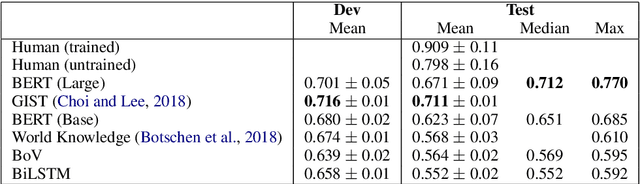
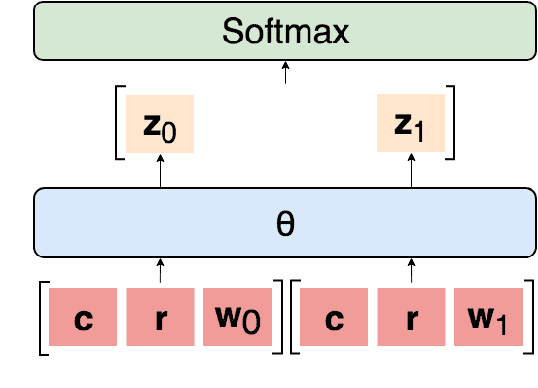

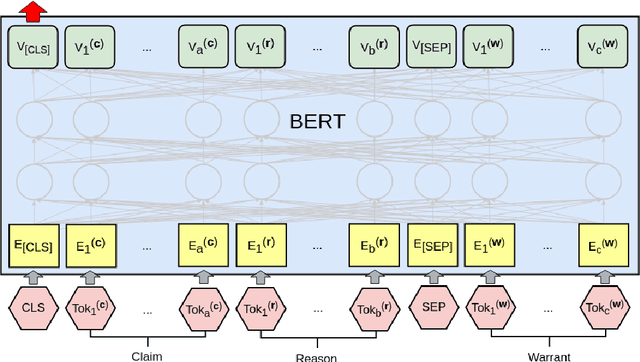
We are surprised to find that BERT's peak performance of 77% on the Argument Reasoning Comprehension Task reaches just three points below the average untrained human baseline. However, we show that this result is entirely accounted for by exploitation of spurious statistical cues in the dataset. We analyze the nature of these cues and demonstrate that a range of models all exploit them. This analysis informs the construction of an adversarial dataset on which all models achieve random accuracy. Our adversarial dataset provides a more robust assessment of argument comprehension and should be adopted as the standard in future work.