 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Neural Network Comprehension of Natural Language Arguments
Jul 17, 2019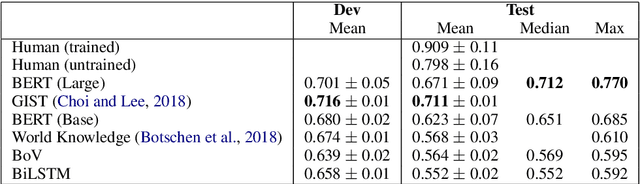
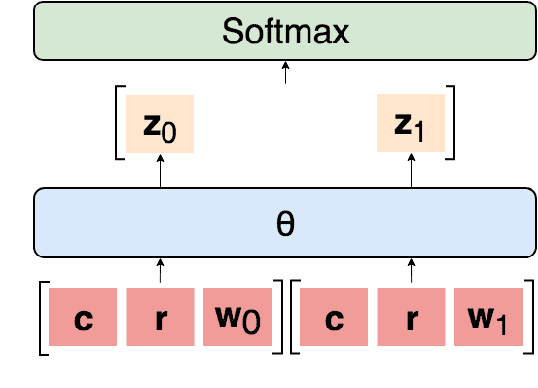

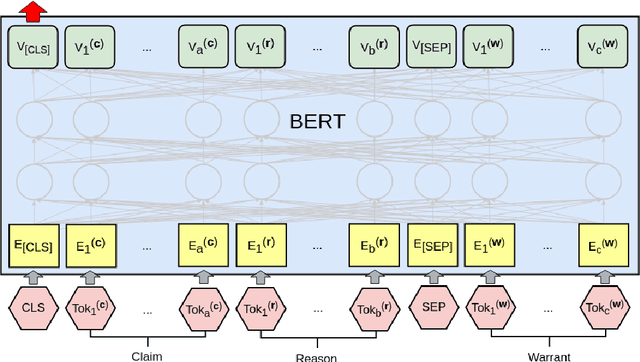
We are surprised to find that BERT's peak performance of 77% on the Argument Reasoning Comprehension Task reaches just three points below the average untrained human baseline. However, we show that this result is entirely accounted for by exploitation of spurious statistical cues in the dataset. We analyze the nature of these cues and demonstrate that a range of models all exploit them. This analysis informs the construction of an adversarial dataset on which all models achieve random accuracy. Our adversarial dataset provides a more robust assessment of argument comprehension and should be adopted as the standard in future work.
Fake News Detection as Natural Language Inference
Jul 17, 2019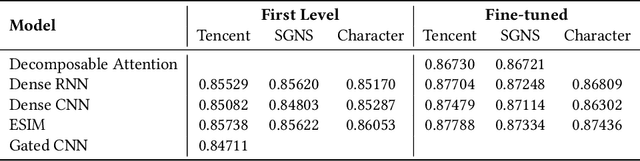

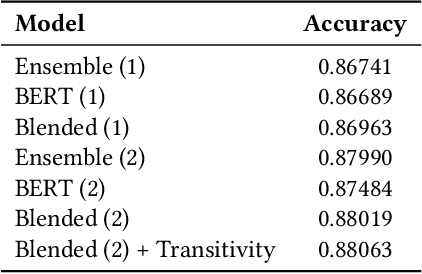
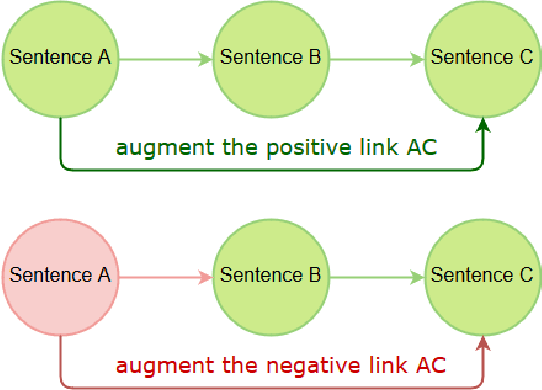
This report describes the entry by the Intelligent Knowledge Management (IKM) Lab in the WSDM 2019 Fake News Classification challenge. We treat the task as natural language inference (NLI). We individually train a number of the strongest NLI models as well as BERT. We ensemble these results and retrain with noisy labels in two stages. We analyze transitivity relations in the train and test sets and determine a set of test cases that can be reliably classified on this basis. The remainder of test cases are classified by our ensemble. Our entry achieves test set accuracy of 88.063% for 3rd place in the competition.