 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrue or False: Does the Deep Learning Model Learn to Detect Rumors?
Paper and Code
Dec 01, 2021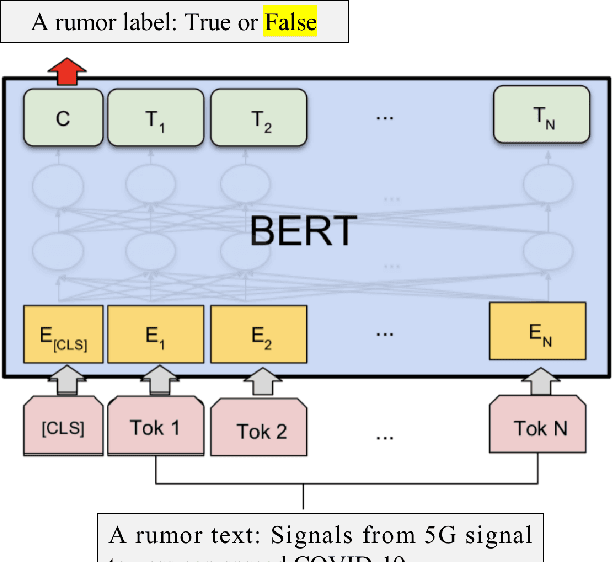
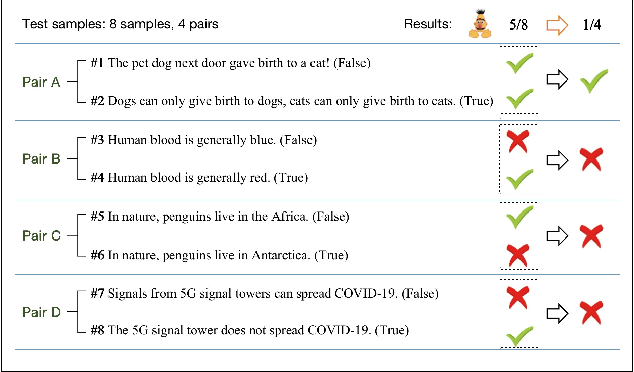

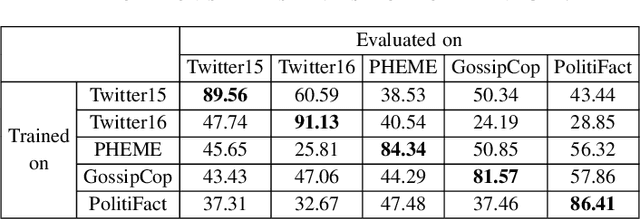
It is difficult for humans to distinguish the true and false of rumors, but current deep learning models can surpass humans and achieve excellent accuracy on many rumor datasets. In this paper, we investigate whether deep learning models that seem to perform well actually learn to detect rumors. We evaluate models on their generalization ability to out-of-domain examples by fine-tuning BERT-based models on five real-world datasets and evaluating against all test sets. The experimental results indicate that the generalization ability of the models on other unseen datasets are unsatisfactory, even common-sense rumors cannot be detected. Moreover, we found through experiments that models take shortcuts and learn absurd knowledge when the rumor datasets have serious data pitfalls. This means that simple modifications to the rumor text based on specific rules will lead to inconsistent model predictions. To more realistically evaluate rumor detection models, we proposed a new evaluation method called paired test (PairT), which requires models to correctly predict a pair of test samples at the same time. Furthermore, we make recommendations on how to better create rumor dataset and evaluate rumor detection model at the end of this paper.