 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Reasoning Chains for Multi-hop Science Question Answering
Sep 07, 2021

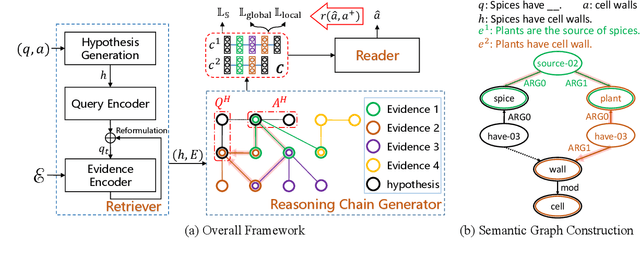
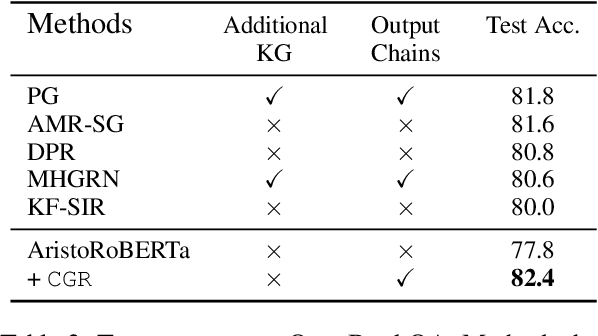
We propose a novel Chain Guided Retriever-reader ({\tt CGR}) framework to model the reasoning chain for multi-hop Science Question Answering. Our framework is capable of performing explainable reasoning without the need of any corpus-specific annotations, such as the ground-truth reasoning chain, or human-annotated entity mentions. Specifically, we first generate reasoning chains from a semantic graph constructed by Abstract Meaning Representation of retrieved evidence facts. A \textit{Chain-aware loss}, concerning both local and global chain information, is also designed to enable the generated chains to serve as distant supervision signals for training the retriever, where reinforcement learning is also adopted to maximize the utility of the reasoning chains. Our framework allows the retriever to capture step-by-step clues of the entire reasoning process, which is not only shown to be effective on two challenging multi-hop Science QA tasks, namely OpenBookQA and ARC-Challenge, but also favors explainability.
Dynamic Semantic Graph Construction and Reasoning for Explainable Multi-hop Science Question Answering
May 25, 2021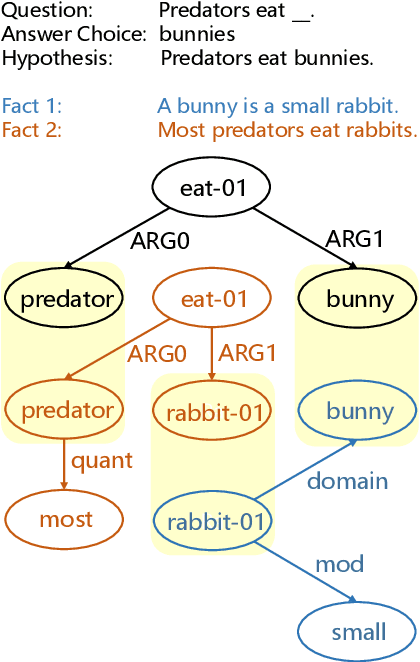

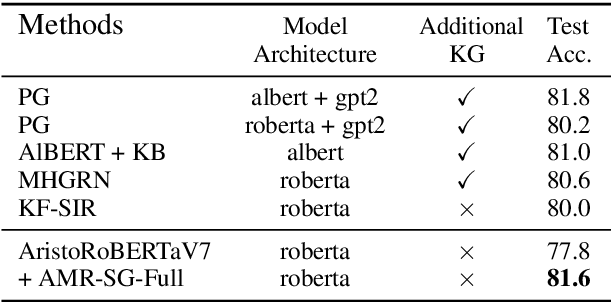
Knowledge retrieval and reasoning are two key stages in multi-hop question answering (QA) at web scale. Existing approaches suffer from low confidence when retrieving evidence facts to fill the knowledge gap and lack transparent reasoning process. In this paper, we propose a new framework to exploit more valid facts while obtaining explainability for multi-hop QA by dynamically constructing a semantic graph and reasoning over it. We employ Abstract Meaning Representation (AMR) as semantic graph representation. Our framework contains three new ideas: (a) {\tt AMR-SG}, an AMR-based Semantic Graph, constructed by candidate fact AMRs to uncover any hop relations among question, answer and multiple facts. (b) A novel path-based fact analytics approach exploiting {\tt AMR-SG} to extract active facts from a large fact pool to answer questions. (c) A fact-level relation modeling leveraging graph convolution network (GCN) to guide the reasoning process. Results on two scientific multi-hop QA datasets show that we can surpass recent approaches including those using additional knowledge graphs while maintaining high explainability on OpenBookQA and achieve a new state-of-the-art result on ARC-Challenge in a computationally practicable setting.
Knowledge Graph Embedding with Atrous Convolution and Residual Learning
Oct 30, 2020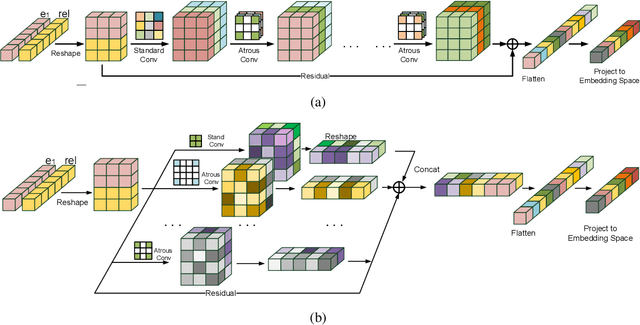
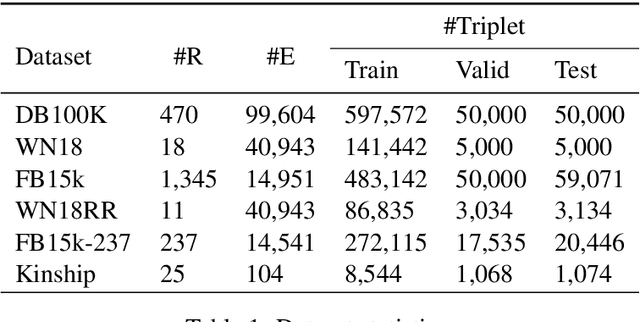
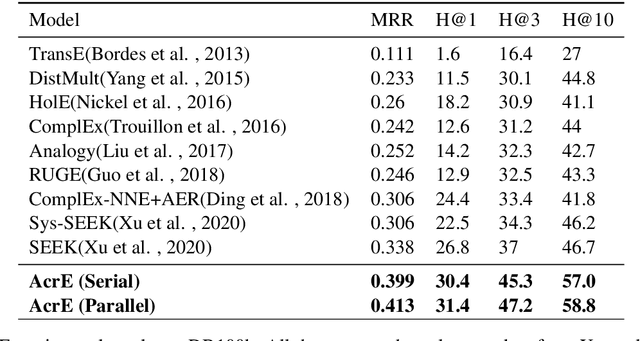
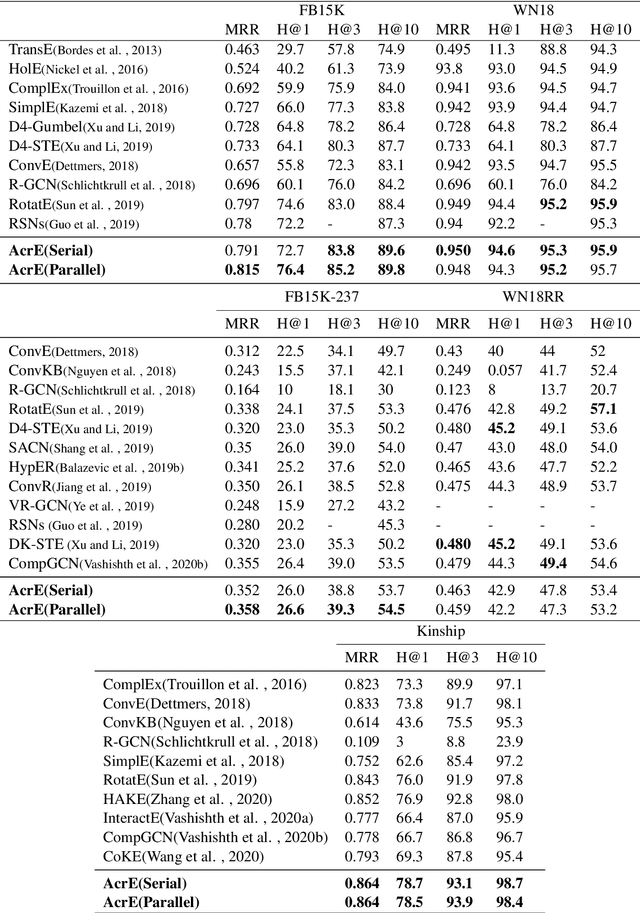
Knowledge graph embedding is an important task and it will benefit lots of downstream applications. Currently, deep neural networks based methods achieve state-of-the-art performance. However, most of these existing methods are very complex and need much time for training and inference. To address this issue, we propose a simple but effective atrous convolution based knowledge graph embedding method. Compared with existing state-of-the-art methods, our method has following main characteristics. First, it effectively increases feature interactions by using atrous convolutions. Second, to address the original information forgotten issue and vanishing/exploding gradient issue, it uses the residual learning method. Third, it has simpler structure but much higher parameter efficiency. We evaluate our method on six benchmark datasets with different evaluation metrics. Extensive experiments show that our model is very effective. On these diverse datasets, it achieves better results than the compared state-of-the-art methods on most of evaluation metrics. The source codes of our model could be found at https://github.com/neukg/AcrE.
Unbiased Deep Reinforcement Learning: A General Training Framework for Existing and Future Algorithms
May 12, 2020

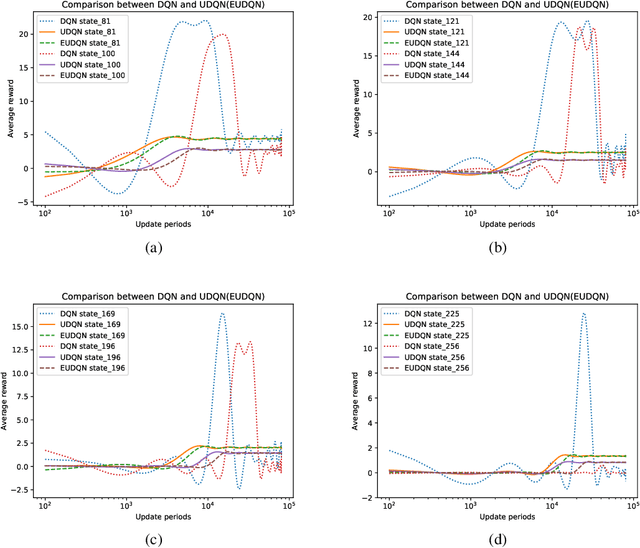
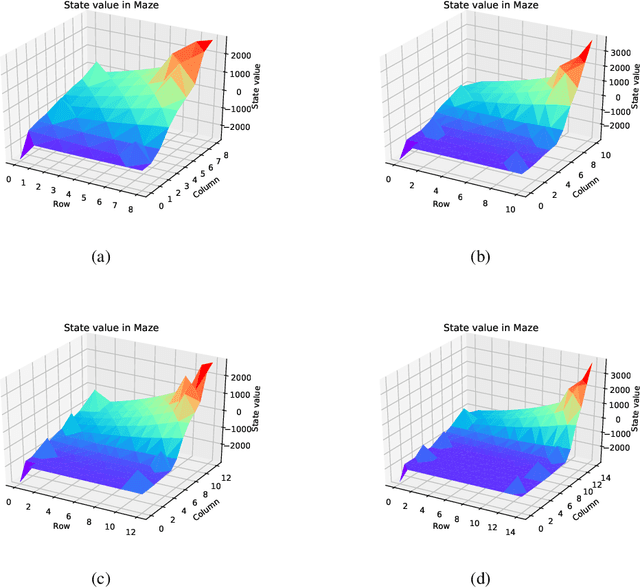
In recent years deep neural networks have been successfully applied to the domains of reinforcement learning \cite{bengio2009learning,krizhevsky2012imagenet,hinton2006reducing}. Deep reinforcement learning \cite{mnih2015human} is reported to have the advantage of learning effective policies directly from high-dimensional sensory inputs over traditional agents. However, within the scope of the literature, there is no fundamental change or improvement on the existing training framework. Here we propose a novel training framework that is conceptually comprehensible and potentially easy to be generalized to all feasible algorithms for reinforcement learning. We employ Monte-carlo sampling to achieve raw data inputs, and train them in batch to achieve Markov decision process sequences and synchronously update the network parameters instead of experience replay. This training framework proves to optimize the unbiased approximation of loss function whose estimation exactly matches the real probability distribution data inputs follow, and thus have overwhelming advantages of sample efficiency and convergence rate over existing deep reinforcement learning after evaluating it on both discrete action spaces and continuous control problems. Besides, we propose several algorithms embedded with our new framework to deal with typical discrete and continuous scenarios. These algorithms prove to be far more efficient than their original versions under the framework of deep reinforcement learning, and provide examples for existing and future algorithms to generalize to our new framework.