 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Deep Reinforcement Learning: A General Training Framework for Existing and Future Algorithms
Paper and Code
May 12, 2020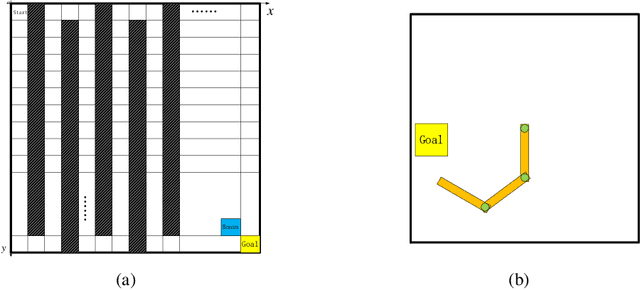

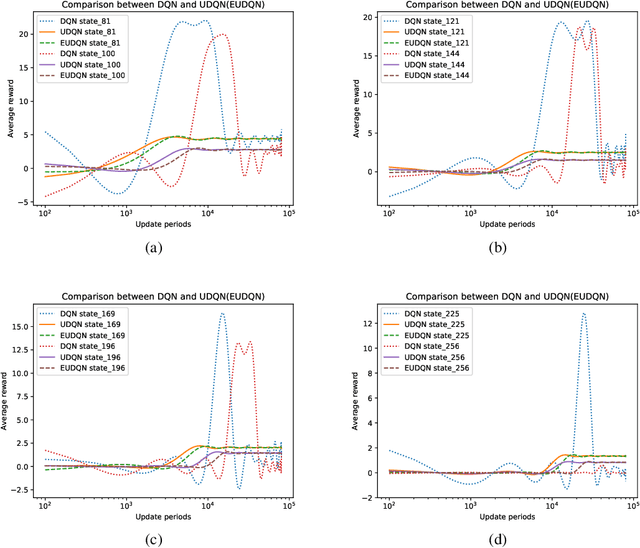
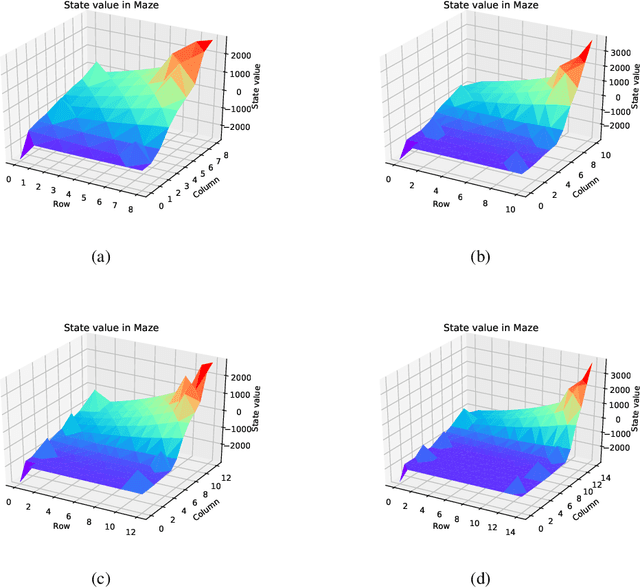
In recent years deep neural networks have been successfully applied to the domains of reinforcement learning \cite{bengio2009learning,krizhevsky2012imagenet,hinton2006reducing}. Deep reinforcement learning \cite{mnih2015human} is reported to have the advantage of learning effective policies directly from high-dimensional sensory inputs over traditional agents. However, within the scope of the literature, there is no fundamental change or improvement on the existing training framework. Here we propose a novel training framework that is conceptually comprehensible and potentially easy to be generalized to all feasible algorithms for reinforcement learning. We employ Monte-carlo sampling to achieve raw data inputs, and train them in batch to achieve Markov decision process sequences and synchronously update the network parameters instead of experience replay. This training framework proves to optimize the unbiased approximation of loss function whose estimation exactly matches the real probability distribution data inputs follow, and thus have overwhelming advantages of sample efficiency and convergence rate over existing deep reinforcement learning after evaluating it on both discrete action spaces and continuous control problems. Besides, we propose several algorithms embedded with our new framework to deal with typical discrete and continuous scenarios. These algorithms prove to be far more efficient than their original versions under the framework of deep reinforcement learning, and provide examples for existing and future algorithms to generalize to our new framework.