 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion recognition based on multi-modal electrophysiology multi-head attention Contrastive Learning
Jul 12, 2023

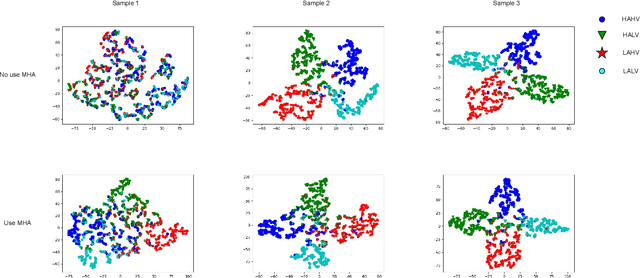

Emotion recognition is an important research direction in artificial intelligence, helping machines understand and adapt to human emotional states. Multimodal electrophysiological(ME) signals, such as EEG, GSR, respiration(Resp), and temperature(Temp), are effective biomarkers for reflecting changes in human emotions. However, using electrophysiological signals for emotion recognition faces challenges such as data scarcity, inconsistent labeling, and difficulty in cross-individual generalization. To address these issues, we propose ME-MHACL, a self-supervised contrastive learning-based multimodal emotion recognition method that can learn meaningful feature representations from unlabeled electrophysiological signals and use multi-head attention mechanisms for feature fusion to improve recognition performance. Our method includes two stages: first, we use the Meiosis method to group sample and augment unlabeled electrophysiological signals and design a self-supervised contrastive learning task; second, we apply the trained feature extractor to labeled electrophysiological signals and use multi-head attention mechanisms for feature fusion. We conducted experiments on two public datasets, DEAP and MAHNOB-HCI, and our method outperformed existing benchmark methods in emotion recognition tasks and had good cross-individual generalization ability.
Few-shot Classification with Shrinkage Exemplars
May 30, 2023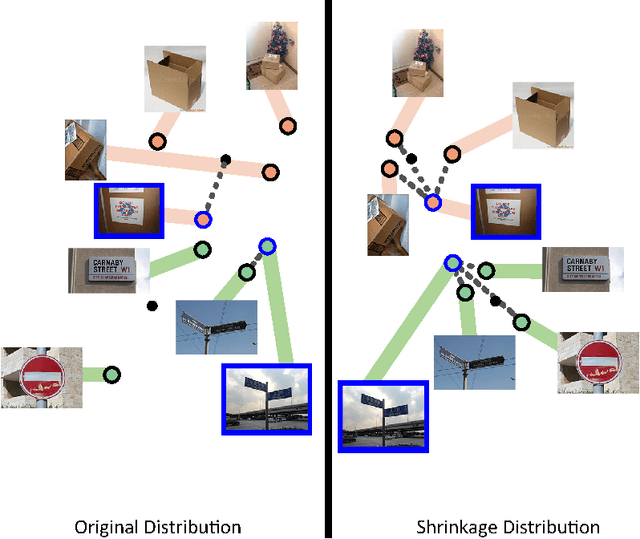
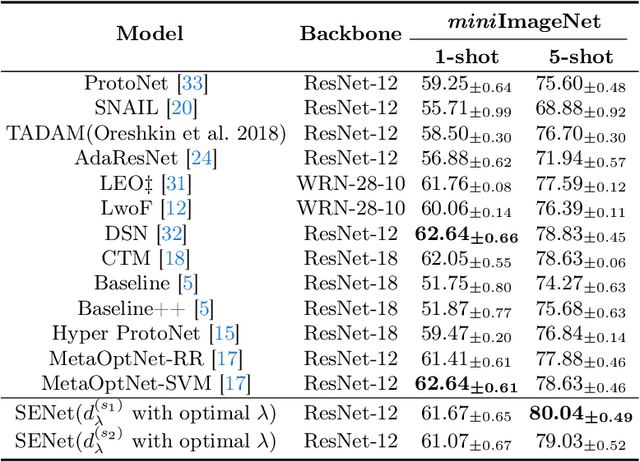
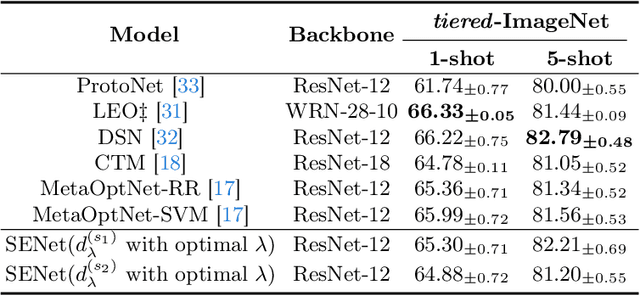
Prototype is widely used to represent internal structure of category for few-shot learning, which was proposed as a simple inductive bias to address the issue of overfitting. However, since prototype representation is normally averaged from individual samples, it cannot flexibly adjust the retention ability of sample differences that may leads to underfitting in some cases of sample distribution. To address this problem, in this work, we propose Shrinkage Exemplar Networks (SENet) for few-shot classification. SENet balances the prototype representations (high-bias, low-variance) and example representations (low-bias, high-variance) using a shrinkage estimator, where the categories are represented by the embedings of samples that shrink to their mean via spectral filtering. Furthermore, a shrinkage exemplar loss is proposed to replace the widely used cross entropy loss for capturing the information of individual shrinkage samples. Several experiments were conducted on miniImageNet, tiered-ImageNet and CIFAR-FS datasets. We demonstrate that our proposed model is superior to the example model and the prototype model for some tasks.
Kernel Relative-prototype Spectral Filtering for Few-shot Learning
Jul 24, 2022
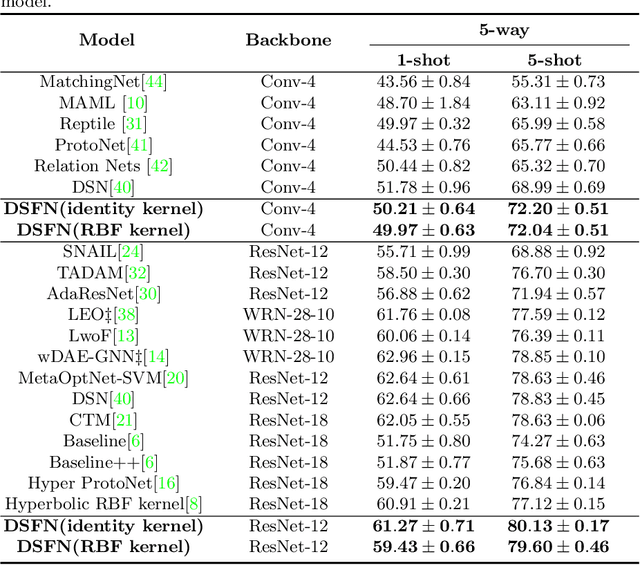
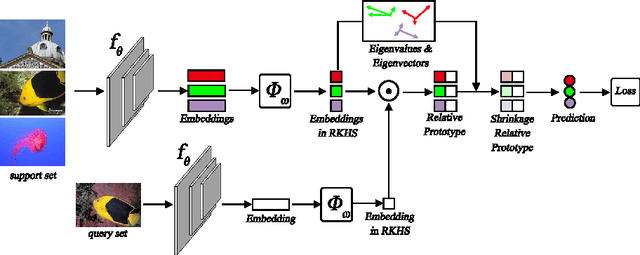
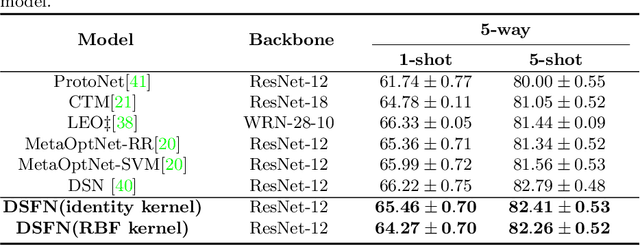
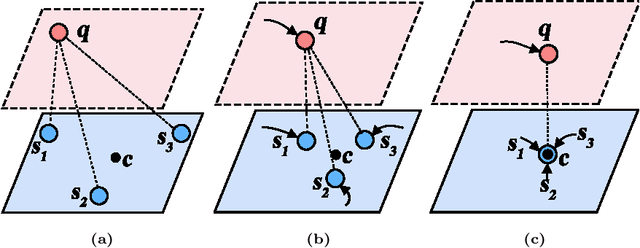
Few-shot learning performs classification tasks and regression tasks on scarce samples. As one of the most representative few-shot learning models, Prototypical Network represents each class as sample average, or a prototype, and measures the similarity of samples and prototypes by Euclidean distance. In this paper, we propose a framework of spectral filtering (shrinkage) for measuring the difference between query samples and prototypes, or namely the relative prototypes, in a reproducing kernel Hilbert space (RKHS). In this framework, we further propose a method utilizing Tikhonov regularization as the filter function for few-shot classification. We conduct several experiments to verify our method utilizing different kernels based on the miniImageNet dataset, tiered-ImageNet dataset and CIFAR-FS dataset. The experimental results show that the proposed model can perform the state-of-the-art. In addition, the experimental results show that the proposed shrinkage method can boost the performance. Source code is available at https://github.com/zhangtao2022/DSFN.
Unbiased Deep Reinforcement Learning: A General Training Framework for Existing and Future Algorithms
May 12, 2020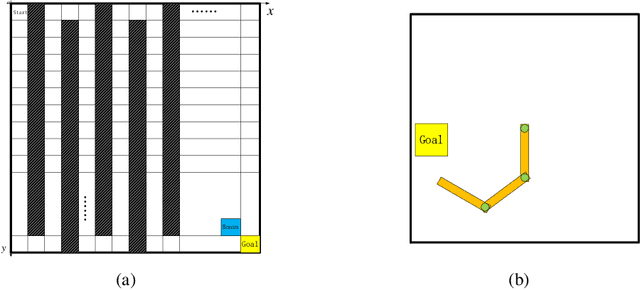

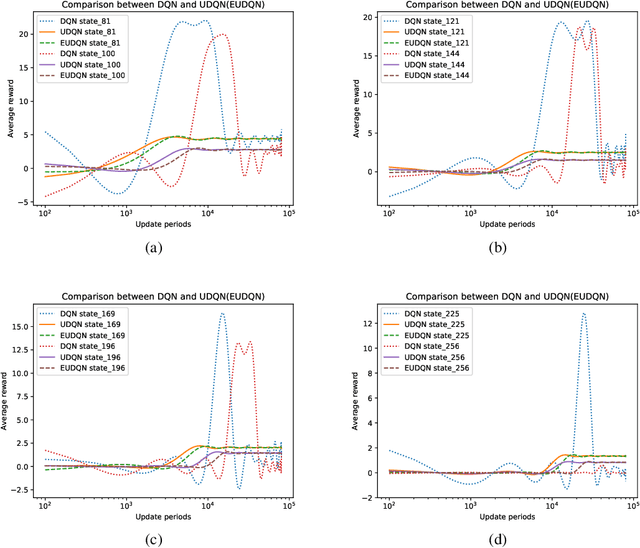
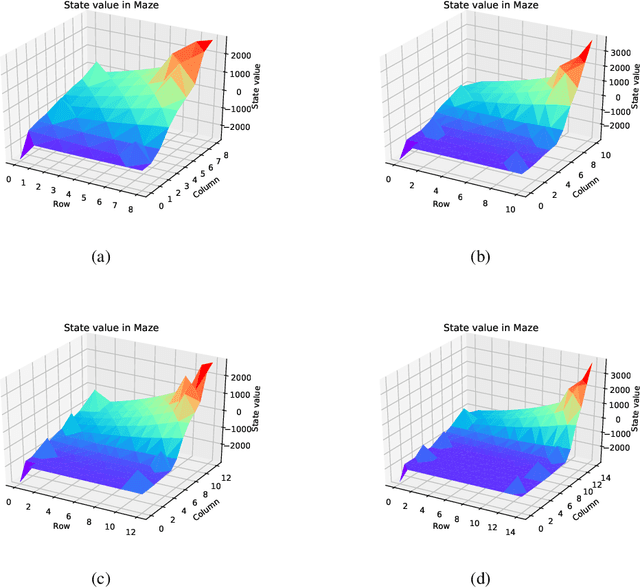
In recent years deep neural networks have been successfully applied to the domains of reinforcement learning \cite{bengio2009learning,krizhevsky2012imagenet,hinton2006reducing}. Deep reinforcement learning \cite{mnih2015human} is reported to have the advantage of learning effective policies directly from high-dimensional sensory inputs over traditional agents. However, within the scope of the literature, there is no fundamental change or improvement on the existing training framework. Here we propose a novel training framework that is conceptually comprehensible and potentially easy to be generalized to all feasible algorithms for reinforcement learning. We employ Monte-carlo sampling to achieve raw data inputs, and train them in batch to achieve Markov decision process sequences and synchronously update the network parameters instead of experience replay. This training framework proves to optimize the unbiased approximation of loss function whose estimation exactly matches the real probability distribution data inputs follow, and thus have overwhelming advantages of sample efficiency and convergence rate over existing deep reinforcement learning after evaluating it on both discrete action spaces and continuous control problems. Besides, we propose several algorithms embedded with our new framework to deal with typical discrete and continuous scenarios. These algorithms prove to be far more efficient than their original versions under the framework of deep reinforcement learning, and provide examples for existing and future algorithms to generalize to our new framework.