 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Interpretable Temporal Convolution Network for Event Detection in Lung Sound Recordings
Jun 30, 2021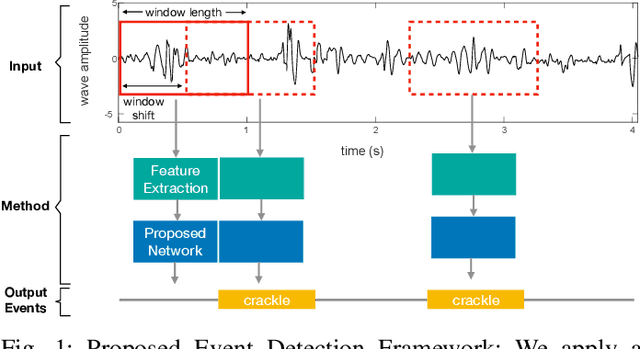
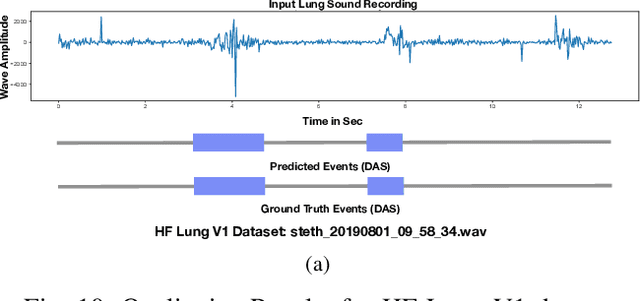
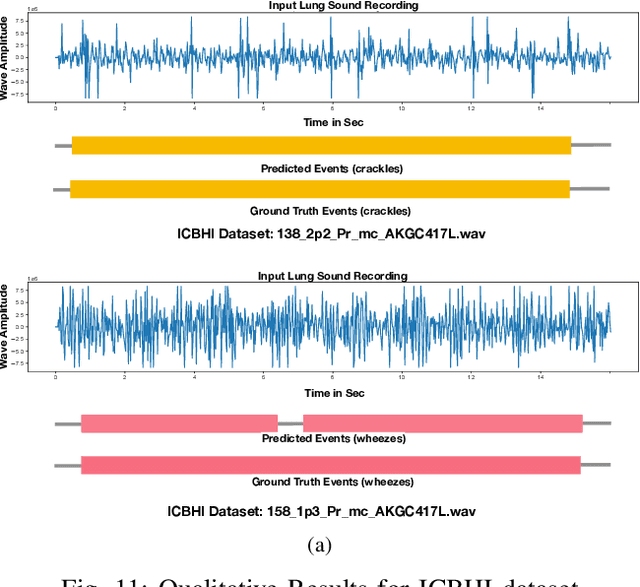
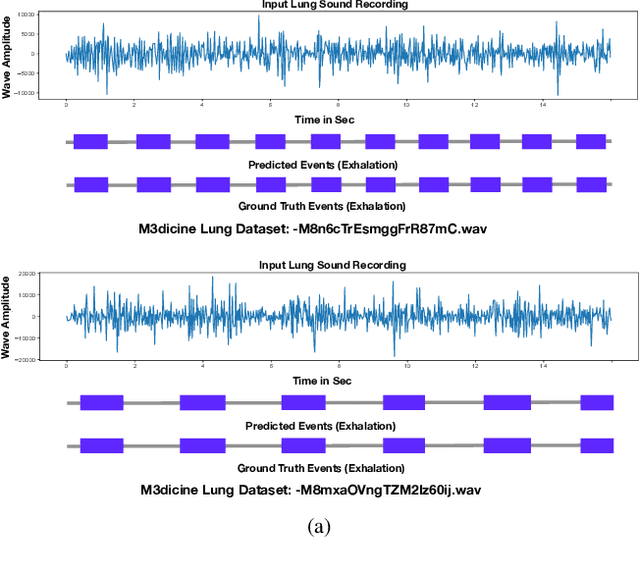
This paper proposes a novel framework for lung sound event detection, segmenting continuous lung sound recordings into discrete events and performing recognition on each event. Exploiting the lightweight nature of Temporal Convolution Networks (TCNs) and their superior results compared to their recurrent counterparts, we propose a lightweight, yet robust, and completely interpretable framework for lung sound event detection. We propose the use of a multi-branch TCN architecture and exploit a novel fusion strategy to combine the resultant features from these branches. This not only allows the network to retain the most salient information across different temporal granularities and disregards irrelevant information, but also allows our network to process recordings of arbitrary length. Results: The proposed method is evaluated on multiple public and in-house benchmarks of irregular and noisy recordings of the respiratory auscultation process for the identification of numerous auscultation events including inhalation, exhalation, crackles, wheeze, stridor, and rhonchi. We exceed the state-of-the-art results in all evaluations. Furthermore, we empirically analyse the effect of the proposed multi-branch TCN architecture and the feature fusion strategy and provide quantitative and qualitative evaluations to illustrate their efficiency. Moreover, we provide an end-to-end model interpretation pipeline that interprets the operations of all the components of the proposed framework. Our analysis of different feature fusion strategies shows that the proposed feature concatenation method leads to better suppression of non-informative features, which drastically reduces the classifier overhead resulting in a robust lightweight network.The lightweight nature of our model allows it to be deployed in end-user devices such as smartphones, and it has the ability to generate predictions in real-time.
Domain Generalization in Biosignal Classification
Nov 12, 2020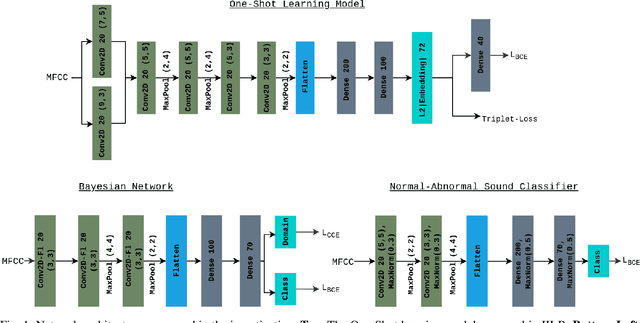
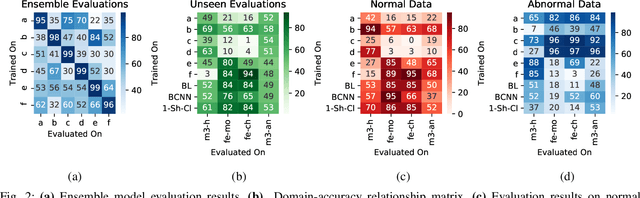
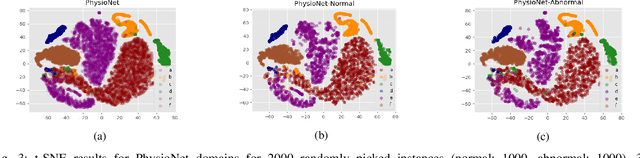
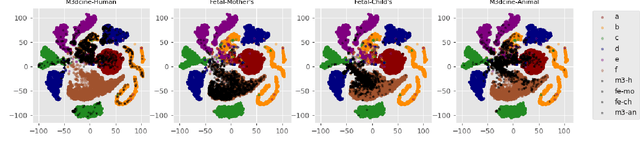
Objective: When training machine learning models, we often assume that the training data and evaluation data are sampled from the same distribution. However, this assumption is violated when the model is evaluated on another unseen but similar database, even if that database contains the same classes. This problem is caused by domain-shift and can be solved using two approaches: domain adaptation and domain generalization. Simply, domain adaptation methods can access data from unseen domains during training; whereas in domain generalization, the unseen data is not available during training. Hence, domain generalization concerns models that perform well on inaccessible, domain-shifted data. Method: Our proposed domain generalization method represents an unseen domain using a set of known basis domains, afterwhich we classify the unseen domain using classifier fusion. To demonstrate our system, we employ a collection of heart sound databases that contain normal and abnormal sounds (classes). Results: Our proposed classifier fusion method achieves accuracy gains of up to 16% for four completely unseen domains. Conclusion: Recognizing the complexity induced by the inherent temporal nature of biosignal data, the two-stage method proposed in this study is able to effectively simplify the whole process of domain generalization while demonstrating good results on unseen domains and the adopted basis domains. Significance: To our best knowledge, this is the first study that investigates domain generalization for biosignal data. Our proposed learning strategy can be used to effectively learn domain-relevant features while being aware of the class differences in the data.
Understanding the Importance of Heart Sound Segmentation for Heart Anomaly Detection
May 21, 2020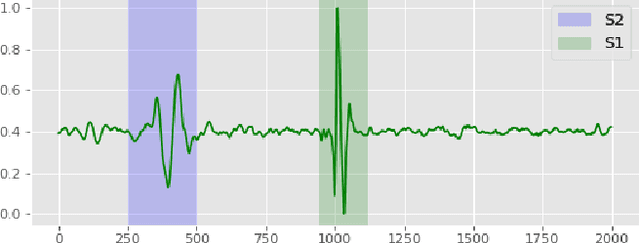
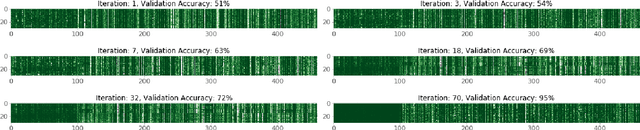

Traditionally, abnormal heart sound classification is framed as a three-stage process. The first stage involves segmenting the phonocardiogram to detect fundamental heart sounds; after which features are extracted and classification is performed. Some researchers in the field argue the segmentation step is an unwanted computational burden, whereas others embrace it as a prior step to feature extraction. When comparing accuracies achieved by studies that have segmented heart sounds before analysis with those who have overlooked that step, the question of whether to segment heart sounds before feature extraction is still open. In this study, we explicitly examine the importance of heart sound segmentation as a prior step for heart sound classification, and then seek to apply the obtained insights to propose a robust classifier for abnormal heart sound detection. Furthermore, recognizing the pressing need for explainable Artificial Intelligence (AI) models in the medical domain, we also unveil hidden representations learned by the classifier using model interpretation techniques. Experimental results demonstrate that the segmentation plays an essential role in abnormal heart sound classification. Our new classifier is also shown to be robust, stable and most importantly, explainable, with an accuracy of almost 100% on the widely used PhysioNet dataset.
Heart Sound Segmentation using Bidirectional LSTMs with Attention
Apr 02, 2020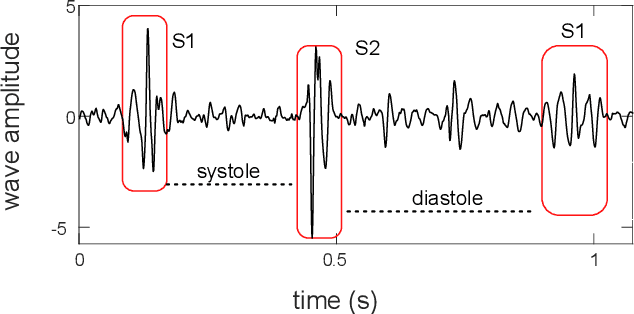
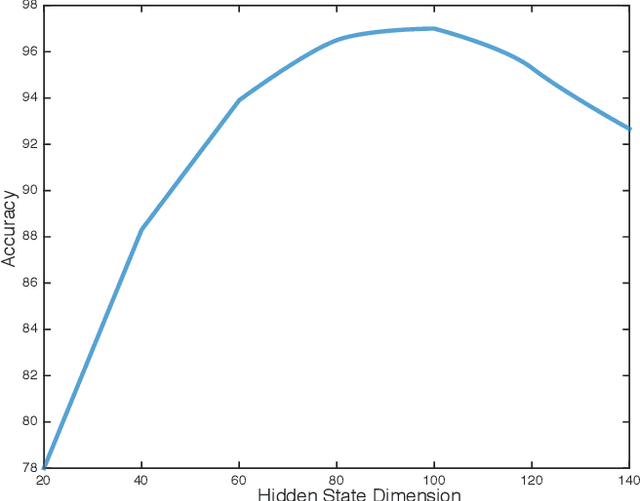


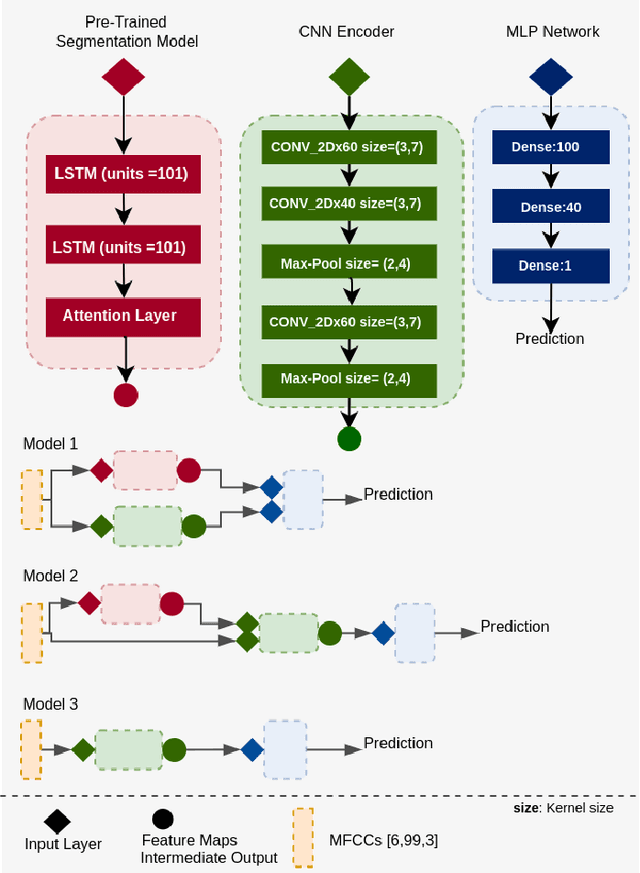
This paper proposes a novel framework for the segmentation of phonocardiogram (PCG) signals into heart states, exploiting the temporal evolution of the PCG as well as considering the salient information that it provides for the detection of the heart state. We propose the use of recurrent neural networks and exploit recent advancements in attention based learning to segment the PCG signal. This allows the network to identify the most salient aspects of the signal and disregard uninformative information. The proposed method attains state-of-the-art performance on multiple benchmarks including both human and animal heart recordings. Furthermore, we empirically analyse different feature combinations including envelop features, wavelet and Mel Frequency Cepstral Coefficients (MFCC), and provide quantitative measurements that explore the importance of different features in the proposed approach. We demonstrate that a recurrent neural network coupled with attention mechanisms can effectively learn from irregular and noisy PCG recordings. Our analysis of different feature combinations shows that MFCC features and their derivatives offer the best performance compared to classical wavelet and envelop features. Heart sound segmentation is a crucial pre-processing step for many diagnostic applications. The proposed method provides a cost effective alternative to labour extensive manual segmentation, and provides a more accurate segmentation than existing methods. As such, it can improve the performance of further analysis including the detection of murmurs and ejection clicks. The proposed method is also applicable for detection and segmentation of other one dimensional biomedical signals.