 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Interpretable Temporal Convolution Network for Event Detection in Lung Sound Recordings
Paper and Code
Jun 30, 2021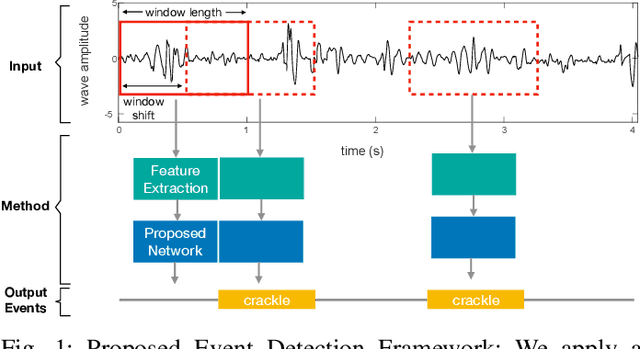
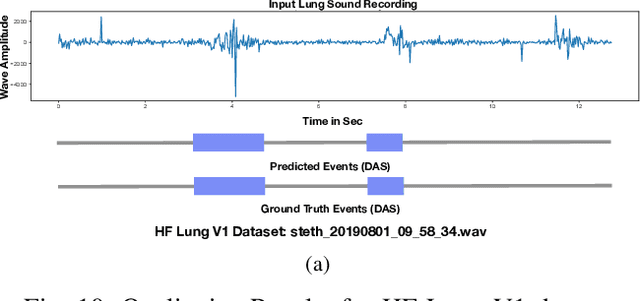
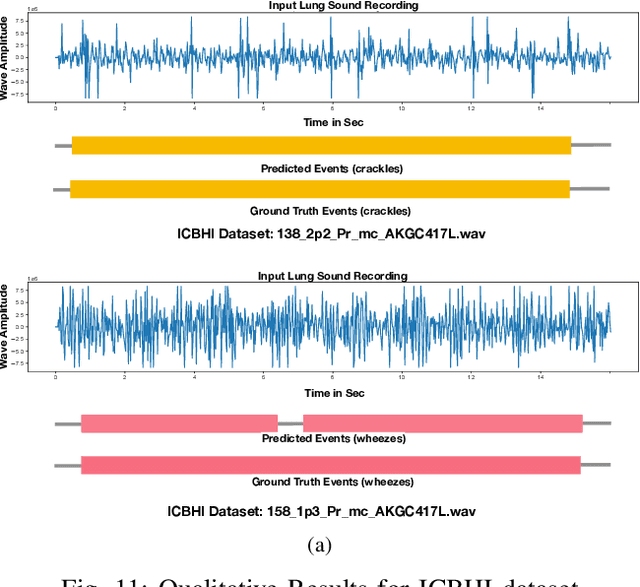
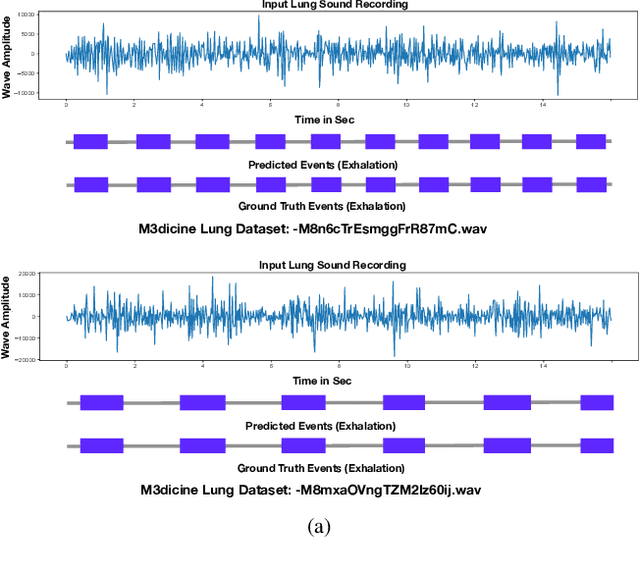
This paper proposes a novel framework for lung sound event detection, segmenting continuous lung sound recordings into discrete events and performing recognition on each event. Exploiting the lightweight nature of Temporal Convolution Networks (TCNs) and their superior results compared to their recurrent counterparts, we propose a lightweight, yet robust, and completely interpretable framework for lung sound event detection. We propose the use of a multi-branch TCN architecture and exploit a novel fusion strategy to combine the resultant features from these branches. This not only allows the network to retain the most salient information across different temporal granularities and disregards irrelevant information, but also allows our network to process recordings of arbitrary length. Results: The proposed method is evaluated on multiple public and in-house benchmarks of irregular and noisy recordings of the respiratory auscultation process for the identification of numerous auscultation events including inhalation, exhalation, crackles, wheeze, stridor, and rhonchi. We exceed the state-of-the-art results in all evaluations. Furthermore, we empirically analyse the effect of the proposed multi-branch TCN architecture and the feature fusion strategy and provide quantitative and qualitative evaluations to illustrate their efficiency. Moreover, we provide an end-to-end model interpretation pipeline that interprets the operations of all the components of the proposed framework. Our analysis of different feature fusion strategies shows that the proposed feature concatenation method leads to better suppression of non-informative features, which drastically reduces the classifier overhead resulting in a robust lightweight network.The lightweight nature of our model allows it to be deployed in end-user devices such as smartphones, and it has the ability to generate predictions in real-time.