 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Coding Networks Meet Action Recognition
Oct 22, 2019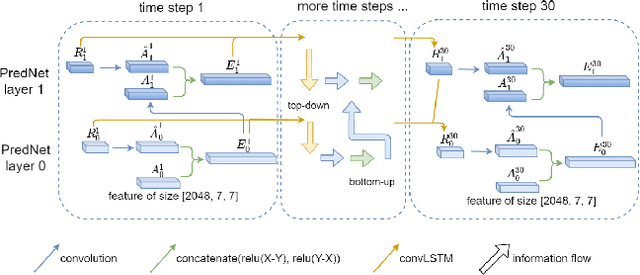
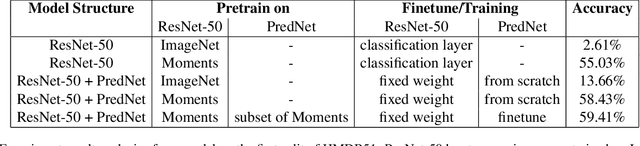
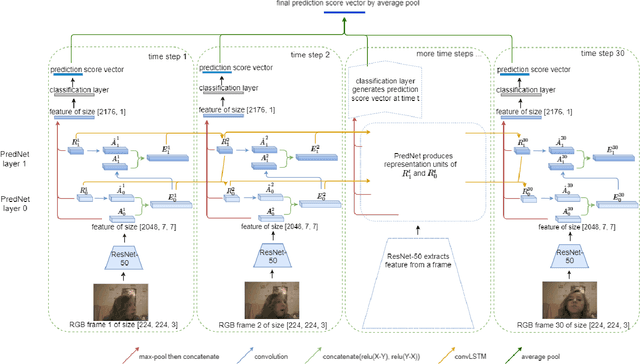
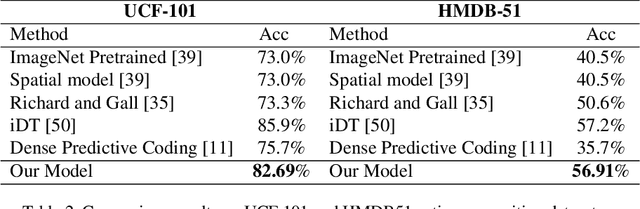
Action recognition is a key problem in computer vision that labels videos with a set of predefined actions. Capturing both, semantic content and motion, along the video frames is key to achieve high accuracy performance on this task. Most of the state-of-the-art methods rely on RGB frames for extracting the semantics and pre-computed optical flow fields as a motion cue. Then, both are combined using deep neural networks. Yet, it has been argued that such models are not able to leverage the motion information extracted from the optical flow, but instead the optical flow allows for better recognition of people and objects in the video. This urges the need to explore different cues or models that can extract motion in a more informative fashion. To tackle this issue, we propose to explore the predictive coding network, so called PredNet, a recurrent neural network that propagates predictive coding errors across layers and time steps. We analyze whether PredNet can better capture motions in videos by estimating over time the representations extracted from pre-trained networks for action recognition. In this way, the model only relies on the video frames, and does not need pre-processed optical flows as input. We report the effectiveness of our proposed model on UCF101 and HMDB51 datasets.
Plug-and-Play CNN for Crowd Motion Analysis: An Application in Abnormal Event Detection
Jan 27, 2018
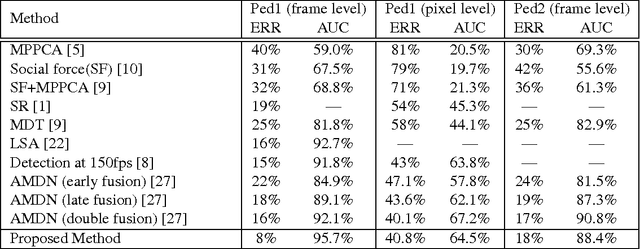
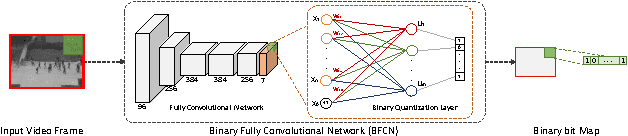
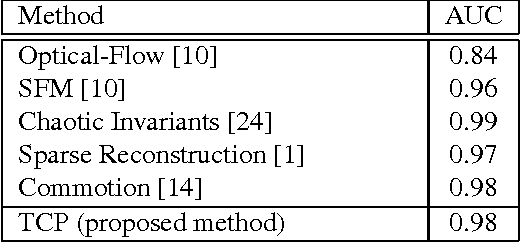
Most of the crowd abnormal event detection methods rely on complex hand-crafted features to represent the crowd motion and appearance. Convolutional Neural Networks (CNN) have shown to be a powerful tool with excellent representational capacities, which can leverage the need for hand-crafted features. In this paper, we show that keeping track of the changes in the CNN feature across time can facilitate capturing the local abnormality. We specifically propose a novel measure-based method which allows measuring the local abnormality in a video by combining semantic information (inherited from existing CNN models) with low-level Optical-Flow. One of the advantage of this method is that it can be used without the fine-tuning costs. The proposed method is validated on challenging abnormality detection datasets and the results show the superiority of our method compared to the state-of-the-art methods.
Efficient Convolutional Neural Network with Binary Quantization Layer
Nov 21, 2016

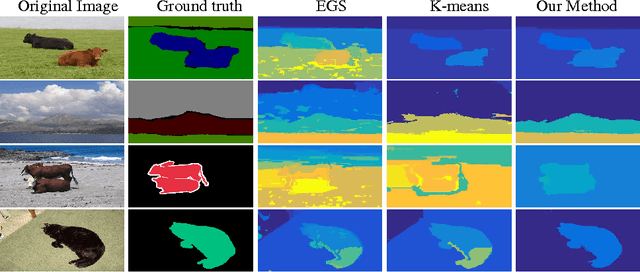

In this paper we introduce a novel method for segmentation that can benefit from general semantics of Convolutional Neural Network (CNN). Our segmentation proposes visually and semantically coherent image segments. We use binary encoding of CNN features to overcome the difficulty of the clustering on the high-dimensional CNN feature space. These binary encoding can be embedded into the CNN as an extra layer at the end of the network. This results in real-time segmentation. To the best of our knowledge our method is the first attempt on general semantic image segmentation using CNN. All the previous papers were limited to few number of category of the images (e.g. PASCAL VOC). Experiments show that our segmentation algorithm outperform the state-of-the-art non-semantic segmentation methods by a large margin.
CNN-aware Binary Map for General Semantic Segmentation
Sep 29, 2016



In this paper we introduce a novel method for general semantic segmentation that can benefit from general semantics of Convolutional Neural Network (CNN). Our segmentation proposes visually and semantically coherent image segments. We use binary encoding of CNN features to overcome the difficulty of the clustering on the high-dimensional CNN feature space. These binary codes are very robust against noise and non-semantic changes in the image. These binary encoding can be embedded into the CNN as an extra layer at the end of the network. This results in real-time segmentation. To the best of our knowledge our method is the first attempt on general semantic image segmentation using CNN. All the previous papers were limited to few number of category of the images (e.g. PASCAL VOC). Experiments show that our segmentation algorithm outperform the state-of-the-art non-semantic segmentation methods by large margin.
Emotion-Based Crowd Representation for Abnormality Detection
Jul 26, 2016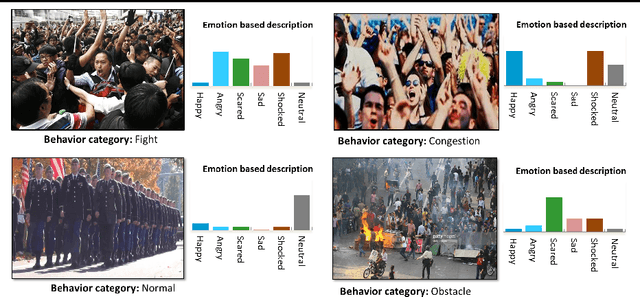



In crowd behavior understanding, a model of crowd behavior need to be trained using the information extracted from video sequences. Since there is no ground-truth available in crowd datasets except the crowd behavior labels, most of the methods proposed so far are just based on low-level visual features. However, there is a huge semantic gap between low-level motion/appearance features and high-level concept of crowd behaviors. In this paper we propose an attribute-based strategy to alleviate this problem. While similar strategies have been recently adopted for object and action recognition, as far as we know, we are the first showing that the crowd emotions can be used as attributes for crowd behavior understanding. The main idea is to train a set of emotion-based classifiers, which can subsequently be used to represent the crowd motion. For this purpose, we collect a big dataset of video clips and provide them with both annotations of "crowd behaviors" and "crowd emotions". We show the results of the proposed method on our dataset, which demonstrate that the crowd emotions enable the construction of more descriptive models for crowd behaviors. We aim at publishing the dataset with the article, to be used as a benchmark for the communities.
Action Recognition with Image Based CNN Features
Dec 13, 2015

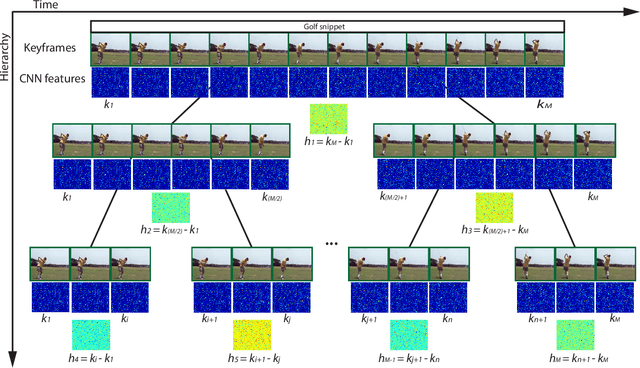
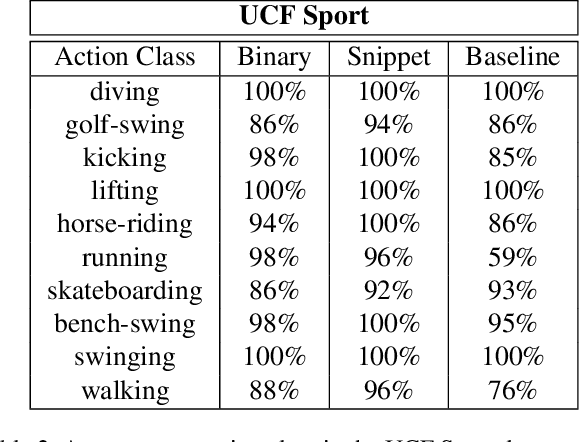
Most of human actions consist of complex temporal compositions of more simple actions. Action recognition tasks usually relies on complex handcrafted structures as features to represent the human action model. Convolutional Neural Nets (CNN) have shown to be a powerful tool that eliminate the need for designing handcrafted features. Usually, the output of the last layer in CNN (a layer before the classification layer -known as fc7) is used as a generic feature for images. In this paper, we show that fc7 features, per se, can not get a good performance for the task of action recognition, when the network is trained only on images. We present a feature structure on top of fc7 features, which can capture the temporal variation in a video. To represent the temporal components, which is needed to capture motion information, we introduced a hierarchical structure. The hierarchical model enables to capture sub-actions from a complex action. At the higher levels of the hierarchy, it represents a coarse capture of action sequence and lower levels represent fine action elements. Furthermore, we introduce a method for extracting key-frames using binary coding of each frame in a video, which helps to improve the performance of our hierarchical model. We experimented our method on several action datasets and show that our method achieves superior results compared to other state-of-the-arts methods.