 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition with Image Based CNN Features
Paper and Code


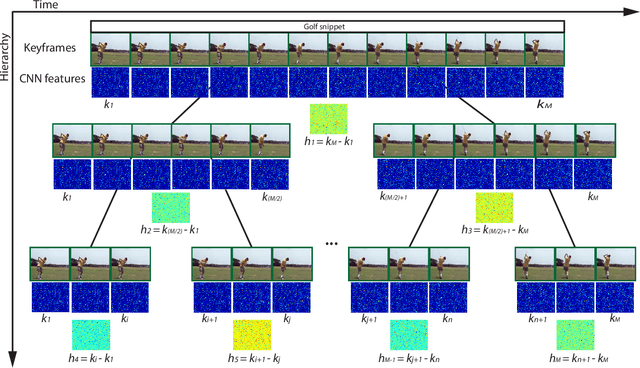
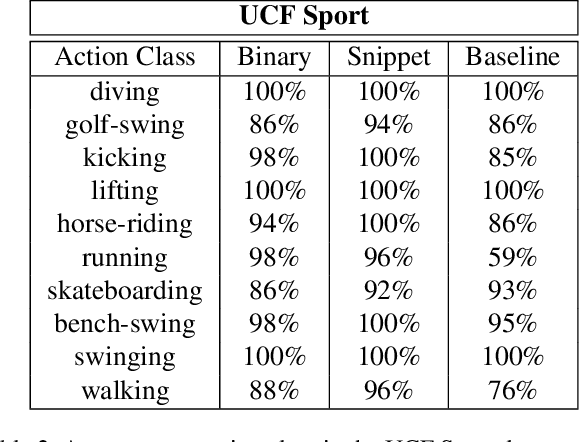
Most of human actions consist of complex temporal compositions of more simple actions. Action recognition tasks usually relies on complex handcrafted structures as features to represent the human action model. Convolutional Neural Nets (CNN) have shown to be a powerful tool that eliminate the need for designing handcrafted features. Usually, the output of the last layer in CNN (a layer before the classification layer -known as fc7) is used as a generic feature for images. In this paper, we show that fc7 features, per se, can not get a good performance for the task of action recognition, when the network is trained only on images. We present a feature structure on top of fc7 features, which can capture the temporal variation in a video. To represent the temporal components, which is needed to capture motion information, we introduced a hierarchical structure. The hierarchical model enables to capture sub-actions from a complex action. At the higher levels of the hierarchy, it represents a coarse capture of action sequence and lower levels represent fine action elements. Furthermore, we introduce a method for extracting key-frames using binary coding of each frame in a video, which helps to improve the performance of our hierarchical model. We experimented our method on several action datasets and show that our method achieves superior results compared to other state-of-the-arts methods.