 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical limitations of multi-layer Transformer
Dec 04, 2024Transformers, especially the decoder-only variants, are the backbone of most modern large language models; yet we do not have much understanding of their expressive power except for the simple $1$-layer case. Due to the difficulty of analyzing multi-layer models, all previous work relies on unproven complexity conjectures to show limitations for multi-layer Transformers. In this work, we prove the first $\textit{unconditional}$ lower bound against multi-layer decoder-only transformers. For any constant $L$, we prove that any $L$-layer decoder-only transformer needs a polynomial model dimension ($n^{\Omega(1)}$) to perform sequential composition of $L$ functions over an input of $n$ tokens. As a consequence, our results give: (1) the first depth-width trade-off for multi-layer transformers, exhibiting that the $L$-step composition task is exponentially harder for $L$-layer models compared to $(L+1)$-layer ones; (2) an unconditional separation between encoder and decoder, exhibiting a hard task for decoders that can be solved by an exponentially shallower and smaller encoder; (3) a provable advantage of chain-of-thought, exhibiting a task that becomes exponentially easier with chain-of-thought. On the technical side, we propose the multi-party $\textit{autoregressive}$ $\textit{communication}$ $\textit{model}$ that captures the computation of a decoder-only Transformer. We also introduce a new proof technique that finds a certain $\textit{indistinguishable}$ $\textit{decomposition}$ of all possible inputs iteratively for proving lower bounds in this model. We believe our new communication model and proof technique will be helpful to further understand the computational power of transformers.
The Cost of Parallelizing Boosting
Feb 23, 2024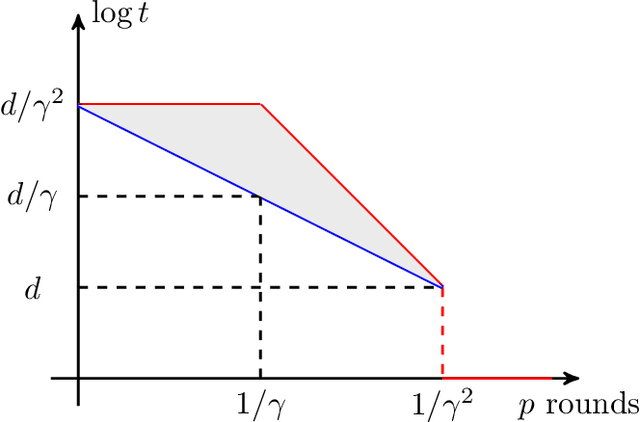
We study the cost of parallelizing weak-to-strong boosting algorithms for learning, following the recent work of Karbasi and Larsen. Our main results are two-fold: - First, we prove a tight lower bound, showing that even "slight" parallelization of boosting requires an exponential blow-up in the complexity of training. Specifically, let $\gamma$ be the weak learner's advantage over random guessing. The famous \textsc{AdaBoost} algorithm produces an accurate hypothesis by interacting with the weak learner for $\tilde{O}(1 / \gamma^2)$ rounds where each round runs in polynomial time. Karbasi and Larsen showed that "significant" parallelization must incur exponential blow-up: Any boosting algorithm either interacts with the weak learner for $\Omega(1 / \gamma)$ rounds or incurs an $\exp(d / \gamma)$ blow-up in the complexity of training, where $d$ is the VC dimension of the hypothesis class. We close the gap by showing that any boosting algorithm either has $\Omega(1 / \gamma^2)$ rounds of interaction or incurs a smaller exponential blow-up of $\exp(d)$. -Complementing our lower bound, we show that there exists a boosting algorithm using $\tilde{O}(1/(t \gamma^2))$ rounds, and only suffer a blow-up of $\exp(d \cdot t^2)$. Plugging in $t = \omega(1)$, this shows that the smaller blow-up in our lower bound is tight. More interestingly, this provides the first trade-off between the parallelism and the total work required for boosting.
Tight Time-Space Lower Bounds for Constant-Pass Learning
Oct 12, 2023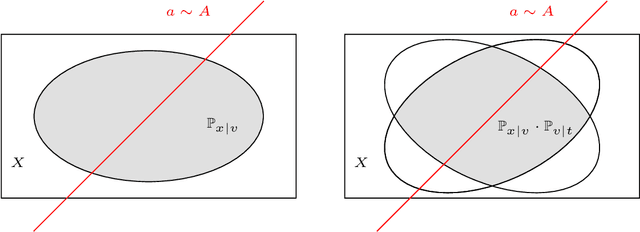

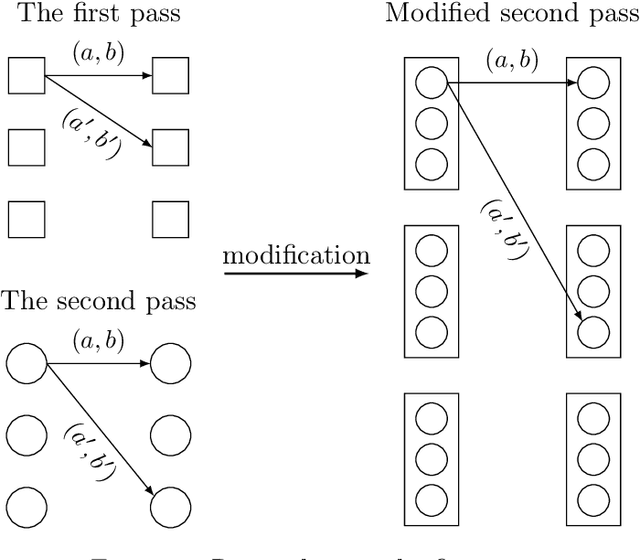

In his breakthrough paper, Raz showed that any parity learning algorithm requires either quadratic memory or an exponential number of samples [FOCS'16, JACM'19]. A line of work that followed extended this result to a large class of learning problems. Until recently, all these results considered learning in the streaming model, where each sample is drawn independently, and the learner is allowed a single pass over the stream of samples. Garg, Raz, and Tal [CCC'19] considered a stronger model, allowing multiple passes over the stream. In the $2$-pass model, they showed that learning parities of size $n$ requires either a memory of size $n^{1.5}$ or at least $2^{\sqrt{n}}$ samples. (Their result also generalizes to other learning problems.) In this work, for any constant $q$, we prove tight memory-sample lower bounds for any parity learning algorithm that makes $q$ passes over the stream of samples. We show that such a learner requires either $\Omega(n^{2})$ memory size or at least $2^{\Omega(n)}$ samples. Beyond establishing a tight lower bound, this is the first non-trivial lower bound for $q$-pass learning for any $q\ge 3$. Similar to prior work, our results extend to any learning problem with many nearly-orthogonal concepts. We complement the lower bound with an upper bound, showing that parity learning with $q$ passes can be done efficiently with $O(n^2/\log q)$ memory.
Breaking the Metric Voting Distortion Barrier
Jun 30, 2023



We consider the following well studied problem of metric distortion in social choice. Suppose we have an election with $n$ voters and $m$ candidates who lie in a shared metric space. We would like to design a voting rule that chooses a candidate whose average distance to the voters is small. However, instead of having direct access to the distances in the metric space, each voter gives us a ranked list of the candidates in order of distance. Can we design a rule that regardless of the election instance and underlying metric space, chooses a candidate whose cost differs from the true optimum by only a small factor (known as the distortion)? A long line of work culminated in finding deterministic voting rules with metric distortion $3$, which is the best possible for deterministic rules and many other classes of voting rules. However, without any restrictions, there is still a significant gap in our understanding: Even though the best lower bound is substantially lower at $2.112$, the best upper bound is still $3$, which is attained even by simple rules such as Random Dictatorship. Finding a rule that guarantees distortion $3 - \varepsilon$ for some constant $\varepsilon $ has been a major challenge in computational social choice. In this work, we give a rule that guarantees distortion less than $2.753$. To do so we study a handful of voting rules that are new to the problem. One is Maximal Lotteries, a rule based on the Nash equilibrium of a natural zero-sum game which dates back to the 60's. The others are novel rules that can be thought of as hybrids of Random Dictatorship and the Copeland rule. Though none of these rules can beat distortion $3$ alone, a careful randomization between Maximal Lotteries and any of the novel rules can.