 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
May 29, 2026Modern recommendation systems predominantly train retrieval and ranking as separate models despite both increasingly relying on large transformers encoding the same user behavior data, duplicating parameters, compute, and serving cost. Prior work unifies the model architecture but not the full pipeline: input formats, training procedures, and serving stacks remain fragmented across stages. We present UniPinRec, which achieves full-stack unification of retrieval and ranking at Pinterest: one input format, one model, one training stage, deployed within existing serving infrastructure. A shared transformer encodes the user action sequence into candidate-independent representations that branch into retrieval (ANN dot-product) and ranking (cross-attention) via task-specific heads. Three ideas make this work: (1) Masked Action Modeling (MAM) eliminates interleaving, enabling weight sharing without doubling context length; (2) Blended training examples pair action sequences with feedview impression slates to satisfy both objectives jointly; (3) Cross-stage KV cache sharing reuses user-history computation from retrieval for ranking, reducing total FLOPs versus serving two independent models. Deployed in the Pinterest core surfaces, UniPinRec delivers approximately +1% online engagement lift while cutting end-to-end serving latency by 11.1% and lifting QPS by 63.6%. To our knowledge, this is the first full-stack unification of retrieval and ranking, covering inputs, model, training and serving, deployed in a production recommendation system.
A robust single-pixel particle image velocimetry based on fully convolutional networks with cross-correlation embedded
Oct 31, 2021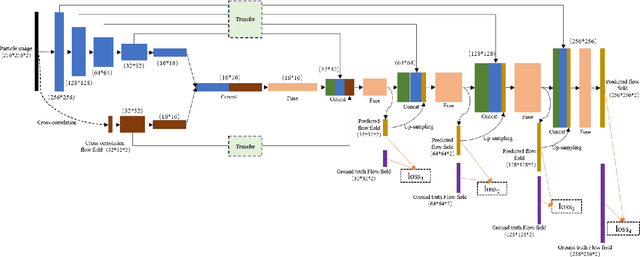
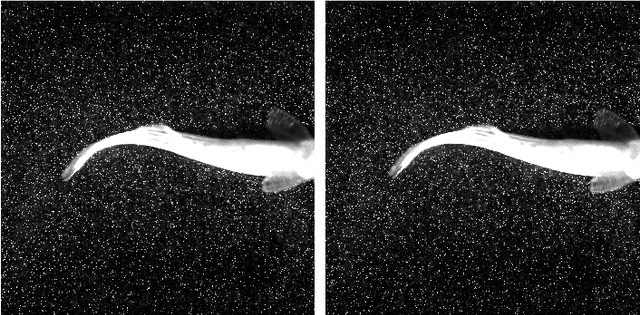
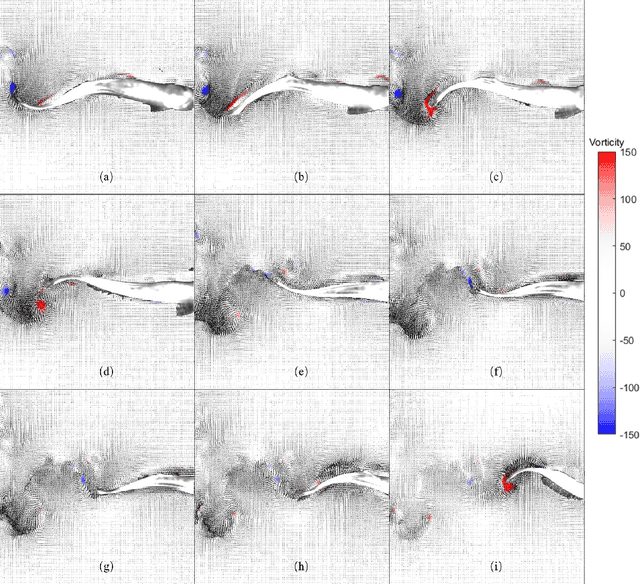

Particle image velocimetry (PIV) is essential in experimental fluid dynamics. In the current work, we propose a new velocity field estimation paradigm, which achieves a synergetic combination of the deep learning method and the traditional cross-correlation method. Specifically, the deep learning method is used to optimize and correct a coarse velocity guess to achieve a super-resolution calculation. And the cross-correlation method provides the initial velocity field based on a coarse correlation with a large interrogation window. As a reference, the coarse velocity guess helps with improving the robustness of the proposed algorithm. This fully convolutional network with embedded cross-correlation is named as CC-FCN. CC-FCN has two types of input layers, one is for the particle images, and the other is for the initial velocity field calculated using cross-correlation with a coarse resolution. Firstly, two pyramidal modules extract features of particle images and initial velocity field respectively. Then the fusion module appropriately fuses these features. Finally, CC-FCN achieves the super-resolution calculation through a series of deconvolution layers to obtain the single-pixel velocity field. As the supervised learning strategy is considered, synthetic data sets including ground-truth fluid motions are generated to train the network parameters. Synthetic and real experimental PIV data sets are used to test the trained neural network in terms of accuracy, precision, spatial resolution and robustness. The test results show that these attributes of CC-FCN are further improved compared with those of other tested PIV algorithms. The proposed model could therefore provide competitive and robust estimations for PIV experiments.
Neural Rule Grounding for Low-Resource Relation Extraction
Sep 20, 2019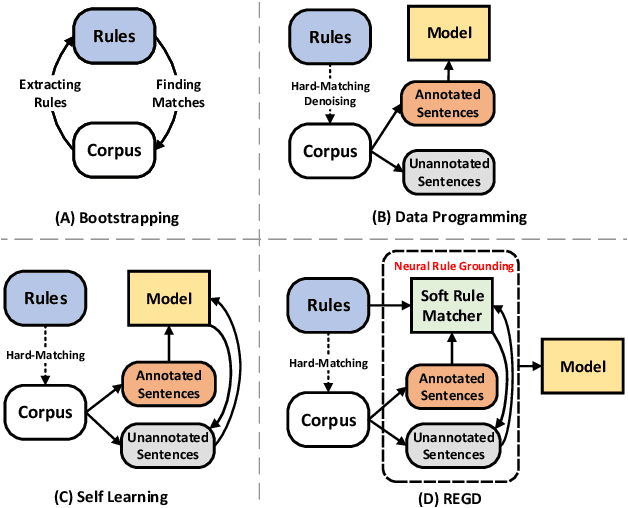
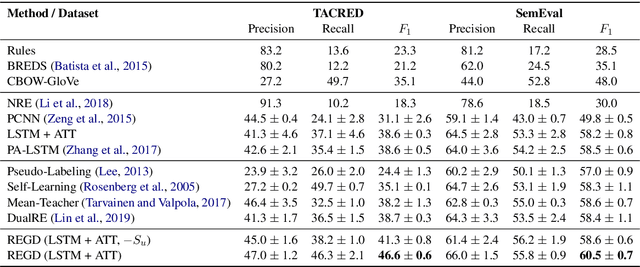

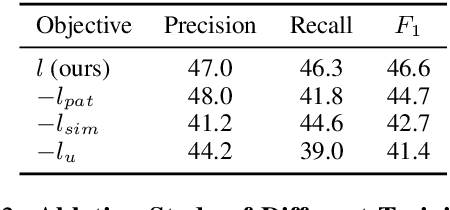
While deep neural models have gained successes on information extraction tasks, they become less reliable when the amount of labeled data is limited. In this paper, we study relation extraction (RE) under low-resource setting, where only some (hand-built) labeling rules are provided for learning a neural model over a large, unlabeled corpus. To overcome the low-coverage issue of current bootstrapping methods (i.e., hard grounding of rules), we propose a Neural Rule Grounding (REGD) framework for jointly learning a relation extraction module (with flexible neural architecture) and a sentence-rule soft matching module. The soft matching module extends the coverage of rules on semantically similar instances and augments the learning on unlabeled corpus. Experiments on two public datasets demonstrate the effectiveness of REGD when compared with both rule-based and semi-supervised baselines. Additionally, the learned soft matching module is able to predict on new relations with unseen rules, and can provide interpretation on matching results.
Learning Dual Retrieval Module for Semi-supervised Relation Extraction
Feb 22, 2019

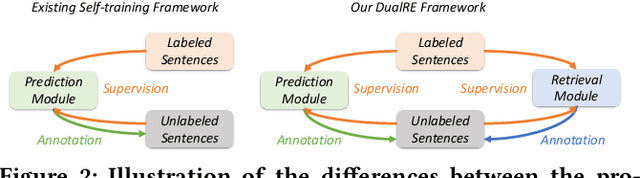
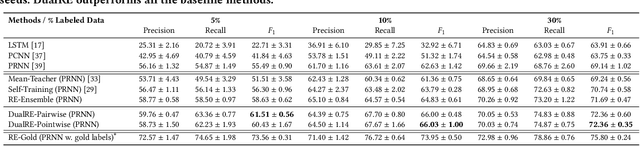
Relation extraction is an important task in structuring content of text data, and becomes especially challenging when learning with weak supervision---where only a limited number of labeled sentences are given and a large number of unlabeled sentences are available. Most existing work exploits unlabeled data based on the ideas of self-training (i.e., bootstrapping a model) and multi-view learning (e.g., ensembling multiple model variants). However, these methods either suffer from the issue of semantic drift, or do not fully capture the problem characteristics of relation extraction. In this paper, we leverage a key insight that retrieving sentences expressing a relation is a dual task of predicting relation label for a given sentence---two tasks are complementary to each other and can be optimized jointly for mutual enhancement. To model this intuition, we propose DualRE, a principled framework that introduces a retrieval module which is jointly trained with the original relation prediction module. In this way, high-quality samples selected by retrieval module from unlabeled data can be used to improve prediction module, and vice versa. Experimental results\footnote{\small Code and data can be found at \url{https://github.com/INK-USC/DualRE}.} on two public datasets as well as case studies demonstrate the effectiveness of the DualRE approach.