 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dual Retrieval Module for Semi-supervised Relation Extraction
Paper and Code


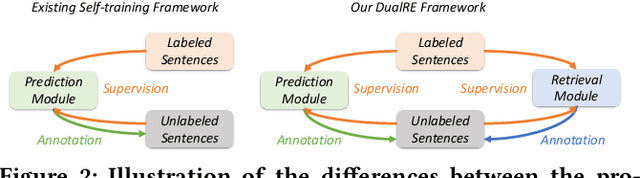
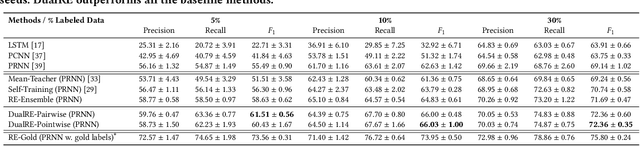
Relation extraction is an important task in structuring content of text data, and becomes especially challenging when learning with weak supervision---where only a limited number of labeled sentences are given and a large number of unlabeled sentences are available. Most existing work exploits unlabeled data based on the ideas of self-training (i.e., bootstrapping a model) and multi-view learning (e.g., ensembling multiple model variants). However, these methods either suffer from the issue of semantic drift, or do not fully capture the problem characteristics of relation extraction. In this paper, we leverage a key insight that retrieving sentences expressing a relation is a dual task of predicting relation label for a given sentence---two tasks are complementary to each other and can be optimized jointly for mutual enhancement. To model this intuition, we propose DualRE, a principled framework that introduces a retrieval module which is jointly trained with the original relation prediction module. In this way, high-quality samples selected by retrieval module from unlabeled data can be used to improve prediction module, and vice versa. Experimental results\footnote{\small Code and data can be found at \url{https://github.com/INK-USC/DualRE}.} on two public datasets as well as case studies demonstrate the effectiveness of the DualRE approach.