 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGREASE: Generate Factual and Counterfactual Explanations for GNN-based Recommendations
Aug 04, 2022
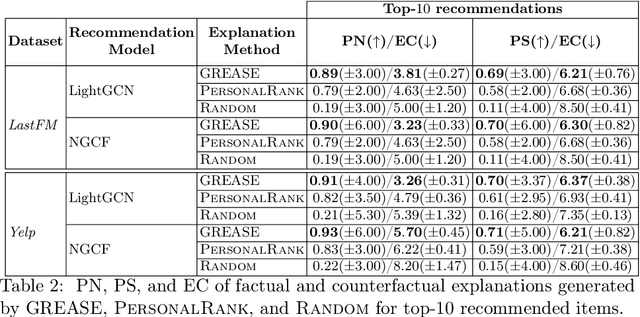
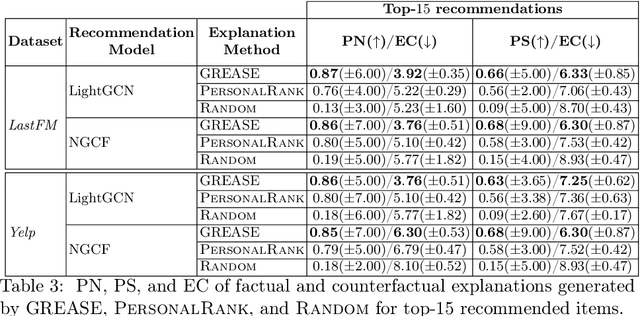
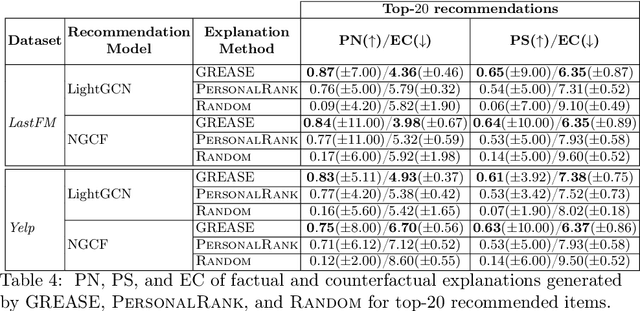
Recently, graph neural networks (GNNs) have been widely used to develop successful recommender systems. Although powerful, it is very difficult for a GNN-based recommender system to attach tangible explanations of why a specific item ends up in the list of suggestions for a given user. Indeed, explaining GNN-based recommendations is unique, and existing GNN explanation methods are inappropriate for two reasons. First, traditional GNN explanation methods are designed for node, edge, or graph classification tasks rather than ranking, as in recommender systems. Second, standard machine learning explanations are usually intended to support skilled decision-makers. Instead, recommendations are designed for any end-user, and thus their explanations should be provided in user-understandable ways. In this work, we propose GREASE, a novel method for explaining the suggestions provided by any black-box GNN-based recommender system. Specifically, GREASE first trains a surrogate model on a target user-item pair and its $l$-hop neighborhood. Then, it generates both factual and counterfactual explanations by finding optimal adjacency matrix perturbations to capture the sufficient and necessary conditions for an item to be recommended, respectively. Experimental results conducted on real-world datasets demonstrate that GREASE can generate concise and effective explanations for popular GNN-based recommender models.
ReLACE: Reinforcement Learning Agent for Counterfactual Explanations of Arbitrary Predictive Models
Oct 22, 2021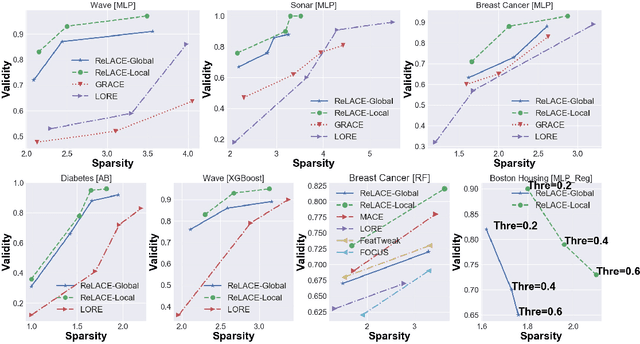

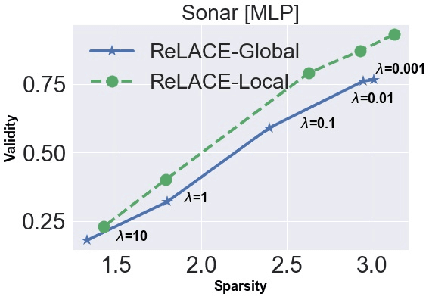

The demand for explainable machine learning (ML) models has been growing rapidly in recent years. Amongst the methods proposed to associate ML model predictions with human-understandable rationale, counterfactual explanations are one of the most popular. They consist of post-hoc rules derived from counterfactual examples (CFs), i.e., modified versions of input samples that result in alternative output responses from the predictive model to be explained. However, existing CF generation strategies either exploit the internals of specific models (e.g., random forests or neural networks), or depend on each sample's neighborhood, which makes them hard to be generalized for more complex models and inefficient for larger datasets. In this work, we aim to overcome these limitations and introduce a model-agnostic algorithm to generate optimal counterfactual explanations. Specifically, we formulate the problem of crafting CFs as a sequential decision-making task and then find the optimal CFs via deep reinforcement learning (DRL) with discrete-continuous hybrid action space. Differently from other techniques, our method is easily applied to any black-box model, as this resembles the environment that the DRL agent interacts with. In addition, we develop an algorithm to extract explainable decision rules from the DRL agent's policy, so as to make the process of generating CFs itself transparent. Extensive experiments conducted on several datasets have shown that our method outperforms existing CF generation baselines.
Costly Features Classification using Monte Carlo Tree Search
Feb 14, 2021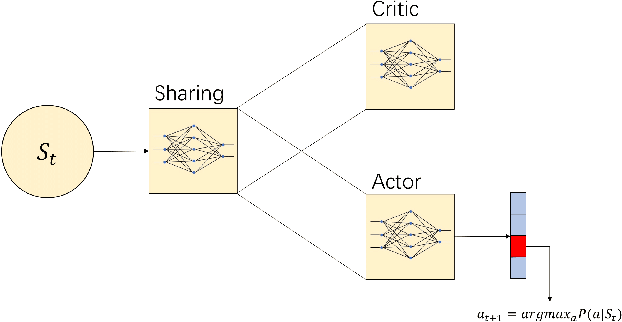
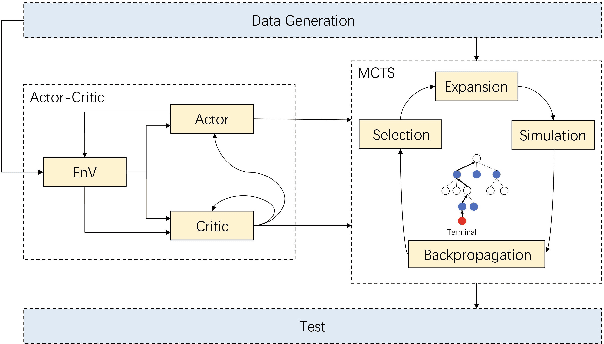
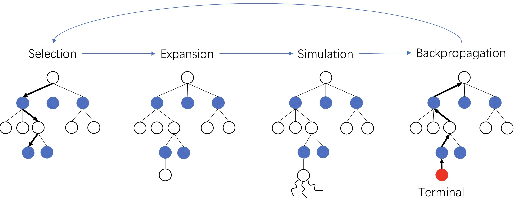
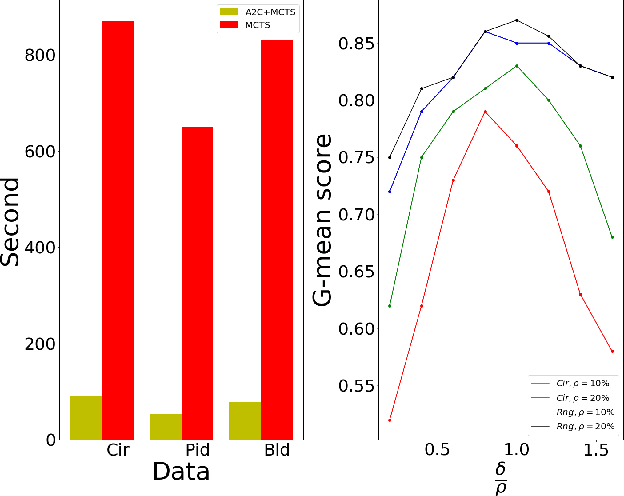
We consider the problem of costly feature classification, where we sequentially select the subset of features to make a balance between the classification error and the feature cost. In this paper, we first cast the task into a MDP problem and use Advantage Actor Critic algorithm to solve it. In order to further improve the agent's performance and make the policy explainable, we employ the Monte Carlo Tree Search to update the policy iteratively. During the procedure, we also consider its performance on the unbalanced dataset and its sensitivity to the missing value. We evaluate our model on multiple datasets and find it outperforms other methods.
Item Response Theory based Ensemble in Machine Learning
Nov 11, 2019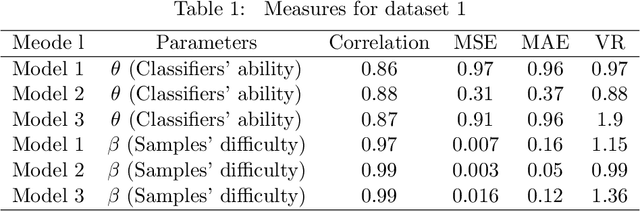
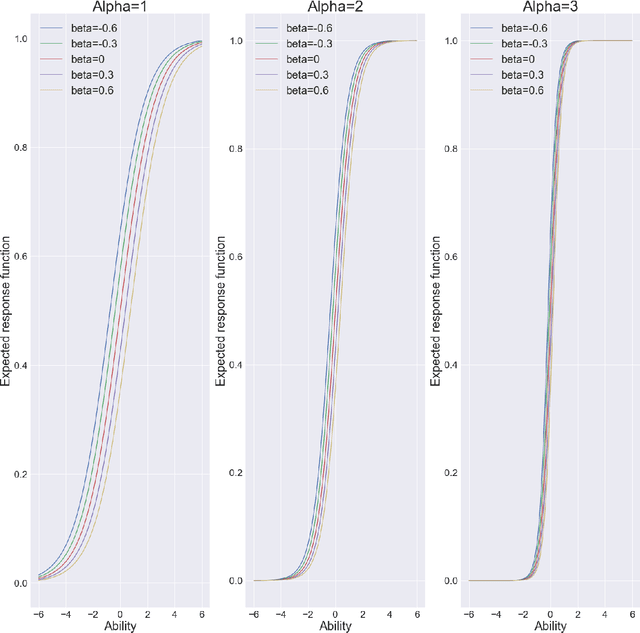


In this article, we propose a novel probabilistic framework to improve the accuracy of a weighted majority voting algorithm. In order to assign higher weights to the classifiers which can correctly classify hard-to-classify instances, we introduce the Item Response Theory (IRT) framework to evaluate the samples' difficulty and classifiers' ability simultaneously. Three models are created with different assumptions suitable for different cases. When making an inference, we keep a balance between the accuracy and complexity. In our experiment, all the base models are constructed by single trees via bootstrap. To explain the models, we illustrate how the IRT ensemble model constructs the classifying boundary. We also compare their performance with other widely used methods and show that our model performs well on 19 datasets.