 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Complex-Valued Vision Transformers for MRI Classification Directly from k-Space
Jan 26, 2026Deep learning applications in Magnetic Resonance Imaging (MRI) predominantly operate on reconstructed magnitude images, a process that discards phase information and requires computationally expensive transforms. Standard neural network architectures rely on local operations (convolutions or grid-patches) that are ill-suited for the global, non-local nature of raw frequency-domain (k-Space) data. In this work, we propose a novel complex-valued Vision Transformer (kViT) designed to perform classification directly on k-Space data. To bridge the geometric disconnect between current architectures and MRI physics, we introduce a radial k-Space patching strategy that respects the spectral energy distribution of the frequency-domain. Extensive experiments on the fastMRI and in-house datasets demonstrate that our approach achieves classification performance competitive with state-of-the-art image-domain baselines (ResNet, EfficientNet, ViT). Crucially, kViT exhibits superior robustness to high acceleration factors and offers a paradigm shift in computational efficiency, reducing VRAM consumption during training by up to 68$\times$ compared to standard methods. This establishes a pathway for resource-efficient, direct-from-scanner AI analysis.
PhaseGen: A Diffusion-Based Approach for Complex-Valued MRI Data Generation
Apr 10, 2025Magnetic resonance imaging (MRI) raw data, or k-Space data, is complex-valued, containing both magnitude and phase information. However, clinical and existing Artificial Intelligence (AI)-based methods focus only on magnitude images, discarding the phase data despite its potential for downstream tasks, such as tumor segmentation and classification. In this work, we introduce $\textit{PhaseGen}$, a novel complex-valued diffusion model for generating synthetic MRI raw data conditioned on magnitude images, commonly used in clinical practice. This enables the creation of artificial complex-valued raw data, allowing pretraining for models that require k-Space information. We evaluate PhaseGen on two tasks: skull-stripping directly in k-Space and MRI reconstruction using the publicly available FastMRI dataset. Our results show that training with synthetic phase data significantly improves generalization for skull-stripping on real-world data, with an increased segmentation accuracy from $41.1\%$ to $80.1\%$, and enhances MRI reconstruction when combined with limited real-world data. This work presents a step forward in utilizing generative AI to bridge the gap between magnitude-based datasets and the complex-valued nature of MRI raw data. This approach allows researchers to leverage the vast amount of avaliable image domain data in combination with the information-rich k-Space data for more accurate and efficient diagnostic tasks. We make our code publicly $\href{https://github.com/TIO-IKIM/PhaseGen}{\text{available here}}$.
CellViT++: Energy-Efficient and Adaptive Cell Segmentation and Classification Using Foundation Models
Jan 09, 2025



Digital Pathology is a cornerstone in the diagnosis and treatment of diseases. A key task in this field is the identification and segmentation of cells in hematoxylin and eosin-stained images. Existing methods for cell segmentation often require extensive annotated datasets for training and are limited to a predefined cell classification scheme. To overcome these limitations, we propose $\text{CellViT}^{{\scriptscriptstyle ++}}$, a framework for generalized cell segmentation in digital pathology. $\text{CellViT}^{{\scriptscriptstyle ++}}$ utilizes Vision Transformers with foundation models as encoders to compute deep cell features and segmentation masks simultaneously. To adapt to unseen cell types, we rely on a computationally efficient approach. It requires minimal data for training and leads to a drastically reduced carbon footprint. We demonstrate excellent performance on seven different datasets, covering a broad spectrum of cell types, organs, and clinical settings. The framework achieves remarkable zero-shot segmentation and data-efficient cell-type classification. Furthermore, we show that $\text{CellViT}^{{\scriptscriptstyle ++}}$ can leverage immunofluorescence stainings to generate training datasets without the need for pathologist annotations. The automated dataset generation approach surpasses the performance of networks trained on manually labeled data, demonstrating its effectiveness in creating high-quality training datasets without expert annotations. To advance digital pathology, $\text{CellViT}^{{\scriptscriptstyle ++}}$ is available as an open-source framework featuring a user-friendly, web-based interface for visualization and annotation. The code is available under https://github.com/TIO-IKIM/CellViT-plus-plus.
WisPerMed at "Discharge Me!": Advancing Text Generation in Healthcare with Large Language Models, Dynamic Expert Selection, and Priming Techniques on MIMIC-IV
May 18, 2024


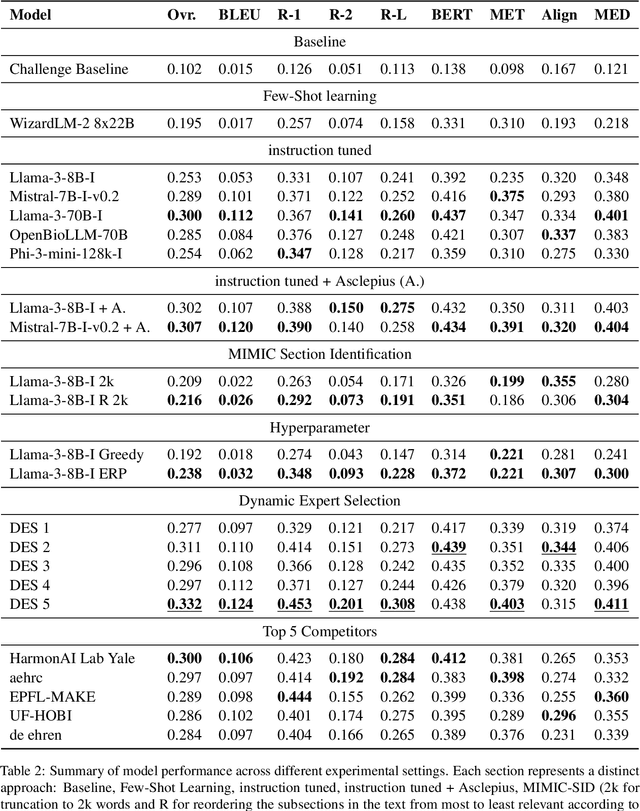
This study aims to leverage state of the art language models to automate generating the "Brief Hospital Course" and "Discharge Instructions" sections of Discharge Summaries from the MIMIC-IV dataset, reducing clinicians' administrative workload. We investigate how automation can improve documentation accuracy, alleviate clinician burnout, and enhance operational efficacy in healthcare facilities. This research was conducted within our participation in the Shared Task Discharge Me! at BioNLP @ ACL 2024. Various strategies were employed, including few-shot learning, instruction tuning, and Dynamic Expert Selection (DES), to develop models capable of generating the required text sections. Notably, utilizing an additional clinical domain-specific dataset demonstrated substantial potential to enhance clinical language processing. The DES method, which optimizes the selection of text outputs from multiple predictions, proved to be especially effective. It achieved the highest overall score of 0.332 in the competition, surpassing single-model outputs. This finding suggests that advanced deep learning methods in combination with DES can effectively automate parts of electronic health record documentation. These advancements could enhance patient care by freeing clinician time for patient interactions. The integration of text selection strategies represents a promising avenue for further research.