 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeTracer: Towards Traceable Text Generation via Claim-Level Grounding
Jan 07, 2026How can system-generated responses be efficiently verified, especially in the high-stakes biomedical domain? To address this challenge, we introduce eTracer, a plug-and-play framework that enables traceable text generation by grounding claims against contextual evidence. Through post-hoc grounding, each response claim is aligned with contextual evidence that either supports or contradicts it. Building on claim-level grounding results, eTracer not only enables users to precisely trace responses back to their contextual source but also quantifies response faithfulness, thereby enabling the verifiability and trustworthiness of generated responses. Experiments show that our claim-level grounding approach alleviates the limitations of conventional grounding methods in aligning generated statements with contextual sentence-level evidence, resulting in substantial improvements in overall grounding quality and user verification efficiency. The code and data are available at https://github.com/chubohao/eTracer.
PCoA: A New Benchmark for Medical Aspect-Based Summarization With Phrase-Level Context Attribution
Jan 06, 2026Verifying system-generated summaries remains challenging, as effective verification requires precise attribution to the source context, which is especially crucial in high-stakes medical domains. To address this challenge, we introduce PCoA, an expert-annotated benchmark for medical aspect-based summarization with phrase-level context attribution. PCoA aligns each aspect-based summary with its supporting contextual sentences and contributory phrases within them. We further propose a fine-grained, decoupled evaluation framework that independently assesses the quality of generated summaries, citations, and contributory phrases. Through extensive experiments, we validate the quality and consistency of the PCoA dataset and benchmark several large language models on the proposed task. Experimental results demonstrate that PCoA provides a reliable benchmark for evaluating system-generated summaries with phrase-level context attribution. Furthermore, comparative experiments show that explicitly identifying relevant sentences and contributory phrases before summarization can improve overall quality. The data and code are available at https://github.com/chubohao/PCoA.
WisPerMed at BioLaySumm: Adapting Autoregressive Large Language Models for Lay Summarization of Scientific Articles
May 20, 2024This paper details the efforts of the WisPerMed team in the BioLaySumm2024 Shared Task on automatic lay summarization in the biomedical domain, aimed at making scientific publications accessible to non-specialists. Large language models (LLMs), specifically the BioMistral and Llama3 models, were fine-tuned and employed to create lay summaries from complex scientific texts. The summarization performance was enhanced through various approaches, including instruction tuning, few-shot learning, and prompt variations tailored to incorporate specific context information. The experiments demonstrated that fine-tuning generally led to the best performance across most evaluated metrics. Few-shot learning notably improved the models' ability to generate relevant and factually accurate texts, particularly when using a well-crafted prompt. Additionally, a Dynamic Expert Selection (DES) mechanism to optimize the selection of text outputs based on readability and factuality metrics was developed. Out of 54 participants, the WisPerMed team reached the 4th place, measured by readability, factuality, and relevance. Determined by the overall score, our approach improved upon the baseline by approx. 5.5 percentage points and was only approx 1.5 percentage points behind the first place.
WisPerMed at "Discharge Me!": Advancing Text Generation in Healthcare with Large Language Models, Dynamic Expert Selection, and Priming Techniques on MIMIC-IV
May 18, 2024


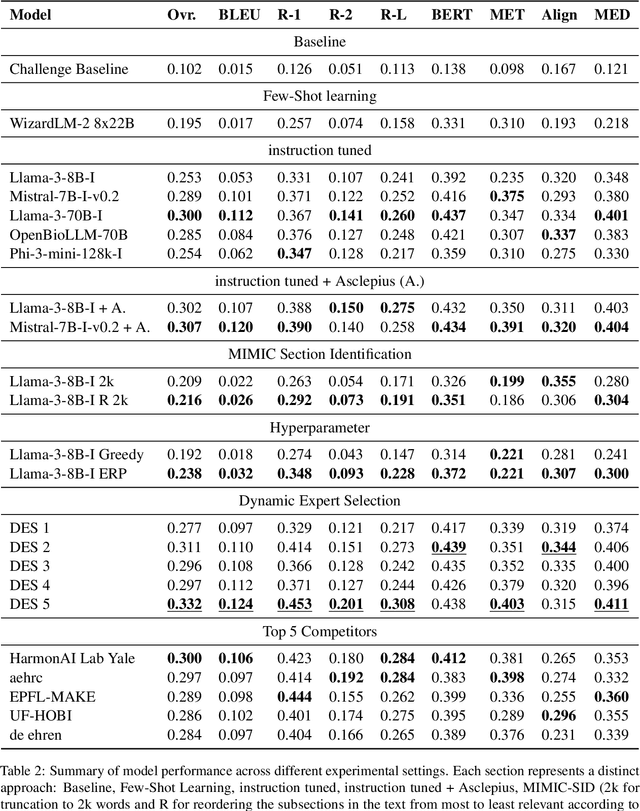
This study aims to leverage state of the art language models to automate generating the "Brief Hospital Course" and "Discharge Instructions" sections of Discharge Summaries from the MIMIC-IV dataset, reducing clinicians' administrative workload. We investigate how automation can improve documentation accuracy, alleviate clinician burnout, and enhance operational efficacy in healthcare facilities. This research was conducted within our participation in the Shared Task Discharge Me! at BioNLP @ ACL 2024. Various strategies were employed, including few-shot learning, instruction tuning, and Dynamic Expert Selection (DES), to develop models capable of generating the required text sections. Notably, utilizing an additional clinical domain-specific dataset demonstrated substantial potential to enhance clinical language processing. The DES method, which optimizes the selection of text outputs from multiple predictions, proved to be especially effective. It achieved the highest overall score of 0.332 in the competition, surpassing single-model outputs. This finding suggests that advanced deep learning methods in combination with DES can effectively automate parts of electronic health record documentation. These advancements could enhance patient care by freeing clinician time for patient interactions. The integration of text selection strategies represents a promising avenue for further research.