 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Examine Novelty of Patents?: Novelty Evaluation Based on the Correspondence between Patent Claim and Prior Art
Feb 10, 2025



Assessing the novelty of patent claims is a critical yet challenging task traditionally performed by patent examiners. While advancements in NLP have enabled progress in various patent-related tasks, novelty assessment remains unexplored. This paper introduces a novel challenge by evaluating the ability of large language models (LLMs) to assess patent novelty by comparing claims with cited prior art documents, following the process similar to that of patent examiners done. We present the first dataset specifically designed for novelty evaluation, derived from real patent examination cases, and analyze the capabilities of LLMs to address this task. Our study reveals that while classification models struggle to effectively assess novelty, generative models make predictions with a reasonable level of accuracy, and their explanations are accurate enough to understand the relationship between the target patent and prior art. These findings demonstrate the potential of LLMs to assist in patent evaluation, reducing the workload for both examiners and applicants. Our contributions highlight the limitations of current models and provide a foundation for improving AI-driven patent analysis through advanced models and refined datasets.
End-to-End Hyperspectral-Depth Imaging with Learned Diffractive Optics
Sep 01, 2020
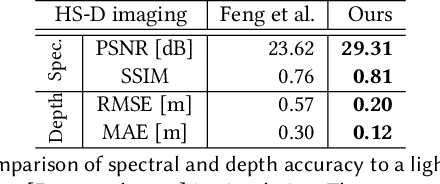
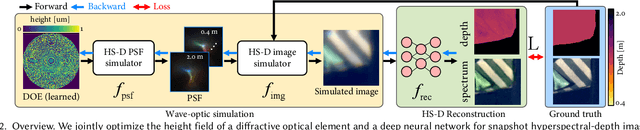
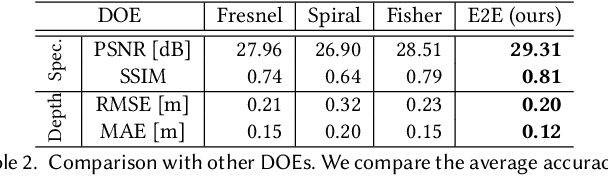
To extend the capabilities of spectral imaging, hyperspectral and depth imaging have been combined to capture the higher-dimensional visual information. However, the form factor of the combined imaging systems increases, limiting the applicability of this new technology. In this work, we propose a monocular imaging system for simultaneously capturing hyperspectral-depth (HS-D) scene information with an optimized diffractive optical element (DOE). In the training phase, this DOE is optimized jointly with a convolutional neural network to estimate HS-D data from a snapshot input. To study natural image statistics of this high-dimensional visual data and to enable such a machine learning-based DOE training procedure, we record two HS-D datasets. One is used for end-to-end optimization in deep optical HS-D imaging, and the other is used for enhancing reconstruction performance with a real-DOE prototype. The optimized DOE is fabricated with a grayscale lithography process and inserted into a portable HS-D camera prototype, which is shown to robustly capture HS-D information. In extensive evaluations, we demonstrate that our deep optical imaging system achieves state-of-the-art results for HS-D imaging and that the optimized DOE outperforms alternative optical designs.
Deep Optics for Single-shot High-dynamic-range Imaging
Aug 01, 2019
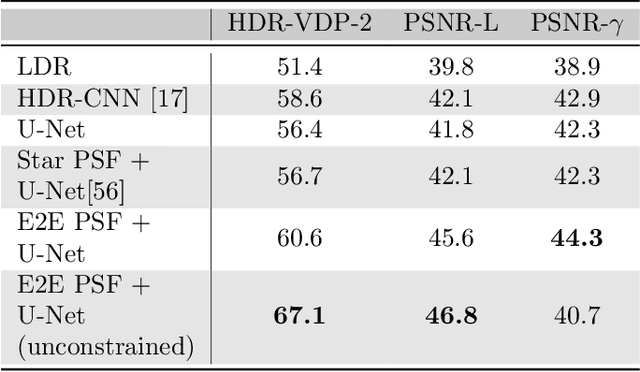

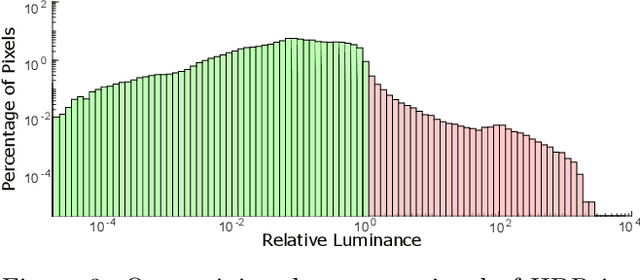
High-dynamic-range (HDR) imaging is crucial for many computer graphics and vision applications. Yet, acquiring HDR images with a single shot remains a challenging problem. Whereas modern deep learning approaches are successful at hallucinating plausible HDR content from a single low-dynamic-range (LDR) image, saturated scene details often cannot be faithfully recovered. Inspired by recent deep optical imaging approaches, we interpret this problem as jointly training an optical encoder and electronic decoder where the encoder is parameterized by the point spread function (PSF) of the lens, the bottleneck is the sensor with a limited dynamic range, and the decoder is a convolutional neural network (CNN). The lens surface is then jointly optimized with the CNN in a training phase; we fabricate this optimized optical element and attach it as a hardware add-on to a conventional camera during inference. In extensive simulations and with a physical prototype, we demonstrate that this end-to-end deep optical imaging approach to single-shot HDR imaging outperforms both purely CNN-based approaches and other PSF engineering approaches.