 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDER: IDempotent Experience Replay for Reliable Continual Learning
Mar 03, 2026Catastrophic forgetting, the tendency of neural networks to forget previously learned knowledge when learning new tasks, has been a major challenge in continual learning (CL). To tackle this challenge, CL methods have been proposed and shown to reduce forgetting. Furthermore, CL models deployed in mission-critical settings can benefit from uncertainty awareness by calibrating their predictions to reliably assess their confidences. However, existing uncertainty-aware continual learning methods suffer from high computational overhead and incompatibility with mainstream replay methods. To address this, we propose idempotent experience replay (IDER), a novel approach based on the idempotent property where repeated function applications yield the same output. Specifically, we first adapt the training loss to make model idempotent on current data streams. In addition, we introduce an idempotence distillation loss. We feed the output of the current model back into the old checkpoint and then minimize the distance between this reprocessed output and the original output of the current model. This yields a simple and effective new baseline for building reliable continual learners, which can be seamlessly integrated with other CL approaches. Extensive experiments on different CL benchmarks demonstrate that IDER consistently improves prediction reliability while simultaneously boosting accuracy and reducing forgetting. Our results suggest the potential of idempotence as a promising principle for deploying efficient and trustworthy continual learning systems in real-world applications.Our code is available at https://github.com/YutingLi0606/Idempotent-Continual-Learning.
ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering
Apr 03, 2016
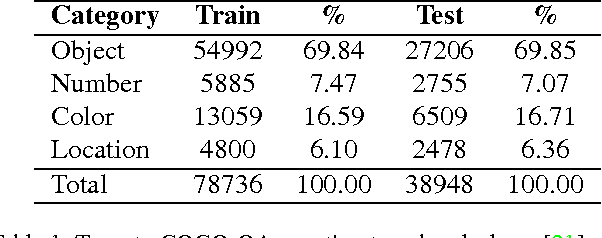
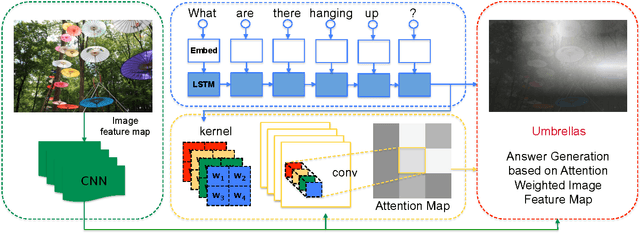
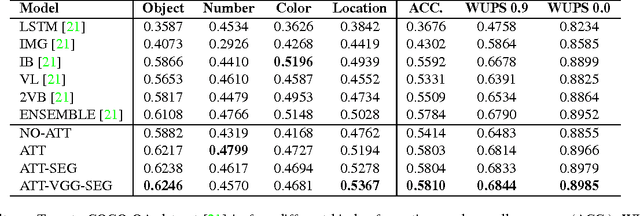
We propose a novel attention based deep learning architecture for visual question answering task (VQA). Given an image and an image related natural language question, VQA generates the natural language answer for the question. Generating the correct answers requires the model's attention to focus on the regions corresponding to the question, because different questions inquire about the attributes of different image regions. We introduce an attention based configurable convolutional neural network (ABC-CNN) to learn such question-guided attention. ABC-CNN determines an attention map for an image-question pair by convolving the image feature map with configurable convolutional kernels derived from the question's semantics. We evaluate the ABC-CNN architecture on three benchmark VQA datasets: Toronto COCO-QA, DAQUAR, and VQA dataset. ABC-CNN model achieves significant improvements over state-of-the-art methods on these datasets. The question-guided attention generated by ABC-CNN is also shown to reflect the regions that are highly relevant to the questions.
Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering
Nov 02, 2015

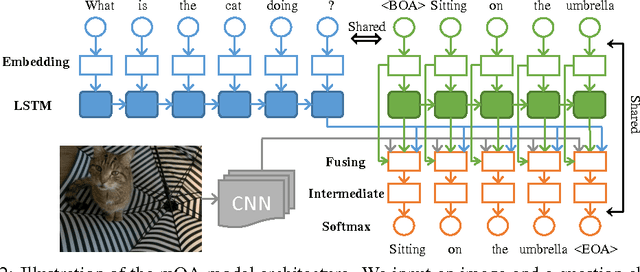

In this paper, we present the mQA model, which is able to answer questions about the content of an image. The answer can be a sentence, a phrase or a single word. Our model contains four components: a Long Short-Term Memory (LSTM) to extract the question representation, a Convolutional Neural Network (CNN) to extract the visual representation, an LSTM for storing the linguistic context in an answer, and a fusing component to combine the information from the first three components and generate the answer. We construct a Freestyle Multilingual Image Question Answering (FM-IQA) dataset to train and evaluate our mQA model. It contains over 150,000 images and 310,000 freestyle Chinese question-answer pairs and their English translations. The quality of the generated answers of our mQA model on this dataset is evaluated by human judges through a Turing Test. Specifically, we mix the answers provided by humans and our model. The human judges need to distinguish our model from the human. They will also provide a score (i.e. 0, 1, 2, the larger the better) indicating the quality of the answer. We propose strategies to monitor the quality of this evaluation process. The experiments show that in 64.7% of cases, the human judges cannot distinguish our model from humans. The average score is 1.454 (1.918 for human). The details of this work, including the FM-IQA dataset, can be found on the project page: http://idl.baidu.com/FM-IQA.html