 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering
Paper and Code
Apr 03, 2016
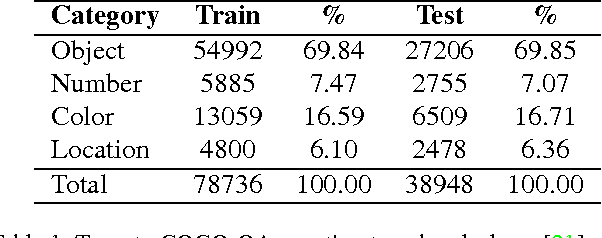
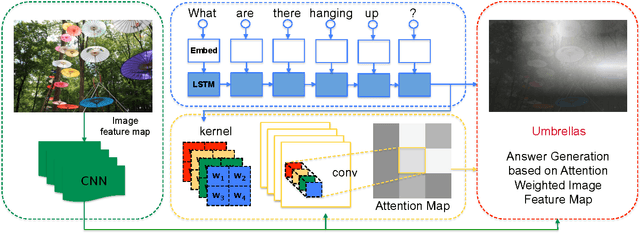
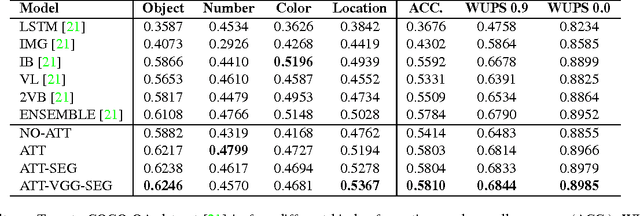
We propose a novel attention based deep learning architecture for visual question answering task (VQA). Given an image and an image related natural language question, VQA generates the natural language answer for the question. Generating the correct answers requires the model's attention to focus on the regions corresponding to the question, because different questions inquire about the attributes of different image regions. We introduce an attention based configurable convolutional neural network (ABC-CNN) to learn such question-guided attention. ABC-CNN determines an attention map for an image-question pair by convolving the image feature map with configurable convolutional kernels derived from the question's semantics. We evaluate the ABC-CNN architecture on three benchmark VQA datasets: Toronto COCO-QA, DAQUAR, and VQA dataset. ABC-CNN model achieves significant improvements over state-of-the-art methods on these datasets. The question-guided attention generated by ABC-CNN is also shown to reflect the regions that are highly relevant to the questions.