 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Easy to Hard: Learning Curricular Shape-aware Features for Robust Panoptic Scene Graph Generation
Jul 12, 2024Panoptic Scene Graph Generation (PSG) aims to generate a comprehensive graph-structure representation based on panoptic segmentation masks. Despite remarkable progress in PSG, almost all existing methods neglect the importance of shape-aware features, which inherently focus on the contours and boundaries of objects. To bridge this gap, we propose a model-agnostic Curricular shApe-aware FEature (CAFE) learning strategy for PSG. Specifically, we incorporate shape-aware features (i.e., mask features and boundary features) into PSG, moving beyond reliance solely on bbox features. Furthermore, drawing inspiration from human cognition, we propose to integrate shape-aware features in an easy-to-hard manner. To achieve this, we categorize the predicates into three groups based on cognition learning difficulty and correspondingly divide the training process into three stages. Each stage utilizes a specialized relation classifier to distinguish specific groups of predicates. As the learning difficulty of predicates increases, these classifiers are equipped with features of ascending complexity. We also incorporate knowledge distillation to retain knowledge acquired in earlier stages. Due to its model-agnostic nature, CAFE can be seamlessly incorporated into any PSG model. Extensive experiments and ablations on two PSG tasks under both robust and zero-shot PSG have attested to the superiority and robustness of our proposed CAFE, which outperforms existing state-of-the-art methods by a large margin.
Label Semantic Knowledge Distillation for Unbiased Scene Graph Generation
Aug 07, 2022



The Scene Graph Generation (SGG) task aims to detect all the objects and their pairwise visual relationships in a given image. Although SGG has achieved remarkable progress over the last few years, almost all existing SGG models follow the same training paradigm: they treat both object and predicate classification in SGG as a single-label classification problem, and the ground-truths are one-hot target labels. However, this prevalent training paradigm has overlooked two characteristics of current SGG datasets: 1) For positive samples, some specific subject-object instances may have multiple reasonable predicates. 2) For negative samples, there are numerous missing annotations. Regardless of the two characteristics, SGG models are easy to be confused and make wrong predictions. To this end, we propose a novel model-agnostic Label Semantic Knowledge Distillation (LS-KD) for unbiased SGG. Specifically, LS-KD dynamically generates a soft label for each subject-object instance by fusing a predicted Label Semantic Distribution (LSD) with its original one-hot target label. LSD reflects the correlations between this instance and multiple predicate categories. Meanwhile, we propose two different strategies to predict LSD: iterative self-KD and synchronous self-KD. Extensive ablations and results on three SGG tasks have attested to the superiority and generality of our proposed LS-KD, which can consistently achieve decent trade-off performance between different predicate categories.
NICEST: Noisy Label Correction and Training for Robust Scene Graph Generation
Jul 27, 2022


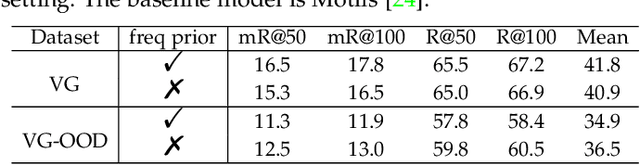
Nearly all existing scene graph generation (SGG) models have overlooked the ground-truth annotation qualities of mainstream SGG datasets, i.e., they assume: 1) all the manually annotated positive samples are equally correct; 2) all the un-annotated negative samples are absolutely background. In this paper, we argue that neither of the assumptions applies to SGG: there are numerous noisy ground-truth predicate labels that break these two assumptions and harm the training of unbiased SGG models. To this end, we propose a novel NoIsy label CorrEction and Sample Training strategy for SGG: NICEST. Specifically, it consists of two parts: NICE and NIST, which rule out these noisy label issues by generating high-quality samples and the effective training strategy, respectively. NICE first detects noisy samples and then reassigns them more high-quality soft predicate labels. NIST is a multi-teacher knowledge distillation based training strategy, which enables the model to learn unbiased fusion knowledge. And a dynamic trade-off weighting strategy in NIST is designed to penalize the bias of different teachers. Due to the model-agnostic nature of both NICE and NIST, our NICEST can be seamlessly incorporated into any SGG architecture to boost its performance on different predicate categories. In addition, to better evaluate the generalization of SGG models, we further propose a new benchmark VG-OOD, by re-organizing the prevalent VG dataset and deliberately making the predicate distributions of the training and test sets as different as possible for each subject-object category pair. This new benchmark helps disentangle the influence of subject-object category based frequency biases. Extensive ablations and results on different backbones and tasks have attested to the effectiveness and generalization ability of each component of NICEST.