 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNICEST: Noisy Label Correction and Training for Robust Scene Graph Generation
Paper and Code



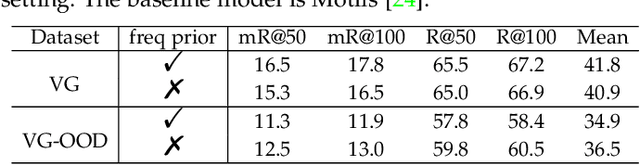
Nearly all existing scene graph generation (SGG) models have overlooked the ground-truth annotation qualities of mainstream SGG datasets, i.e., they assume: 1) all the manually annotated positive samples are equally correct; 2) all the un-annotated negative samples are absolutely background. In this paper, we argue that neither of the assumptions applies to SGG: there are numerous noisy ground-truth predicate labels that break these two assumptions and harm the training of unbiased SGG models. To this end, we propose a novel NoIsy label CorrEction and Sample Training strategy for SGG: NICEST. Specifically, it consists of two parts: NICE and NIST, which rule out these noisy label issues by generating high-quality samples and the effective training strategy, respectively. NICE first detects noisy samples and then reassigns them more high-quality soft predicate labels. NIST is a multi-teacher knowledge distillation based training strategy, which enables the model to learn unbiased fusion knowledge. And a dynamic trade-off weighting strategy in NIST is designed to penalize the bias of different teachers. Due to the model-agnostic nature of both NICE and NIST, our NICEST can be seamlessly incorporated into any SGG architecture to boost its performance on different predicate categories. In addition, to better evaluate the generalization of SGG models, we further propose a new benchmark VG-OOD, by re-organizing the prevalent VG dataset and deliberately making the predicate distributions of the training and test sets as different as possible for each subject-object category pair. This new benchmark helps disentangle the influence of subject-object category based frequency biases. Extensive ablations and results on different backbones and tasks have attested to the effectiveness and generalization ability of each component of NICEST.