 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Promise and Pitfalls of ChatGPT for Automated Code Generation
Nov 05, 2023This paper presents a comprehensive evaluation of the code generation capabilities of ChatGPT, a prominent large language model, compared to human programmers. A novel dataset of 131 code-generation prompts across 5 categories was curated to enable robust analysis. Code solutions were generated by both ChatGPT and humans for all prompts, resulting in 262 code samples. A meticulous manual assessment methodology prioritized evaluating correctness, comprehensibility, and security using 14 established code quality metrics. The key findings reveal ChatGPT's strengths in crafting concise, efficient code with advanced constructs, showcasing strengths in data analysis tasks (93.1% accuracy) but limitations in visual-graphical challenges. Comparative analysis with human code highlights ChatGPT's inclination towards modular design and superior error handling. Additionally, machine learning models effectively distinguished ChatGPT from human code with up to 88% accuracy, suggesting detectable coding style disparities. By providing profound insights into ChatGPT's code generation capabilities and limitations through quantitative metrics and qualitative analysis, this study makes valuable contributions toward advancing AI-based programming assistants. The curated dataset and methodology offer a robust foundation for future research in this nascent domain. All data and codes are available on https://github.com/DSAatUSU/ChatGPT-promises-and-pitfalls.
Enhancing the Performance of Automated Grade Prediction in MOOC using Graph Representation Learning
Oct 18, 2023
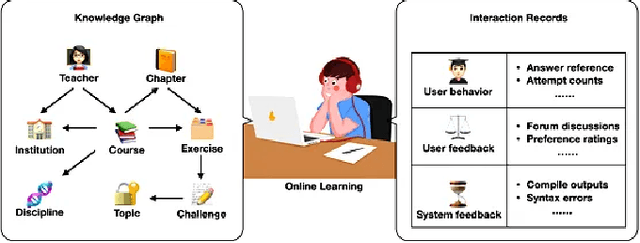
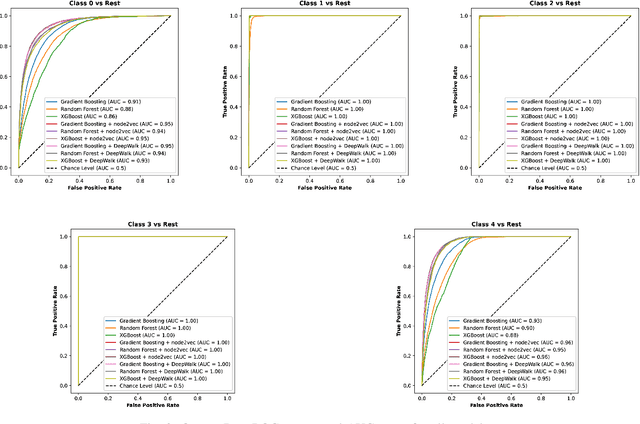

In recent years, Massive Open Online Courses (MOOCs) have gained significant traction as a rapidly growing phenomenon in online learning. Unlike traditional classrooms, MOOCs offer a unique opportunity to cater to a diverse audience from different backgrounds and geographical locations. Renowned universities and MOOC-specific providers, such as Coursera, offer MOOC courses on various subjects. Automated assessment tasks like grade and early dropout predictions are necessary due to the high enrollment and limited direct interaction between teachers and learners. However, current automated assessment approaches overlook the structural links between different entities involved in the downstream tasks, such as the students and courses. Our hypothesis suggests that these structural relationships, manifested through an interaction graph, contain valuable information that can enhance the performance of the task at hand. To validate this, we construct a unique knowledge graph for a large MOOC dataset, which will be publicly available to the research community. Furthermore, we utilize graph embedding techniques to extract latent structural information encoded in the interactions between entities in the dataset. These techniques do not require ground truth labels and can be utilized for various tasks. Finally, by combining entity-specific features, behavioral features, and extracted structural features, we enhance the performance of predictive machine learning models in student assignment grade prediction. Our experiments demonstrate that structural features can significantly improve the predictive performance of downstream assessment tasks. The code and data are available in \url{https://github.com/DSAatUSU/MOOPer_grade_prediction}
SentimentGPT: Exploiting GPT for Advanced Sentiment Analysis and its Departure from Current Machine Learning
Jul 23, 2023



This study presents a thorough examination of various Generative Pretrained Transformer (GPT) methodologies in sentiment analysis, specifically in the context of Task 4 on the SemEval 2017 dataset. Three primary strategies are employed: 1) prompt engineering using the advanced GPT-3.5 Turbo, 2) fine-tuning GPT models, and 3) an inventive approach to embedding classification. The research yields detailed comparative insights among these strategies and individual GPT models, revealing their unique strengths and potential limitations. Additionally, the study compares these GPT-based methodologies with other current, high-performing models previously used with the same dataset. The results illustrate the significant superiority of the GPT approaches in terms of predictive performance, more than 22\% in F1-score compared to the state-of-the-art. Further, the paper sheds light on common challenges in sentiment analysis tasks, such as understanding context and detecting sarcasm. It underscores the enhanced capabilities of the GPT models to effectively handle these complexities. Taken together, these findings highlight the promising potential of GPT models in sentiment analysis, setting the stage for future research in this field. The code can be found at https://github.com/DSAatUSU/SentimentGPT
The Authors Matter: Understanding and Mitigating Implicit Bias in Deep Text Classification
May 06, 2021
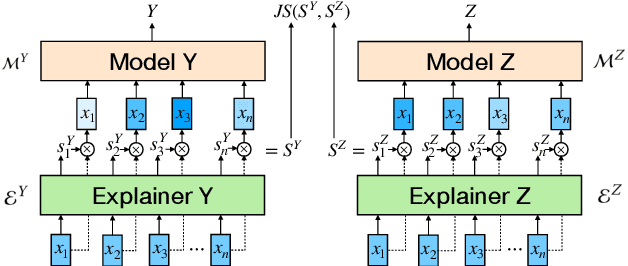

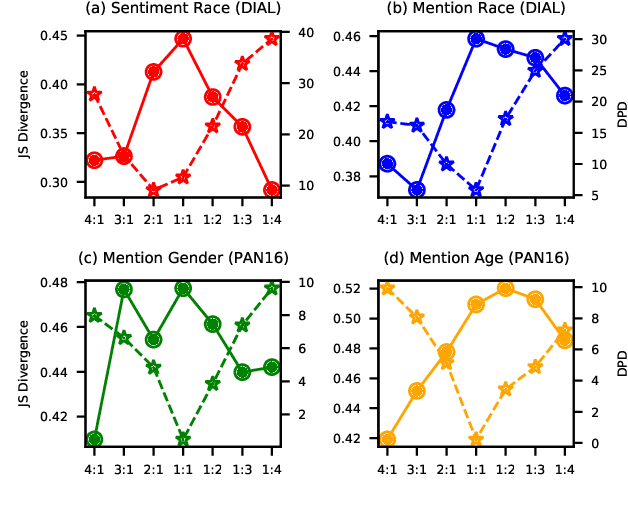
It is evident that deep text classification models trained on human data could be biased. In particular, they produce biased outcomes for texts that explicitly include identity terms of certain demographic groups. We refer to this type of bias as explicit bias, which has been extensively studied. However, deep text classification models can also produce biased outcomes for texts written by authors of certain demographic groups. We refer to such bias as implicit bias of which we still have a rather limited understanding. In this paper, we first demonstrate that implicit bias exists in different text classification tasks for different demographic groups. Then, we build a learning-based interpretation method to deepen our knowledge of implicit bias. Specifically, we verify that classifiers learn to make predictions based on language features that are related to the demographic attributes of the authors. Next, we propose a framework Debiased-TC to train deep text classifiers to make predictions on the right features and consequently mitigate implicit bias. We conduct extensive experiments on three real-world datasets. The results show that the text classification models trained under our proposed framework outperform traditional models significantly in terms of fairness, and also slightly in terms of classification performance.
Characterizing the Decision Boundary of Deep Neural Networks
Dec 26, 2019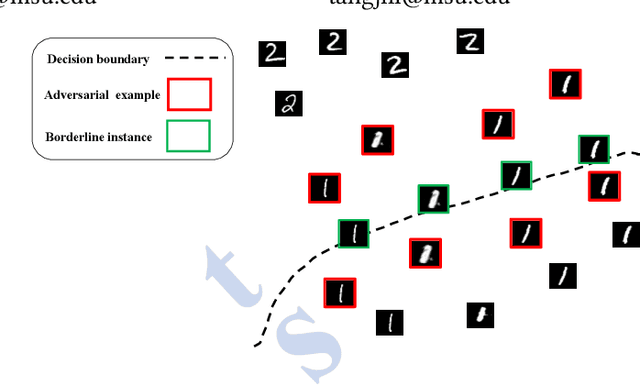

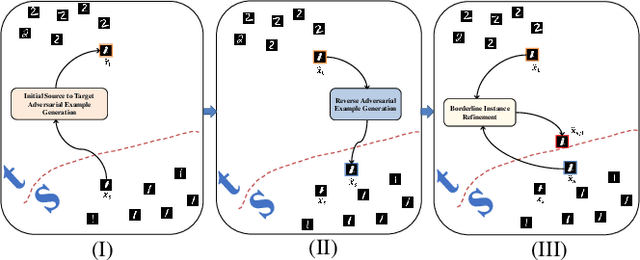

Deep neural networks and in particular, deep neural classifiers have become an integral part of many modern applications. Despite their practical success, we still have limited knowledge of how they work and the demand for such an understanding is evergrowing. In this regard, one crucial aspect of deep neural network classifiers that can help us deepen our knowledge about their decision-making behavior is to investigate their decision boundaries. Nevertheless, this is contingent upon having access to samples populating the areas near the decision boundary. To achieve this, we propose a novel approach we call Deep Decision boundary Instance Generation (DeepDIG). DeepDIG utilizes a method based on adversarial example generation as an effective way of generating samples near the decision boundary of any deep neural network model. Then, we introduce a set of important principled characteristics that take advantage of the generated instances near the decision boundary to provide multifaceted understandings of deep neural networks. We have performed extensive experiments on multiple representative datasets across various deep neural network models and characterized their decision boundaries.
Learning Hierarchical Discourse-level Structure for Fake News Detection
Apr 10, 2019

On the one hand, nowadays, fake news articles are easily propagated through various online media platforms and have become a grand threat to the trustworthiness of information. On the other hand, our understanding of the language of fake news is still minimal. Incorporating hierarchical discourse-level structure of fake and real news articles is one crucial step toward a better understanding of how these articles are structured. Nevertheless, this has rarely been investigated in the fake news detection domain and faces tremendous challenges. First, existing methods for capturing discourse-level structure rely on annotated corpora which are not available for fake news datasets. Second, how to extract out useful information from such discovered structures is another challenge. To address these challenges, we propose Hierarchical Discourse-level Structure for Fake news detection. HDSF learns and constructs a discourse-level structure for fake/real news articles in an automated and data-driven manner. Moreover, we identify insightful structure-related properties, which can explain the discovered structures and boost our understating of fake news. Conducted experiments show the effectiveness of the proposed approach. Further structural analysis suggests that real and fake news present substantial differences in the hierarchical discourse-level structures.
Deep Adversarial Network Alignment
Feb 27, 2019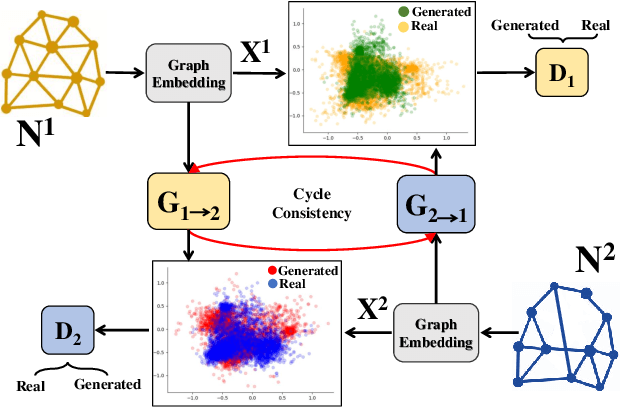

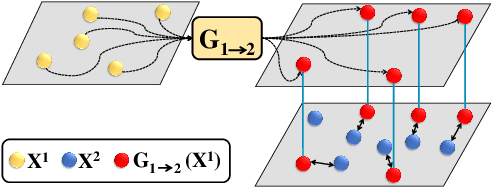

Network alignment, in general, seeks to discover the hidden underlying correspondence between nodes across two (or more) networks when given their network structure. However, most existing network alignment methods have added assumptions of additional constraints to guide the alignment, such as having a set of seed node-node correspondences across the networks or the existence of side-information. Instead, we seek to develop a general network alignment algorithm that makes no additional assumptions. Recently, network embedding has proven effective in many network analysis tasks, but embeddings of different networks are not aligned. Thus, we present our Deep Adversarial Network Alignment (DANA) framework that first uses deep adversarial learning to discover complex mappings for aligning the embedding distributions of the two networks. Then, using our learned mapping functions, DANA performs an efficient nearest neighbor node alignment. We perform experiments on real world datasets to show the effectiveness of our framework for first aligning the graph embedding distributions and then discovering node alignments that outperform existing methods.