 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Map-based Image Retrieval using Invariant Krawtchouk Moments
Nov 13, 2024With the widespread adoption of digital devices equipped with cameras and the rapid development of Internet technology, numerous content-based image retrieval systems and novel image feature extraction techniques have emerged in recent years. This paper introduces a saliency map-based image retrieval approach using invariant Krawtchouk moments (SM-IKM) to enhance retrieval speed and accuracy. The proposed method applies a global contrast-based salient region detection algorithm to create a saliency map that effectively isolates the foreground from the background. It then combines multiple orders of invariant Krawtchouk moments (IKM) with local binary patterns (LBPs) and color histograms to comprehensively represent the foreground and background. Additionally, it incorporates LBPs derived from the saliency map to improve discriminative power, facilitating more precise image differentiation. A bag-of-visual-words (BoVW) model is employed to generate a codebook for classification and discrimination. By using compact IKMs in the BoVW framework and integrating a range of region-based feature-including color histograms, LBPs, and saliency map-enhanced LBPs, our proposed SM-IKM achieves efficient and accurate image retrieval. xtensive experiments on publicly available datasets, such as Caltech 101 and Wang, demonstrate that SM-IKM outperforms recent state-of-the-art retrieval methods. The source code for SM-IKM is available at github.com/arnejad/SMIKM.
Residual Graph Convolutional Network for Bird's-Eye-View Semantic Segmentation
Dec 07, 2023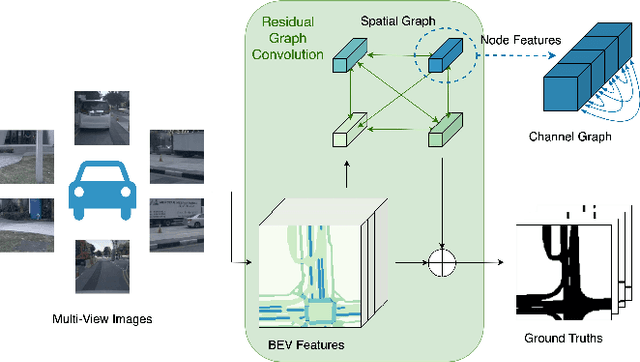



Retrieving spatial information and understanding the semantic information of the surroundings are important for Bird's-Eye-View (BEV) semantic segmentation. In the application of autonomous driving, autonomous vehicles need to be aware of their surroundings to drive safely. However, current BEV semantic segmentation techniques, deep Convolutional Neural Networks (CNNs) and transformers, have difficulties in obtaining the global semantic relationships of the surroundings at the early layers of the network. In this paper, we propose to incorporate a novel Residual Graph Convolutional (RGC) module in deep CNNs to acquire both the global information and the region-level semantic relationship in the multi-view image domain. Specifically, the RGC module employs a non-overlapping graph space projection to efficiently project the complete BEV information into graph space. It then builds interconnected spatial and channel graphs to extract spatial information between each node and channel information within each node (i.e., extract contextual relationships of the global features). Furthermore, it uses a downsample residual process to enhance the coordinate feature reuse to maintain the global information. The segmentation data augmentation and alignment module helps to simultaneously augment and align BEV features and ground truth to geometrically preserve their alignment to achieve better segmentation results. Our experimental results on the nuScenes benchmark dataset demonstrate that the RGC network outperforms four state-of-the-art networks and its four variants in terms of IoU and mIoU. The proposed RGC network achieves a higher mIoU of 3.1% than the best state-of-the-art network, BEVFusion. Code and models will be released.
Enhancing the Performance of Automated Grade Prediction in MOOC using Graph Representation Learning
Oct 18, 2023
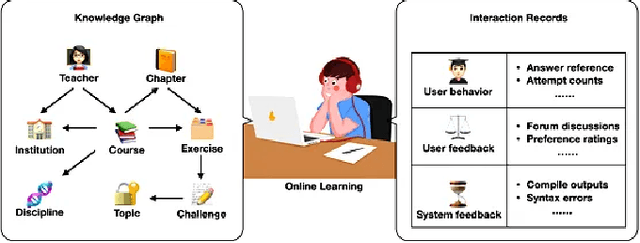
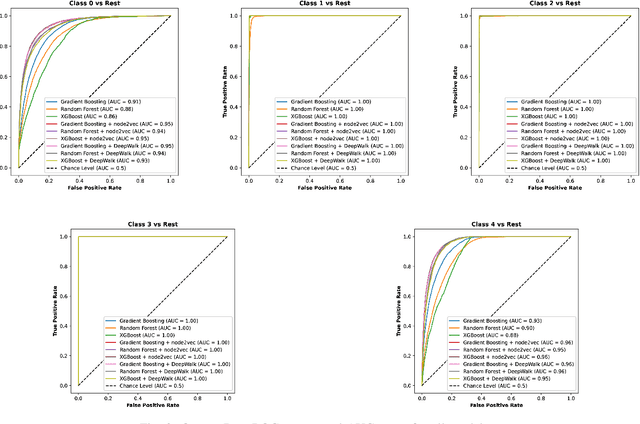

In recent years, Massive Open Online Courses (MOOCs) have gained significant traction as a rapidly growing phenomenon in online learning. Unlike traditional classrooms, MOOCs offer a unique opportunity to cater to a diverse audience from different backgrounds and geographical locations. Renowned universities and MOOC-specific providers, such as Coursera, offer MOOC courses on various subjects. Automated assessment tasks like grade and early dropout predictions are necessary due to the high enrollment and limited direct interaction between teachers and learners. However, current automated assessment approaches overlook the structural links between different entities involved in the downstream tasks, such as the students and courses. Our hypothesis suggests that these structural relationships, manifested through an interaction graph, contain valuable information that can enhance the performance of the task at hand. To validate this, we construct a unique knowledge graph for a large MOOC dataset, which will be publicly available to the research community. Furthermore, we utilize graph embedding techniques to extract latent structural information encoded in the interactions between entities in the dataset. These techniques do not require ground truth labels and can be utilized for various tasks. Finally, by combining entity-specific features, behavioral features, and extracted structural features, we enhance the performance of predictive machine learning models in student assignment grade prediction. Our experiments demonstrate that structural features can significantly improve the predictive performance of downstream assessment tasks. The code and data are available in \url{https://github.com/DSAatUSU/MOOPer_grade_prediction}
Structured Group Local Sparse Tracker
Mar 01, 2019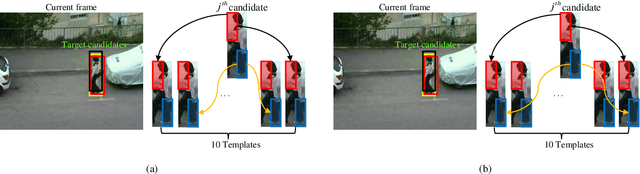
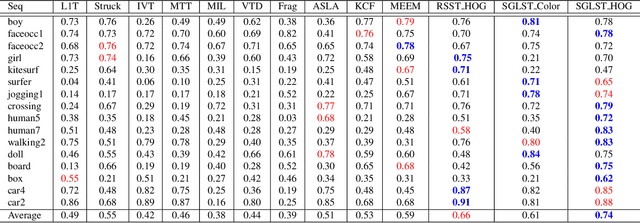

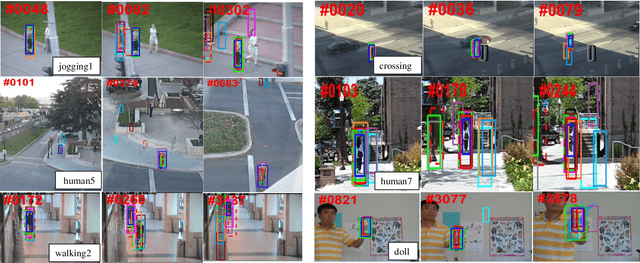
Sparse representation is considered as a viable solution to visual tracking. In this paper, we propose a structured group local sparse tracker (SGLST), which exploits local patches inside target candidates in the particle filter framework. Unlike the conventional local sparse trackers, the proposed optimization model in SGLST not only adopts local and spatial information of the target candidates but also attains the spatial layout structure among them by employing a group-sparsity regularization term. To solve the optimization model, we propose an efficient numerical algorithm consisting of two subproblems with the closed-form solutions. Both qualitative and quantitative evaluations on the benchmarks of challenging image sequences demonstrate the superior performance of the proposed tracker against several state-of-the-art trackers.
Robust Structured Group Local Sparse Tracker Using Deep Features
Feb 18, 2019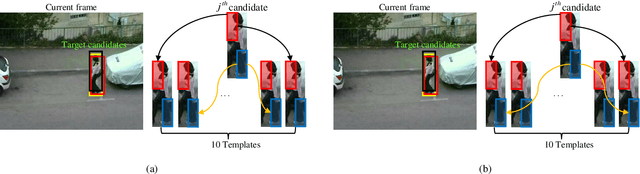



Sparse representation has recently been successfully applied in visual tracking. It utilizes a set of templates to represent target candidates and find the best one with the minimum reconstruction error as the tracking result. In this paper, we propose a robust deep features-based structured group local sparse tracker (DF-SGLST), which exploits the deep features of local patches inside target candidates and represents them by a set of templates in the particle filter framework. Unlike the conventional local sparse trackers, the proposed optimization model in DF-SGLST employs a group-sparsity regularization term to seamlessly adopt local and spatial information of the target candidates and attain the spatial layout structure among them. To solve the optimization model, we propose an efficient and fast numerical algorithm that consists of two subproblems with the closed-form solutions. Different evaluations in terms of success and precision on the benchmarks of challenging image sequences (e.g., OTB50 and OTB100) demonstrate the superior performance of the proposed tracker against several state-of-the-art trackers.
Robust Structured Multi-task Multi-view Sparse Tracking
Jun 06, 2018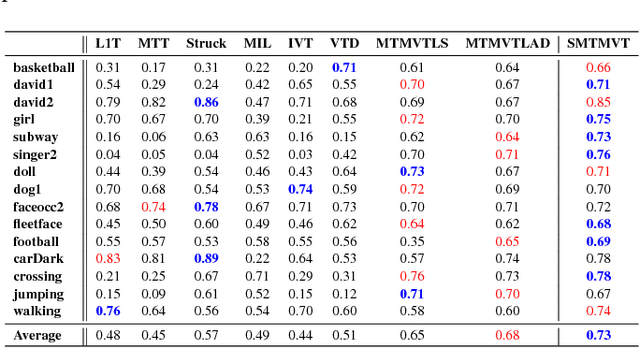

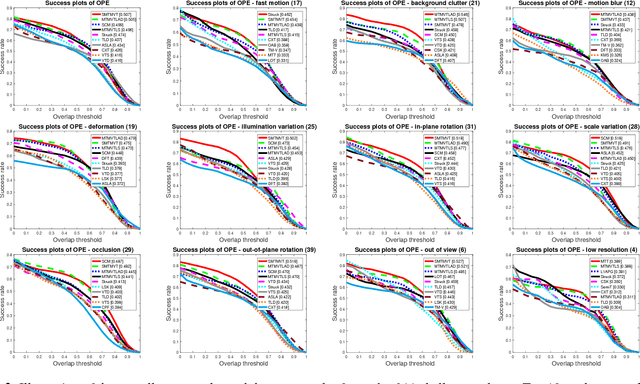
Sparse representation is a viable solution to visual tracking. In this paper, we propose a structured multi-task multi-view tracking (SMTMVT) method, which exploits the sparse appearance model in the particle filter framework to track targets under different challenges. Specifically, we extract features of the target candidates from different views and sparsely represent them by a linear combination of templates of different views. Unlike the conventional sparse trackers, SMTMVT not only jointly considers the relationship between different tasks and different views but also retains the structures among different views in a robust multi-task multi-view formulation. We introduce a numerical algorithm based on the proximal gradient method to quickly and effectively find the sparsity by dividing the optimization problem into two subproblems with the closed-form solutions. Both qualitative and quantitative evaluations on the benchmark of challenging image sequences demonstrate the superior performance of the proposed tracker against various state-of-the-art trackers.