 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSDA: High-frequency Shuffle Data Augmentation for Bird's-Eye-View Map Segmentation
Dec 09, 2024Autonomous driving has garnered significant attention in recent research, and Bird's-Eye-View (BEV) map segmentation plays a vital role in the field, providing the basis for safe and reliable operation. While data augmentation is a commonly used technique for improving BEV map segmentation networks, existing approaches predominantly focus on manipulating spatial domain representations. In this work, we investigate the potential of frequency domain data augmentation for camera-based BEV map segmentation. We observe that high-frequency information in camera images is particularly crucial for accurate segmentation. Based on this insight, we propose High-frequency Shuffle Data Augmentation (HSDA), a novel data augmentation strategy that enhances a network's ability to interpret high-frequency image content. This approach encourages the network to distinguish relevant high-frequency information from noise, leading to improved segmentation results for small and intricate image regions, as well as sharper edge and detail perception. Evaluated on the nuScenes dataset, our method demonstrates broad applicability across various BEV map segmentation networks, achieving a new state-of-the-art mean Intersection over Union (mIoU) of 61.3% for camera-only systems. This significant improvement underscores the potential of frequency domain data augmentation for advancing the field of autonomous driving perception. Code has been released: https://github.com/Zarhult/HSDA
Residual Graph Convolutional Network for Bird's-Eye-View Semantic Segmentation
Dec 07, 2023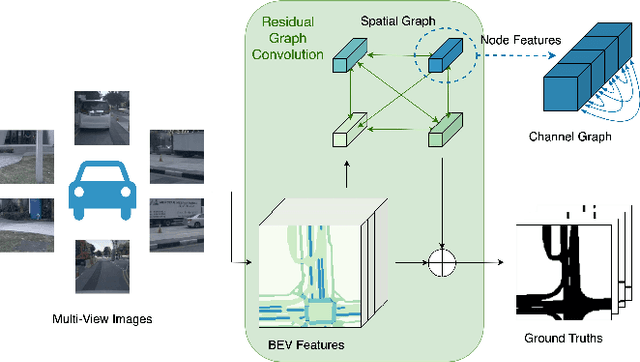



Retrieving spatial information and understanding the semantic information of the surroundings are important for Bird's-Eye-View (BEV) semantic segmentation. In the application of autonomous driving, autonomous vehicles need to be aware of their surroundings to drive safely. However, current BEV semantic segmentation techniques, deep Convolutional Neural Networks (CNNs) and transformers, have difficulties in obtaining the global semantic relationships of the surroundings at the early layers of the network. In this paper, we propose to incorporate a novel Residual Graph Convolutional (RGC) module in deep CNNs to acquire both the global information and the region-level semantic relationship in the multi-view image domain. Specifically, the RGC module employs a non-overlapping graph space projection to efficiently project the complete BEV information into graph space. It then builds interconnected spatial and channel graphs to extract spatial information between each node and channel information within each node (i.e., extract contextual relationships of the global features). Furthermore, it uses a downsample residual process to enhance the coordinate feature reuse to maintain the global information. The segmentation data augmentation and alignment module helps to simultaneously augment and align BEV features and ground truth to geometrically preserve their alignment to achieve better segmentation results. Our experimental results on the nuScenes benchmark dataset demonstrate that the RGC network outperforms four state-of-the-art networks and its four variants in terms of IoU and mIoU. The proposed RGC network achieves a higher mIoU of 3.1% than the best state-of-the-art network, BEVFusion. Code and models will be released.