 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperBERT: Mixing Hypergraph-Aware Layers with Language Models for Node Classification on Text-Attributed Hypergraphs
Feb 13, 2024Hypergraphs are marked by complex topology, expressing higher-order interactions among multiple entities with hyperedges. Lately, hypergraph-based deep learning methods to learn informative data representations for the problem of node classification on text-attributed hypergraphs have garnered increasing research attention. However, existing methods struggle to simultaneously capture the full extent of hypergraph structural information and the rich linguistic attributes inherent in the nodes attributes, which largely hampers their effectiveness and generalizability. To overcome these challenges, we explore ways to further augment a pretrained BERT model with specialized hypergraph-aware layers for the task of node classification. Such layers introduce higher-order structural inductive bias into the language model, thus improving the model's capacity to harness both higher-order context information from the hypergraph structure and semantic information present in text. In this paper, we propose a new architecture, HyperBERT, a mixed text-hypergraph model which simultaneously models hypergraph relational structure while maintaining the high-quality text encoding capabilities of a pre-trained BERT. Notably, HyperBERT presents results that achieve a new state-of-the-art on five challenging text-attributed hypergraph node classification benchmarks.
Language Model Knowledge Distillation for Efficient Question Answering in Spanish
Dec 07, 2023Recent advances in the development of pre-trained Spanish language models has led to significant progress in many Natural Language Processing (NLP) tasks, such as question answering. However, the lack of efficient models imposes a barrier for the adoption of such models in resource-constrained environments. Therefore, smaller distilled models for the Spanish language could be proven to be highly scalable and facilitate their further adoption on a variety of tasks and scenarios. In this work, we take one step in this direction by developing SpanishTinyRoBERTa, a compressed language model based on RoBERTa for efficient question answering in Spanish. To achieve this, we employ knowledge distillation from a large model onto a lighter model that allows for a wider implementation, even in areas with limited computational resources, whilst attaining negligible performance sacrifice. Our experiments show that the dense distilled model can still preserve the performance of its larger counterpart, while significantly increasing inference speedup. This work serves as a starting point for further research and investigation of model compression efforts for Spanish language models across various NLP tasks.
SQLformer: Deep Auto-Regressive Query Graph Generation for Text-to-SQL Translation
Oct 27, 2023


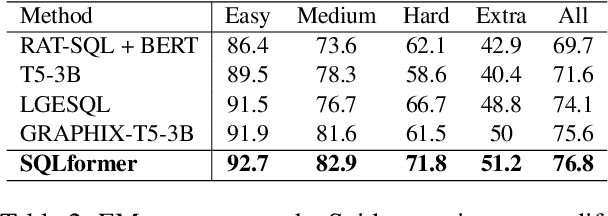
In recent years, there has been growing interest in text-to-SQL translation, which is the task of converting natural language questions into executable SQL queries. This technology is important for its potential to democratize data extraction from databases. However, some of its key hurdles include domain generalisation, which is the ability to adapt to previously unseen databases, and alignment of natural language questions with the corresponding SQL queries. To overcome these challenges, we introduce SQLformer, a novel Transformer architecture specifically crafted to perform text-to-SQL translation tasks. Our model predicts SQL queries as abstract syntax trees (ASTs) in an autoregressive way, incorporating structural inductive bias in the encoder and decoder layers. This bias, guided by database table and column selection, aids the decoder in generating SQL query ASTs represented as graphs in a Breadth-First Search canonical order. Comprehensive experiments illustrate the state-of-the-art performance of SQLformer in the challenging text-to-SQL Spider benchmark. Our implementation is available at https://github.com/AdrianBZG/SQLformer
Unsupervised Fact Verification by Language Model Distillation
Sep 28, 2023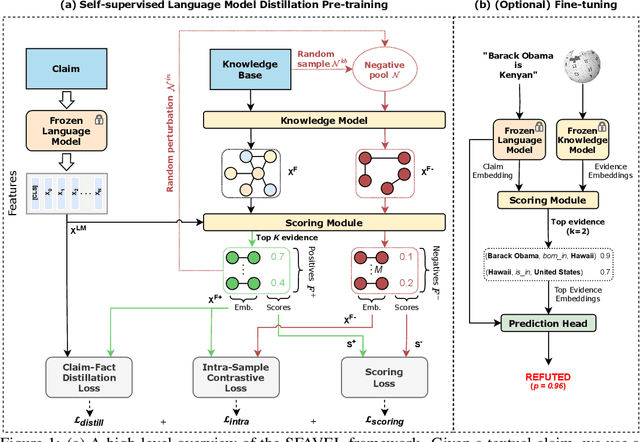
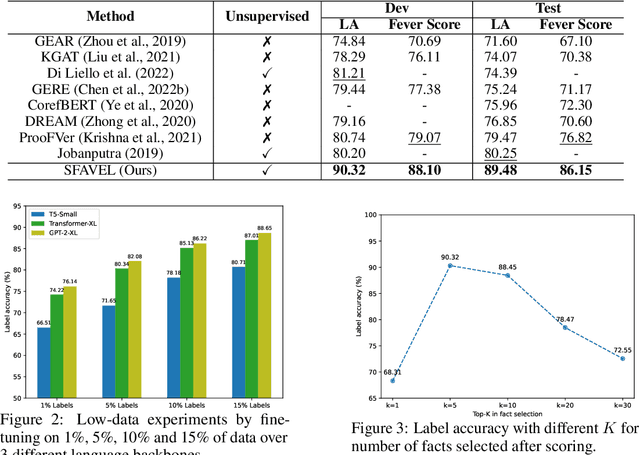

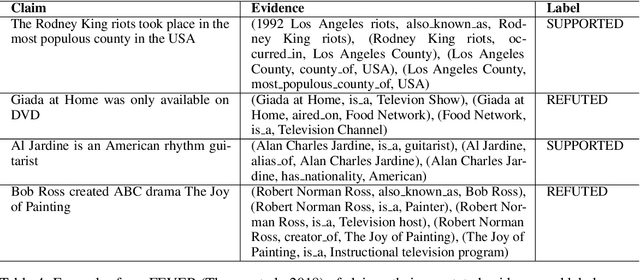
Unsupervised fact verification aims to verify a claim using evidence from a trustworthy knowledge base without any kind of data annotation. To address this challenge, algorithms must produce features for every claim that are both semantically meaningful, and compact enough to find a semantic alignment with the source information. In contrast to previous work, which tackled the alignment problem by learning over annotated corpora of claims and their corresponding labels, we propose SFAVEL (Self-supervised Fact Verification via Language Model Distillation), a novel unsupervised framework that leverages pre-trained language models to distil self-supervised features into high-quality claim-fact alignments without the need for annotations. This is enabled by a novel contrastive loss function that encourages features to attain high-quality claim and evidence alignments whilst preserving the semantic relationships across the corpora. Notably, we present results that achieve a new state-of-the-art on the standard FEVER fact verification benchmark (+8% accuracy) with linear evaluation.
Learning from learning machines: a new generation of AI technology to meet the needs of science
Nov 27, 2021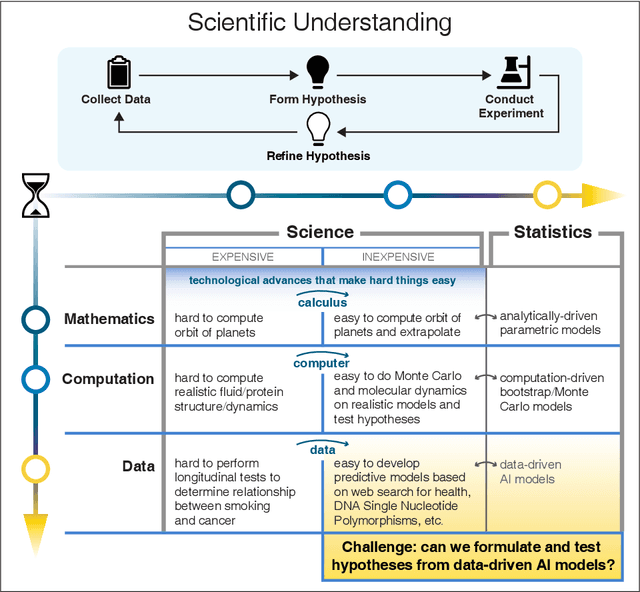

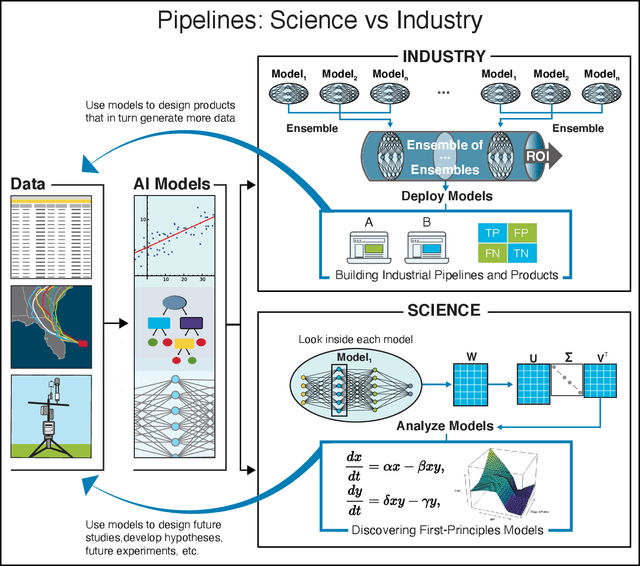
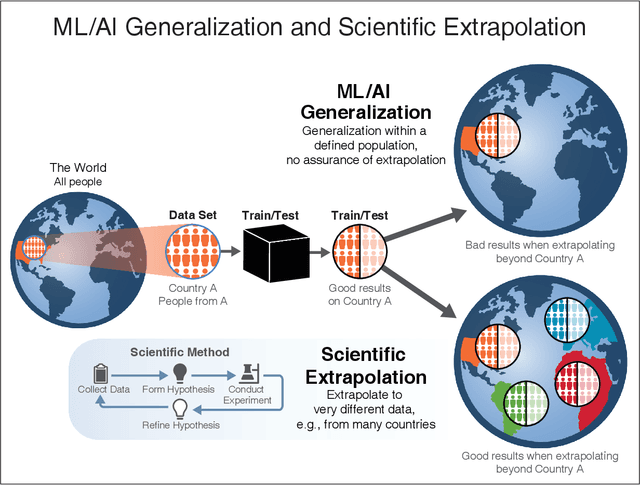
We outline emerging opportunities and challenges to enhance the utility of AI for scientific discovery. The distinct goals of AI for industry versus the goals of AI for science create tension between identifying patterns in data versus discovering patterns in the world from data. If we address the fundamental challenges associated with "bridging the gap" between domain-driven scientific models and data-driven AI learning machines, then we expect that these AI models can transform hypothesis generation, scientific discovery, and the scientific process itself.
Translating synthetic natural language to database queries: a polyglot deep learning framework
Apr 14, 2021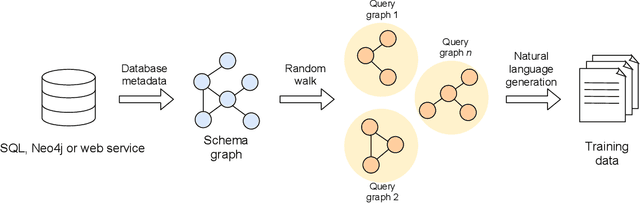
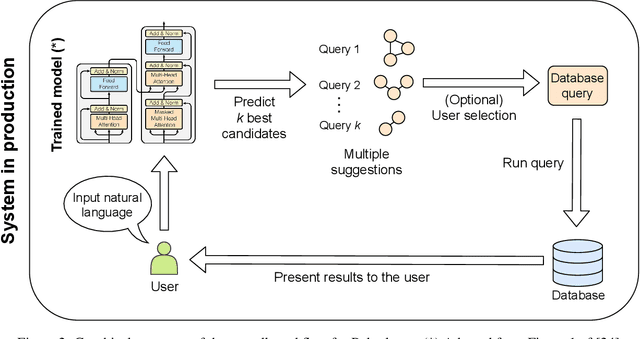
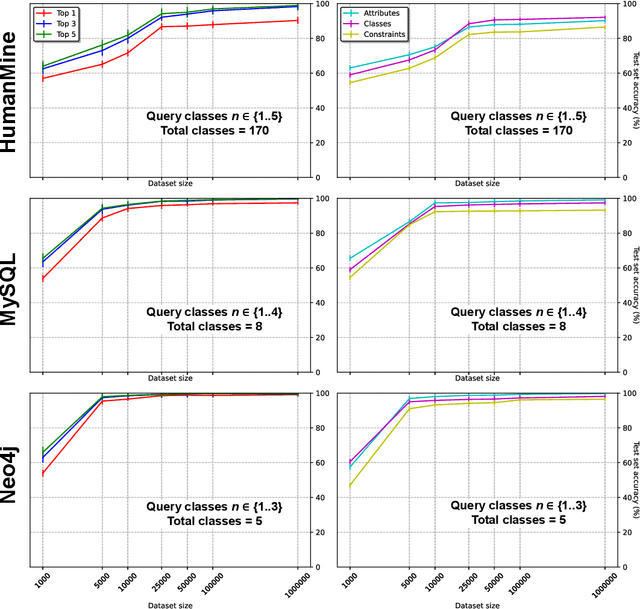
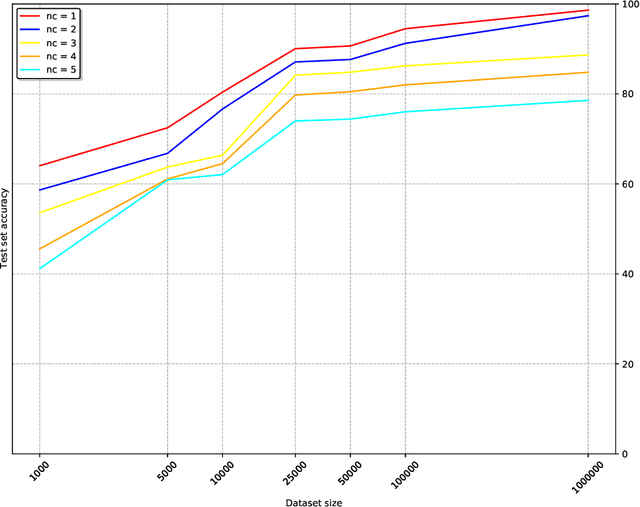
The number of databases as well as their size and complexity is increasing. This creates a barrier to use especially for non-experts, who have to come to grips with the nature of the data, the way it has been represented in the database, and the specific query languages or user interfaces by which data are accessed. These difficulties worsen in research settings, where it is common to work with many different databases. One approach to improving this situation is to allow users to pose their queries in natural language. In this work we describe a machine learning framework, Polyglotter, that in a general way supports the mapping of natural language searches to database queries. Importantly, it does not require the creation of manually annotated data for training and therefore can be applied easily to multiple domains. The framework is polyglot in the sense that it supports multiple different database engines that are accessed with a variety of query languages, including SQL and Cypher. Furthermore Polyglotter also supports multi-class queries. Our results indicate that our framework performs well on both synthetic and real databases, and may provide opportunities for database maintainers to improve accessibility to their resources.