 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating synthetic natural language to database queries: a polyglot deep learning framework
Paper and Code
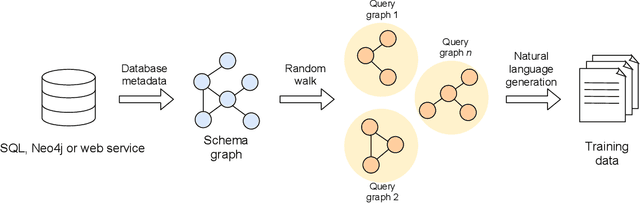
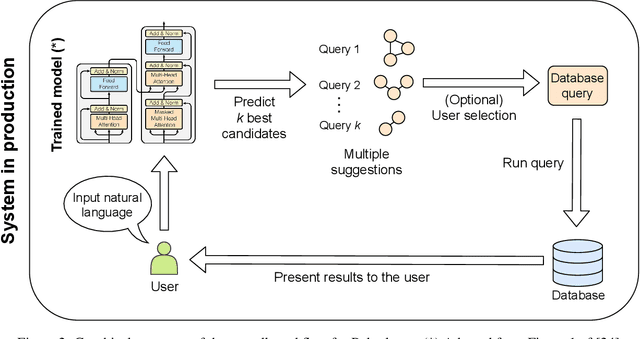
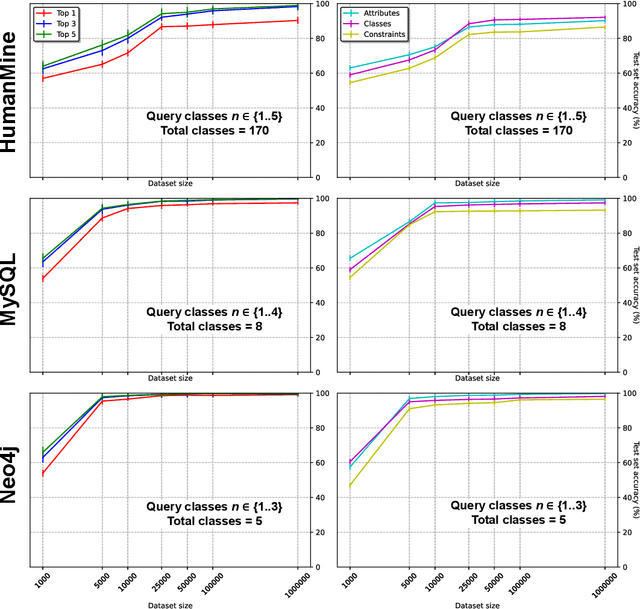
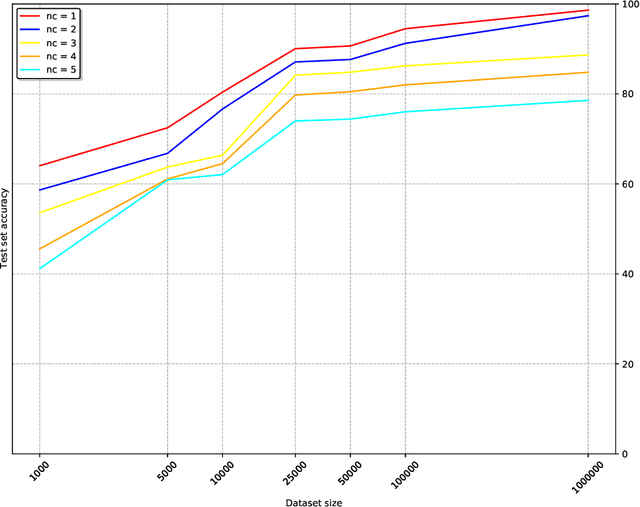
The number of databases as well as their size and complexity is increasing. This creates a barrier to use especially for non-experts, who have to come to grips with the nature of the data, the way it has been represented in the database, and the specific query languages or user interfaces by which data are accessed. These difficulties worsen in research settings, where it is common to work with many different databases. One approach to improving this situation is to allow users to pose their queries in natural language. In this work we describe a machine learning framework, Polyglotter, that in a general way supports the mapping of natural language searches to database queries. Importantly, it does not require the creation of manually annotated data for training and therefore can be applied easily to multiple domains. The framework is polyglot in the sense that it supports multiple different database engines that are accessed with a variety of query languages, including SQL and Cypher. Furthermore Polyglotter also supports multi-class queries. Our results indicate that our framework performs well on both synthetic and real databases, and may provide opportunities for database maintainers to improve accessibility to their resources.