 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Fact Verification by Language Model Distillation
Paper and Code
Sep 28, 2023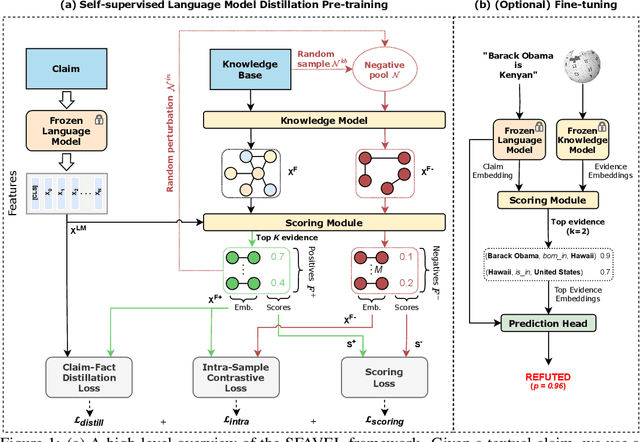
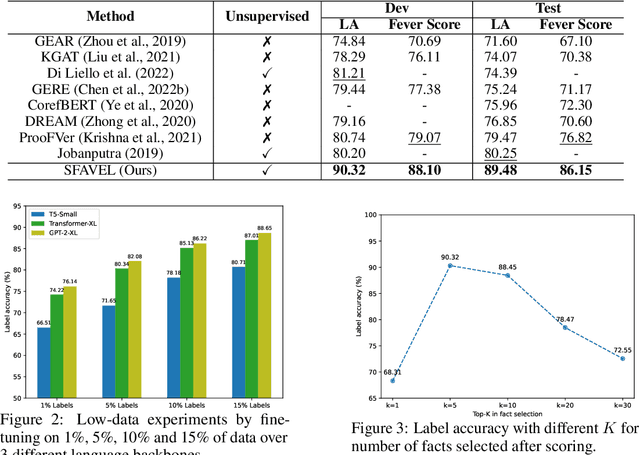

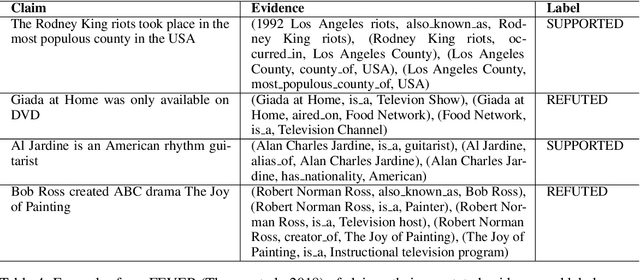
Unsupervised fact verification aims to verify a claim using evidence from a trustworthy knowledge base without any kind of data annotation. To address this challenge, algorithms must produce features for every claim that are both semantically meaningful, and compact enough to find a semantic alignment with the source information. In contrast to previous work, which tackled the alignment problem by learning over annotated corpora of claims and their corresponding labels, we propose SFAVEL (Self-supervised Fact Verification via Language Model Distillation), a novel unsupervised framework that leverages pre-trained language models to distil self-supervised features into high-quality claim-fact alignments without the need for annotations. This is enabled by a novel contrastive loss function that encourages features to attain high-quality claim and evidence alignments whilst preserving the semantic relationships across the corpora. Notably, we present results that achieve a new state-of-the-art on the standard FEVER fact verification benchmark (+8% accuracy) with linear evaluation.