 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need Reasoning to Learn Reasoning: The Limitations of Label-Free RL in Weak Base Models
Nov 07, 2025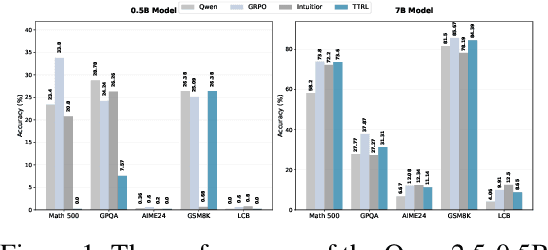
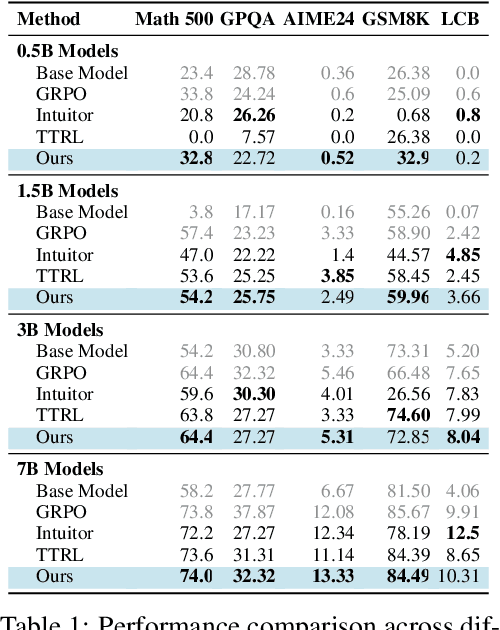

Recent advances in large language models have demonstrated the promise of unsupervised reinforcement learning (RL) methods for enhancing reasoning capabilities without external supervision. However, the generalizability of these label-free RL approaches to smaller base models with limited reasoning capabilities remains unexplored. In this work, we systematically investigate the performance of label-free RL methods across different model sizes and reasoning strengths, from 0.5B to 7B parameters. Our empirical analysis reveals critical limitations: label-free RL is highly dependent on the base model's pre-existing reasoning capability, with performance often degrading below baseline levels for weaker models. We find that smaller models fail to generate sufficiently long or diverse chain-of-thought reasoning to enable effective self-reflection, and that training data difficulty plays a crucial role in determining success. To address these challenges, we propose a simple yet effective method for label-free RL that utilizes curriculum learning to progressively introduce harder problems during training and mask no-majority rollouts during training. Additionally, we introduce a data curation pipeline to generate samples with predefined difficulty. Our approach demonstrates consistent improvements across all model sizes and reasoning capabilities, providing a path toward more robust unsupervised RL that can bootstrap reasoning abilities in resource-constrained models. We make our code available at https://github.com/BorealisAI/CuMa
ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
Oct 06, 2023Large Language Models (LLMs) with billions of parameters have drastically transformed AI applications. However, their demanding computation during inference has raised significant challenges for deployment on resource-constrained devices. Despite recent trends favoring alternative activation functions such as GELU or SiLU, known for increased computation, this study strongly advocates for reinstating ReLU activation in LLMs. We demonstrate that using the ReLU activation function has a negligible impact on convergence and performance while significantly reducing computation and weight transfer. This reduction is particularly valuable during the memory-bound inference step, where efficiency is paramount. Exploring sparsity patterns in ReLU-based LLMs, we unveil the reutilization of activated neurons for generating new tokens and leveraging these insights, we propose practical strategies to substantially reduce LLM inference computation up to three times, using ReLU activations with minimal performance trade-offs.
NeuMan: Neural Human Radiance Field from a Single Video
Mar 23, 2022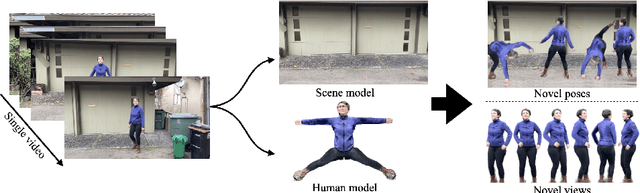

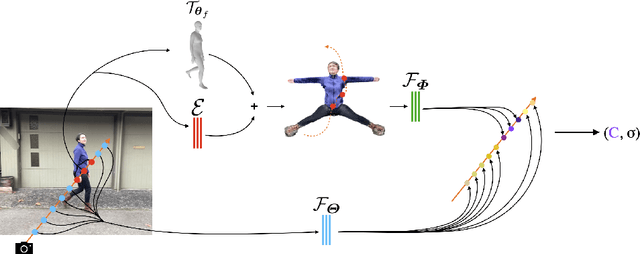
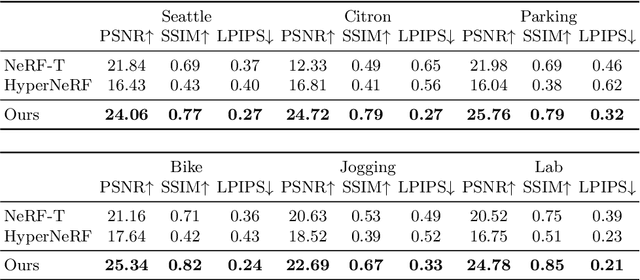
Photorealistic rendering and reposing of humans is important for enabling augmented reality experiences. We propose a novel framework to reconstruct the human and the scene that can be rendered with novel human poses and views from just a single in-the-wild video. Given a video captured by a moving camera, we train two NeRF models: a human NeRF model and a scene NeRF model. To train these models, we rely on existing methods to estimate the rough geometry of the human and the scene. Those rough geometry estimates allow us to create a warping field from the observation space to the canonical pose-independent space, where we train the human model in. Our method is able to learn subject specific details, including cloth wrinkles and accessories, from just a 10 seconds video clip, and to provide high quality renderings of the human under novel poses, from novel views, together with the background.
Automatic Segmentation of the Prostate on 3D Trans-rectal Ultrasound Images using Statistical Shape Models and Convolutional Neural Networks
Jun 17, 2021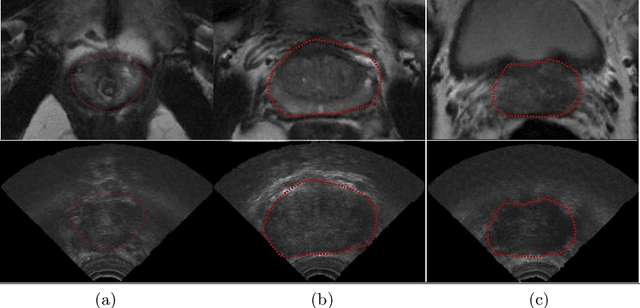
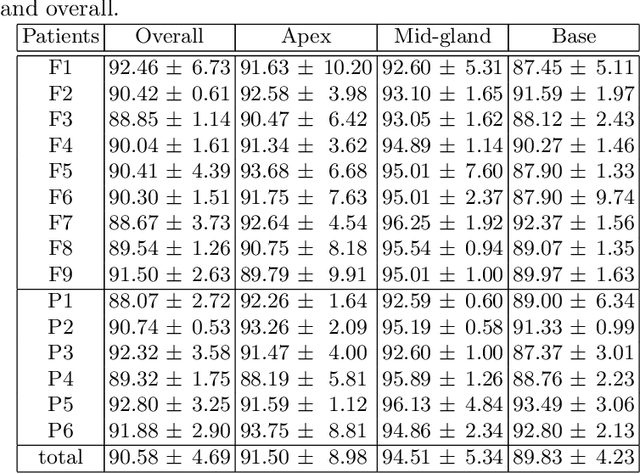
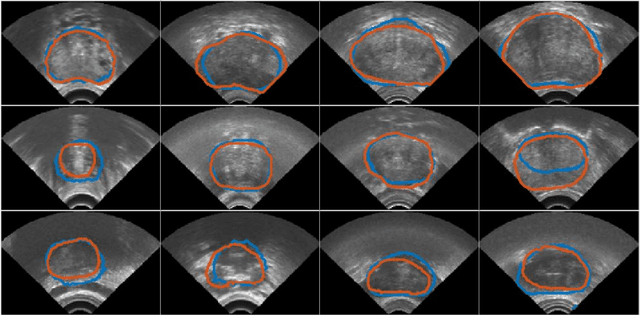
In this work we propose to segment the prostate on a challenging dataset of trans-rectal ultrasound (TRUS) images using convolutional neural networks (CNNs) and statistical shape models (SSMs). TRUS is commonly used for a number of image-guided interventions on the prostate. Fast and accurate segmentation on the organ in these images is crucial to planning and fusion with other modalities such as magnetic resonance images (MRIs) . However, TRUS has limited soft tissue contrast and signal to noise ratio which makes the task of segmenting the prostate challenging and subject to inter-observer and intra-observer variability. This is especially problematic at the base and apex where the gland boundary is hard to define. In this paper, we aim to tackle this problem by taking advantage of shape priors learnt on an MR dataset which has higher soft tissue contrast allowing the prostate to be contoured more accurately. We use this shape prior in combination with a prostate tissue probability map computed by a CNN for segmentation.
A deep learning-based method for prostate segmentation in T2-weighted magnetic resonance imaging
Jan 27, 2019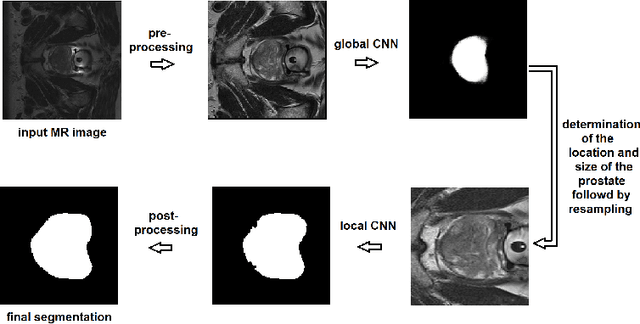

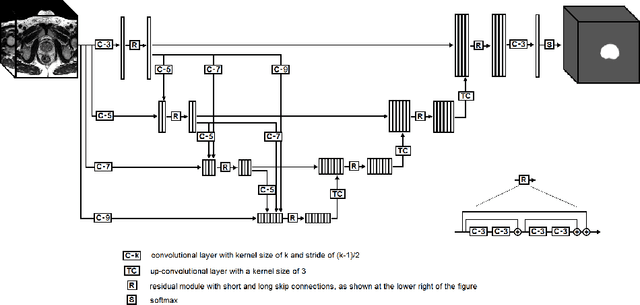
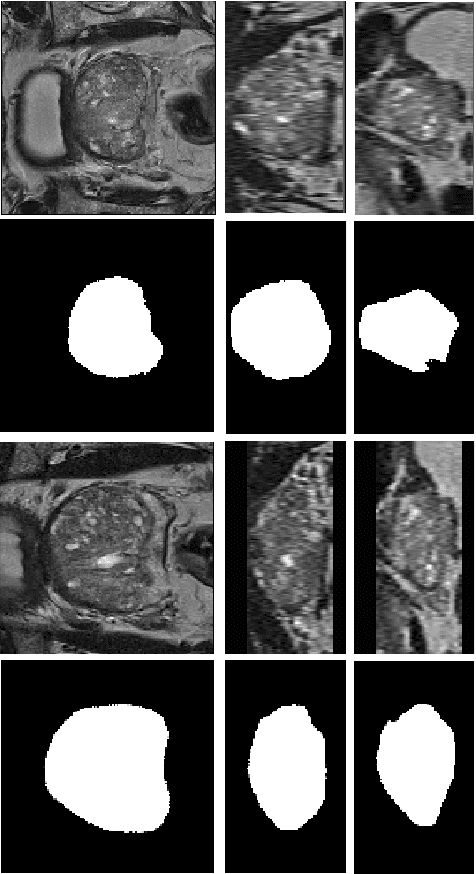
We propose a novel automatic method for accurate segmentation of the prostate in T2-weighted magnetic resonance imaging (MRI). Our method is based on convolutional neural networks (CNNs). Because of the large variability in the shape, size, and appearance of the prostate and the scarcity of annotated training data, we suggest training two separate CNNs. A global CNN will determine a prostate bounding box, which is then resampled and sent to a local CNN for accurate delineation of the prostate boundary. This way, the local CNN can effectively learn to segment the fine details that distinguish the prostate from the surrounding tissue using the small amount of available training data. To fully exploit the training data, we synthesize additional data by deforming the training images and segmentations using a learned shape model. We apply the proposed method on the PROMISE12 challenge dataset and achieve state of the art results. Our proposed method generates accurate, smooth, and artifact-free segmentations. On the test images, we achieve an average Dice score of 90.6 with a small standard deviation of 2.2, which is superior to all previous methods. Our two-step segmentation approach and data augmentation strategy may be highly effective in segmentation of other organs from small amounts of annotated medical images.