 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOGPO: Sample Efficient Full-Finetuning of Generative Control Policies
May 04, 2026Generative control policies (GCPs), such as diffusion- and flow-based control policies, have emerged as effective parameterizations for robot learning. This work introduces Off-policy Generative Policy Optimization (OGPO), a sample-efficient algorithm for finetuning GCPs that maintains off-policy critic networks to maximize data reuse and propagate policy gradients through the full generative process of the policy via a modified PPO objective, using critics as the terminal reward. OGPO achieves state-of-the-art performance on manipulation tasks spanning multi-task settings, high-precision insertion, and dexterous control. To our knowledge, it is also the only method that can fine-tune poorly-initialized behavior cloning policies to near full task-success with no expert data in the online replay buffer, and does so with few task-specific hyperparameter tuning. Through extensive empirical investigations, we demonstrate the OGPO drastically outperforms methods alternatives on policy steering and learning residual corrections, and identify the key mechanisms behind its performance. We further introduce practical stabilizers, including success-buffer regularization, conservative advantages, $χ^2$ regularization, and Q-variance reduction, to mitigate critic over-exploitation across state- and pixel-based settings. Beyond proposing OGPO, we conduct a systematic empirical study of GCP finetuning, identifying the stabilizing mechanisms and failure modes that govern successful off-policy full-policy improvement.
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Feb 05, 2026Flow and diffusion models produce high-quality samples, but adapting them to user preferences or constraints post-training remains costly and brittle, a challenge commonly called reward alignment. We argue that efficient reward alignment should be a property of the generative model itself, not an afterthought, and redesign the model for adaptability. We propose "Diamond Maps", stochastic flow map models that enable efficient and accurate alignment to arbitrary rewards at inference time. Diamond Maps amortize many simulation steps into a single-step sampler, like flow maps, while preserving the stochasticity required for optimal reward alignment. This design makes search, sequential Monte Carlo, and guidance scalable by enabling efficient and consistent estimation of the value function. Our experiments show that Diamond Maps can be learned efficiently via distillation from GLASS Flows, achieve stronger reward alignment performance, and scale better than existing methods. Our results point toward a practical route to generative models that can be rapidly adapted to arbitrary preferences and constraints at inference time.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021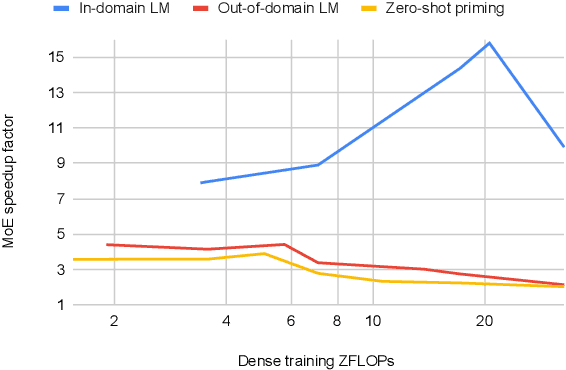
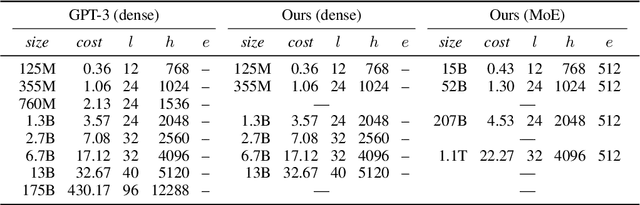
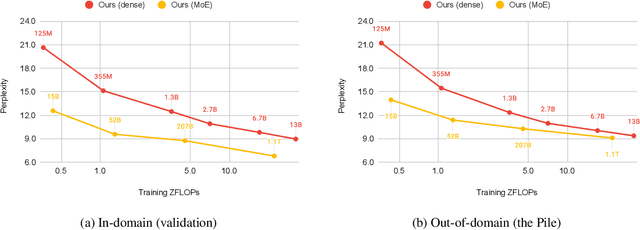
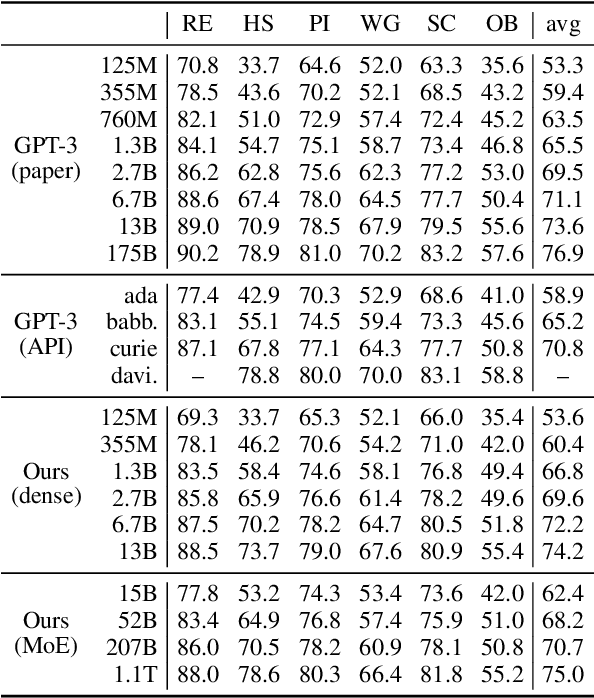
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.
Larger-Scale Transformers for Multilingual Masked Language Modeling
May 02, 2021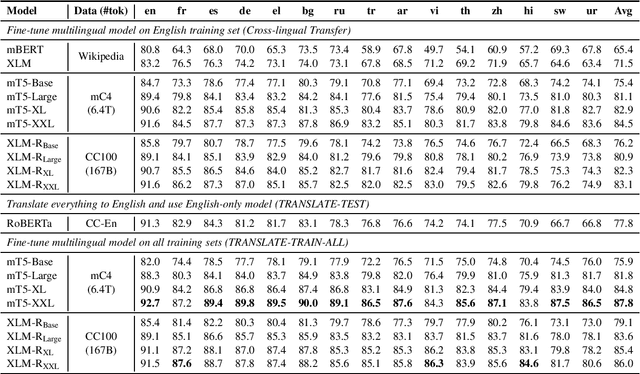
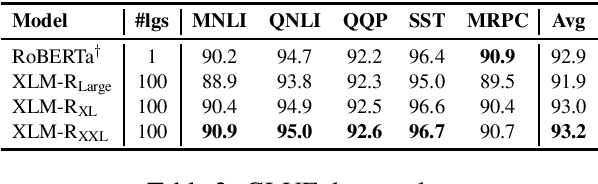

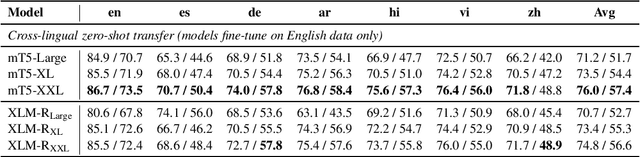
Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.