 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time monitoring of driver drowsiness on mobile platforms using 3D neural networks
Oct 15, 2019
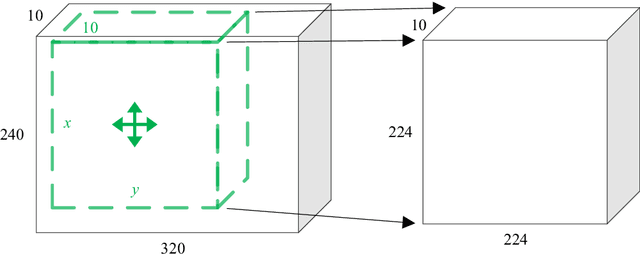

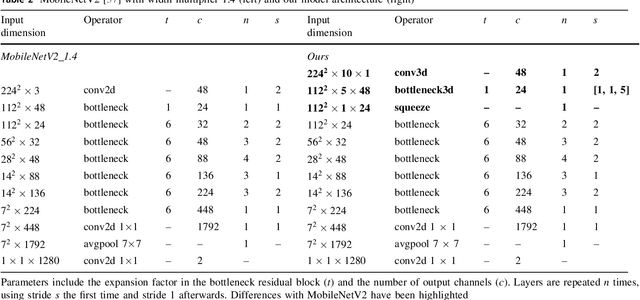
Driver drowsiness increases crash risk, leading to substantial road trauma each year. Drowsiness detection methods have received considerable attention, but few studies have investigated the implementation of a detection approach on a mobile phone. Phone applications reduce the need for specialised hardware and hence, enable a cost-effective roll-out of the technology across the driving population. While it has been shown that three-dimensional (3D) operations are more suitable for spatiotemporal feature learning, current methods for drowsiness detection commonly use frame-based, multi-step approaches. However, computationally expensive techniques that achieve superior results on action recognition benchmarks (e.g. 3D convolutions, optical flow extraction) create bottlenecks for real-time, safety-critical applications on mobile devices. Here, we show how depthwise separable 3D convolutions, combined with an early fusion of spatial and temporal information, can achieve a balance between high prediction accuracy and real-time inference requirements. In particular, increased accuracy is achieved when assessment requires motion information, for example, when sunglasses conceal the eyes. Further, a custom TensorFlow-based smartphone application shows the true impact of various approaches on inference times and demonstrates the effectiveness of real-time monitoring based on out-of-sample data to alert a drowsy driver. Our model is pre-trained on ImageNet and Kinetics and fine-tuned on a publicly available Driver Drowsiness Detection dataset. Fine-tuning on large naturalistic driving datasets could further improve accuracy to obtain robust in-vehicle performance. Overall, our research is a step towards practical deep learning applications, potentially preventing micro-sleeps and reducing road trauma.
* 13 pages, 2 figures, 'Online First' version. For associated mp4 files, see journal website
The 'Paris-end' of town? Urban typology through machine learning
Oct 08, 2019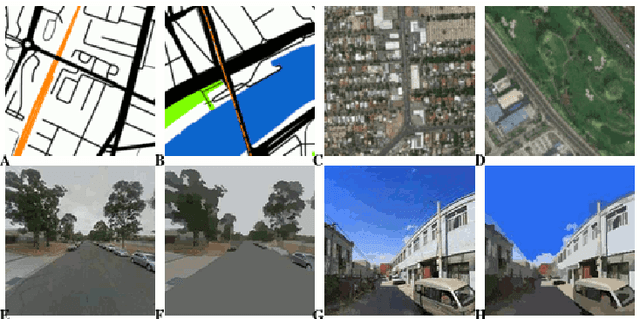
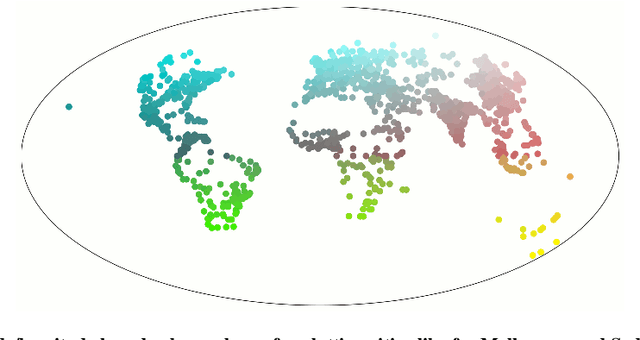
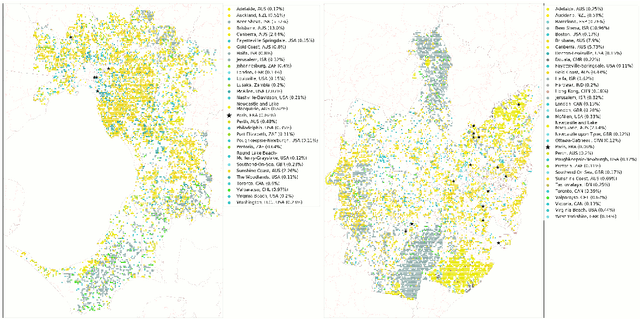
The confluence of recent advances in availability of geospatial information, computing power, and artificial intelligence offers new opportunities to understand how and where our cities differ or are alike. Departing from a traditional `top-down' analysis of urban design features, this project analyses millions of images of urban form (consisting of street view, satellite imagery, and street maps) to find shared characteristics. A (novel) neural network-based framework is trained with imagery from the largest 1692 cities in the world and the resulting models are used to compare within-city locations from Melbourne and Sydney to determine the closest connections between these areas and their international comparators. This work demonstrates a new, consistent, and objective method to begin to understand the relationship between cities and their health, transport, and environmental consequences of their design. The results show specific advantages and disadvantages using each type of imagery. Neural networks trained with map imagery will be highly influenced by the mix of roads, public transport, and green and blue space as well as the structure of these elements. The colours of natural and built features stand out as dominant characteristics in satellite imagery. The use of street view imagery will emphasise the features of a human scaled visual geography of streetscapes. Finally, and perhaps most importantly, this research also answers the age-old question, ``Is there really a `Paris-end' to your city?''.
Sky pixel detection in outdoor imagery using an adaptive algorithm and machine learning
Oct 08, 2019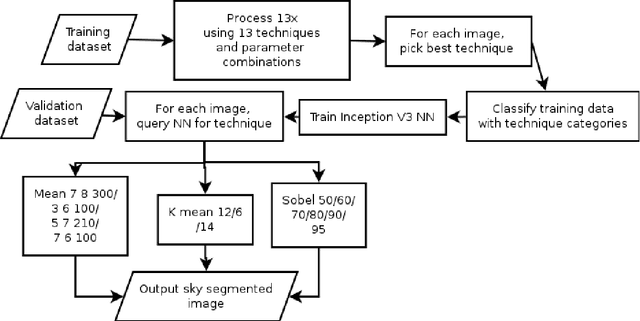



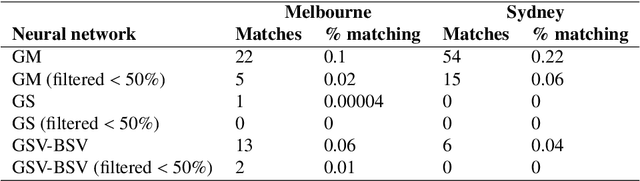
Computer vision techniques allow automated detection of sky pixels in outdoor imagery. Multiple applications exist for this information across a large number of research areas. In urban climate, sky detection is an important first step in gathering information about urban morphology and sky view factors. However, capturing accurate results remains challenging and becomes even more complex using imagery captured under a variety of lighting and weather conditions. To address this problem, we present a new sky pixel detection system demonstrated to produce accurate results using a wide range of outdoor imagery types. Images are processed using a selection of mean-shift segmentation, K-means clustering, and Sobel filters to mark sky pixels in the scene. The algorithm for a specific image is chosen by a convolutional neural network, trained with 25,000 images from the Skyfinder data set, reaching 82% accuracy with the top three classes. This selection step allows the sky marking to follow an adaptive process and to use different techniques and parameters to best suit a particular image. An evaluation of fourteen different techniques and parameter sets shows that no single technique can perform with high accuracy across varied Skyfinder and Google Street View data sets. However, by using our adaptive process, large increases in accuracy are observed. The resulting system is shown to perform better than other published techniques.