 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALARB: An Arabic Legal Argument Reasoning Benchmark
Oct 01, 2025We introduce ALARB, a dataset and suite of tasks designed to evaluate the reasoning capabilities of large language models (LLMs) within the Arabic legal domain. While existing Arabic benchmarks cover some knowledge-intensive tasks such as retrieval and understanding, substantial datasets focusing specifically on multistep reasoning for Arabic LLMs, especially in open-ended contexts, are lacking. The dataset comprises over 13K commercial court cases from Saudi Arabia, with each case including the facts presented, the reasoning of the court, the verdict, as well as the cited clauses extracted from the regulatory documents. We define a set of challenging tasks leveraging this dataset and reflecting the complexity of real-world legal reasoning, including verdict prediction, completion of reasoning chains in multistep legal arguments, and identification of relevant regulations based on case facts. We benchmark a representative selection of current open and closed Arabic LLMs on these tasks and demonstrate the dataset's utility for instruction tuning. Notably, we show that instruction-tuning a modest 12B parameter model using ALARB significantly enhances its performance in verdict prediction and Arabic verdict generation, reaching a level comparable to that of GPT-4o.
Cooperative Grasping for Collective Object Transport in Constrained Environments
Sep 03, 2025



We propose a novel framework for decision-making in cooperative grasping for two-robot object transport in constrained environments. The core of the framework is a Conditional Embedding (CE) model consisting of two neural networks that map grasp configuration information into an embedding space. The resulting embedding vectors are then used to identify feasible grasp configurations that allow two robots to collaboratively transport an object. To ensure generalizability across diverse environments and object geometries, the neural networks are trained on a dataset comprising a range of environment maps and object shapes. We employ a supervised learning approach with negative sampling to ensure that the learned embeddings effectively distinguish between feasible and infeasible grasp configurations. Evaluation results across a wide range of environments and objects in simulations demonstrate the model's ability to reliably identify feasible grasp configurations. We further validate the framework through experiments on a physical robotic platform, confirming its practical applicability.
Turning the Spell Around: Lightweight Alignment Amplification via Rank-One Safety Injection
Aug 28, 2025Safety alignment in Large Language Models (LLMs) often involves mediating internal representations to refuse harmful requests. Recent research has demonstrated that these safety mechanisms can be bypassed by ablating or removing specific representational directions within the model. In this paper, we propose the opposite approach: Rank-One Safety Injection (ROSI), a white-box method that amplifies a model's safety alignment by permanently steering its activations toward the refusal-mediating subspace. ROSI operates as a simple, fine-tuning-free rank-one weight modification applied to all residual stream write matrices. The required safety direction can be computed from a small set of harmful and harmless instruction pairs. We show that ROSI consistently increases safety refusal rates - as evaluated by Llama Guard 3 - while preserving the utility of the model on standard benchmarks such as MMLU, HellaSwag, and Arc. Furthermore, we show that ROSI can also re-align 'uncensored' models by amplifying their own latent safety directions, demonstrating its utility as an effective last-mile safety procedure. Our results suggest that targeted, interpretable weight steering is a cheap and potent mechanism to improve LLM safety, complementing more resource-intensive fine-tuning paradigms.
Synthetic Geology -- Structural Geology Meets Deep Learning
Jun 11, 2025

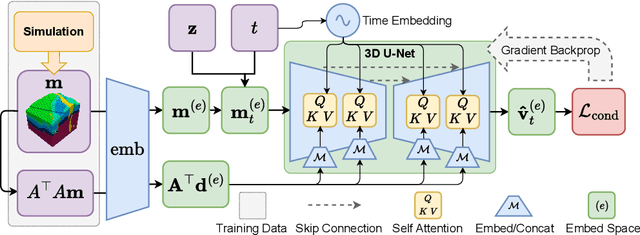
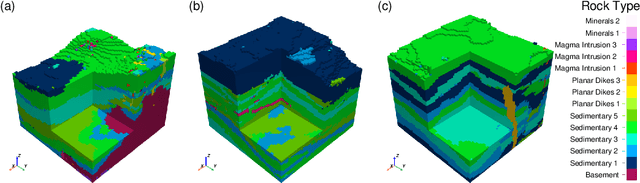
Visualizing the first few kilometers of the Earth's subsurface, a long-standing challenge gating a virtually inexhaustible list of important applications, is coming within reach through deep learning. Building on techniques of generative artificial intelligence applied to voxelated images, we demonstrate a method that extends surface geological data supplemented by boreholes to a three-dimensional subsurface region by training a neural network. The Earth's land area having been extensively mapped for geological features, the bottleneck of this or any related technique is the availability of data below the surface. We close this data gap in the development of subsurface deep learning by designing a synthetic data-generator process that mimics eons of geological activity such as sediment compaction, volcanic intrusion, and tectonic dynamics to produce a virtually limitless number of samples of the near lithosphere. A foundation model trained on such synthetic data is able to generate a 3D image of the subsurface from a previously unseen map of surface topography and geology, showing increasing fidelity with increasing access to borehole data, depicting such structures as layers, faults, folds, dikes, and sills. We illustrate the early promise of the combination of a synthetic lithospheric generator with a trained neural network model using generative flow matching. Ultimately, such models will be fine-tuned on data from applicable campaigns, such as mineral prospecting in a given region. Though useful in itself, a regionally fine-tuned models may be employed not as an end but as a means: as an AI-based regularizer in a more traditional inverse problem application, in which the objective function represents the mismatch of additional data with physical models with applications in resource exploration, hazard assessment, and geotechnical engineering.
An Embarrassingly Simple Defense Against LLM Abliteration Attacks
May 25, 2025Large language models (LLMs) are typically aligned to comply with safety guidelines by refusing harmful instructions. A recent attack, termed abliteration, isolates and suppresses the single latent direction most responsible for refusal behavior, enabling the model to generate unethical content. We propose a defense that modifies how models generate refusals. We construct an extended-refusal dataset that contains harmful prompts with a full response that justifies the reason for refusal. We then fine-tune Llama-2-7B-Chat and Qwen2.5-Instruct (1.5B and 3B parameters) on our extended-refusal dataset, and evaluate the resulting systems on a set of harmful prompts. In our experiments, extended-refusal models maintain high refusal rates, dropping at most by 10%, whereas baseline models' refusal rates drop by 70-80% after abliteration. A broad evaluation of safety and utility shows that extended-refusal fine-tuning neutralizes the abliteration attack while preserving general performance.
ArabLegalEval: A Multitask Benchmark for Assessing Arabic Legal Knowledge in Large Language Models
Aug 15, 2024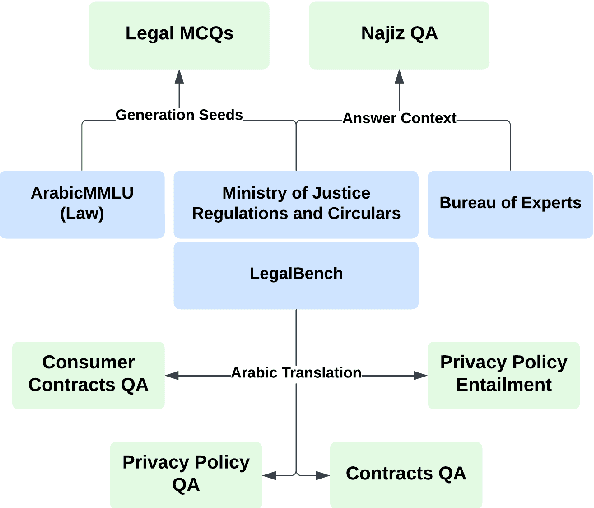

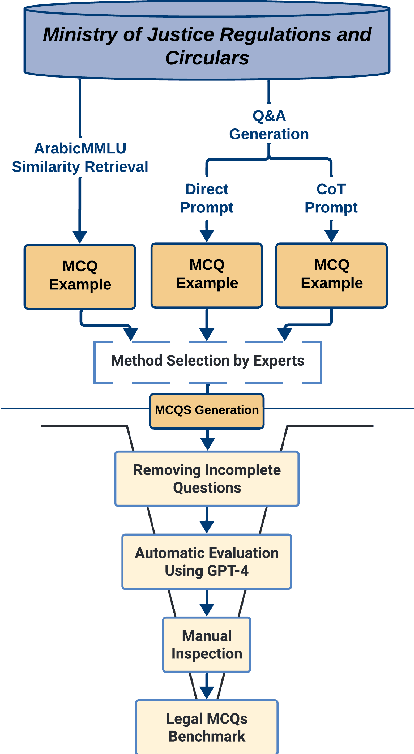

The rapid advancements in Large Language Models (LLMs) have led to significant improvements in various natural language processing tasks. However, the evaluation of LLMs' legal knowledge, particularly in non-English languages such as Arabic, remains under-explored. To address this gap, we introduce ArabLegalEval, a multitask benchmark dataset for assessing the Arabic legal knowledge of LLMs. Inspired by the MMLU and LegalBench datasets, ArabLegalEval consists of multiple tasks sourced from Saudi legal documents and synthesized questions. In this work, we aim to analyze the capabilities required to solve legal problems in Arabic and benchmark the performance of state-of-the-art LLMs. We explore the impact of in-context learning and investigate various evaluation methods. Additionally, we explore workflows for generating questions with automatic validation to enhance the dataset's quality. We benchmark multilingual and Arabic-centric LLMs, such as GPT-4 and Jais, respectively. We also share our methodology for creating the dataset and validation, which can be generalized to other domains. We hope to accelerate AI research in the Arabic Legal domain by releasing the ArabLegalEval dataset and code: https://github.com/Thiqah/ArabLegalEval
PETScML: Second-order solvers for training regression problems in Scientific Machine Learning
Mar 18, 2024In recent years, we have witnessed the emergence of scientific machine learning as a data-driven tool for the analysis, by means of deep-learning techniques, of data produced by computational science and engineering applications. At the core of these methods is the supervised training algorithm to learn the neural network realization, a highly non-convex optimization problem that is usually solved using stochastic gradient methods. However, distinct from deep-learning practice, scientific machine-learning training problems feature a much larger volume of smooth data and better characterizations of the empirical risk functions, which make them suited for conventional solvers for unconstrained optimization. We introduce a lightweight software framework built on top of the Portable and Extensible Toolkit for Scientific computation to bridge the gap between deep-learning software and conventional solvers for unconstrained minimization. We empirically demonstrate the superior efficacy of a trust region method based on the Gauss-Newton approximation of the Hessian in improving the generalization errors arising from regression tasks when learning surrogate models for a wide range of scientific machine-learning techniques and test cases. All the conventional second-order solvers tested, including L-BFGS and inexact Newton with line-search, compare favorably, either in terms of cost or accuracy, with the adaptive first-order methods used to validate the surrogate models.